 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Duration Fully Autonomous Operation of Rotorcraft Unmanned Aerial Systems for Remote-Sensing Data Acquisition
Aug 18, 2019
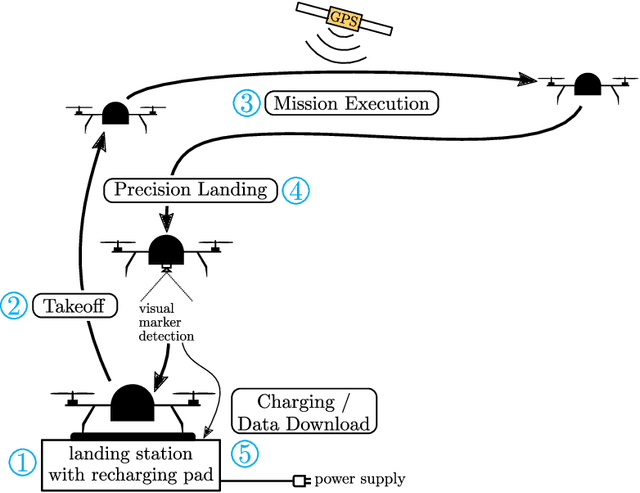

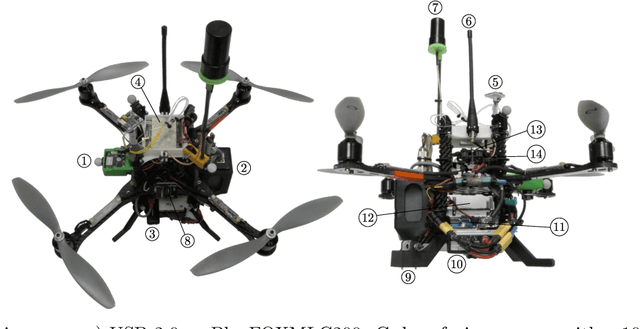
Recent applications of unmanned aerial systems (UAS) to precision agriculture have shown increased ease and efficiency in data collection at precise remote locations. However, further enhancement of the field requires operation over long periods of time, e.g. days or weeks. This has so far been impractical due to the limited flight times of such platforms and the requirement of humans in the loop for operation. To overcome these limitations, we propose a fully autonomous rotorcraft UAS that is capable of performing repeated flights for long-term observation missions without any human intervention. We address two key technologies that are critical for such a system: full platform autonomy to enable mission execution independently from human operators and the ability of vision-based precision landing on a recharging station for automated energy replenishment. High-level autonomous decision making is implemented as a hierarchy of master and slave state machines. Vision-based precision landing is enabled by estimating the landing pad's pose using a bundle of AprilTag fiducials configured for detection from a wide range of altitudes. We provide an extensive evaluation of the landing pad pose estimation accuracy as a function of the bundle's geometry. The functionality of the complete system is demonstrated through two indoor experiments with a duration of 11 and 10.6 hours, and one outdoor experiment with a duration of 4 hours. The UAS executed 16, 48 and 22 flights respectively during these experiments. In the outdoor experiment, the ratio between flying to collect data and charging was 1 to 10, which is similar to past work in this domain. All flights were fully autonomous with no human in the loop. To our best knowledge this is the first research publication about the long-term outdoor operation of a quadrotor system with no human interaction.
