 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Task and Path Planning for Heterogeneous Robotic Teams using Multi-Agent PPO
Apr 01, 2026Efficient robotic extraterrestrial exploration requires robots with diverse capabilities, ranging from scientific measurement tools to advanced locomotion. A robotic team enables the distribution of tasks over multiple specialized subsystems, each providing specific expertise to complete the mission. The central challenge lies in efficiently coordinating the team to maximize utilization and the extraction of scientific value. Classical planning algorithms scale poorly with problem size, leading to long planning cycles and high inference costs due to the combinatorial growth of possible robot-target allocations and possible trajectories. Learning-based methods are a viable alternative that move the scaling concern from runtime to training time, setting a critical step towards achieving real-time planning. In this work, we present a collaborative planning strategy based on Multi-Agent Proximal Policy Optimization (MAPPO) to coordinate a team of heterogeneous robots to solve a complex target allocation and scheduling problem. We benchmark our approach against single-objective optimal solutions obtained through exhaustive search and evaluate its ability to perform online replanning in the context of a planetary exploration scenario.
Human-State-Aware Controller for a Tethered Aerial Robot Guiding a Human by Physical Interaction
Mar 07, 2022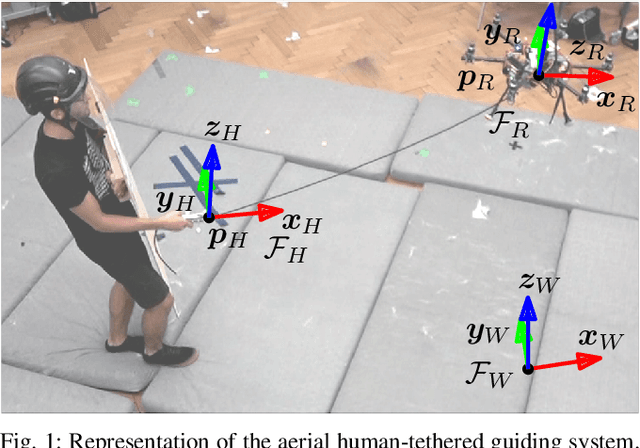
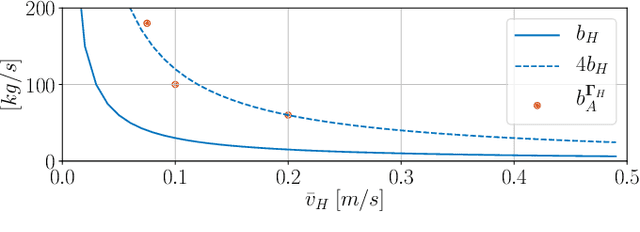
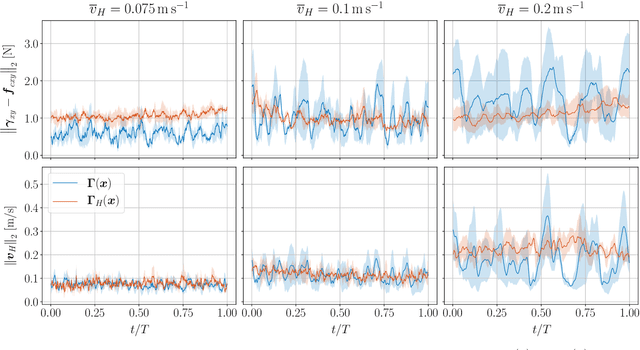
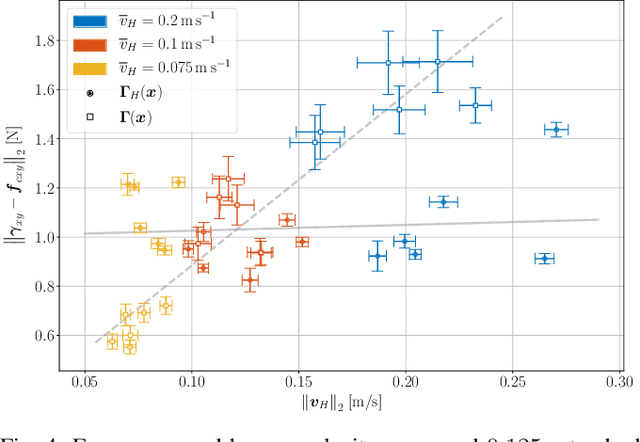
With the rapid development of Aerial Physical Interaction, the possibility to have aerial robots physically interacting with humans is attracting a growing interest. In one of our previous works, we considered one of the first systems in which a human is physically connected to an aerial vehicle by a cable. There, we developed a compliant controller that allows the robot to pull the human toward a desired position using forces only as an indirect communication-channel. However, this controller is based on the robot-state only, which makes the system not adaptable to the human behavior, and in particular to their walking speed. This reduces the effectiveness and comfort of the guidance when the human is still far from the desired point. In this paper, we formally analyze the problem and propose a human-state-aware controller that includes a human`s velocity feedback. We theoretically prove and experimentally show that this method provides a more consistent guiding force which enhances the guiding experience.