* 38 pages, 28 figures
Disturbance Estimation and Rejection for High-Precision Multirotor Position Control
Aug 08, 2019
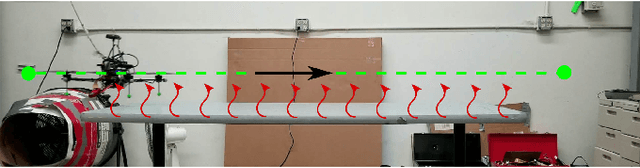
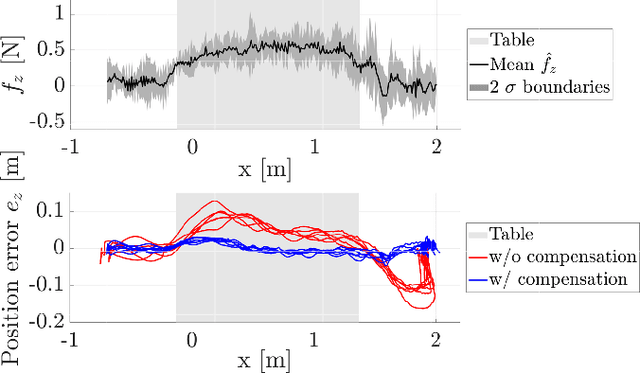
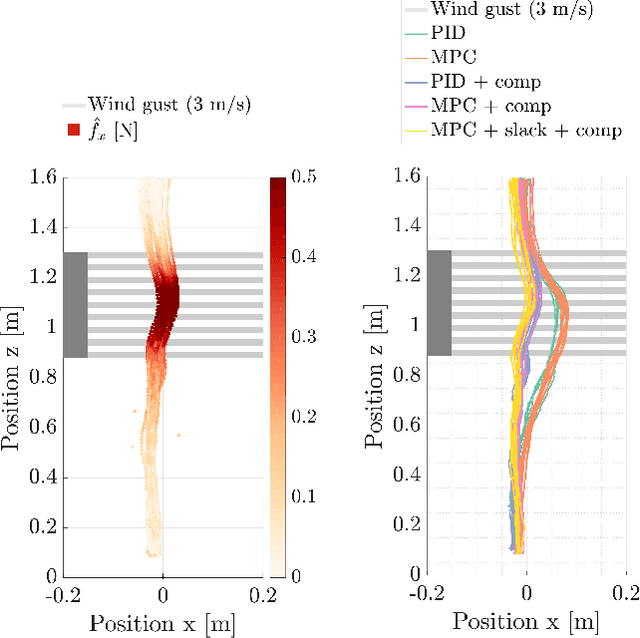
Many multirotor Unmanned Aerial Systems applications have a critical need for precise position control in environments with strong dynamic external disturbances such as wind gusts or ground and wall effects. Moreover, to maximize flight time, small multirotor platforms have to operate within strict constraints on payload and thus computational performance. In this paper, we present the design and experimental comparison of Model Predictive and PID multirotor position controllers augmented with a disturbance estimator to reject strong wind gusts up to 12 m/s and ground effect. For disturbance estimation, we compare Extended and Unscented Kalman filtering. In extensive in- and outdoor flight tests, we evaluate the suitability of the developed control and estimation algorithms to run on a computationally constrained platform. This allows to draw a conclusion on whether potential performance improvements justify the increased computational complexity of MPC for multirotor position control and UKF for disturbance estimation.
Free-Space Features: Global Localization in 2D Laser SLAM Using Distance Function Maps
Aug 05, 2019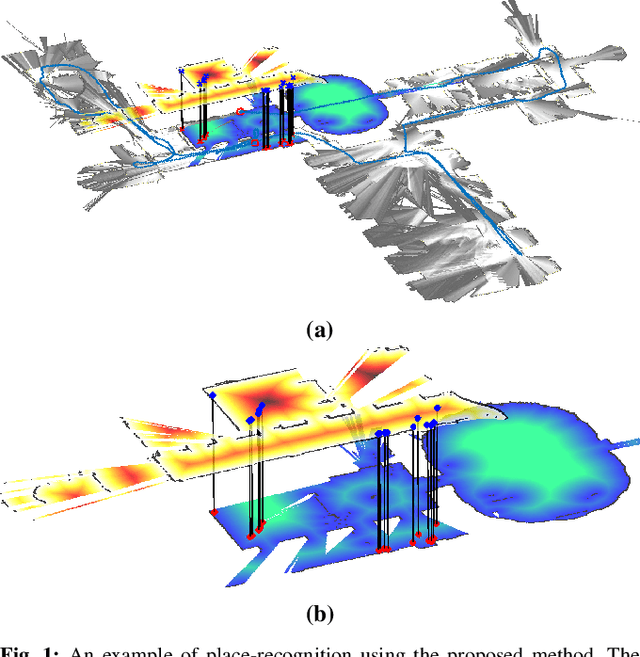

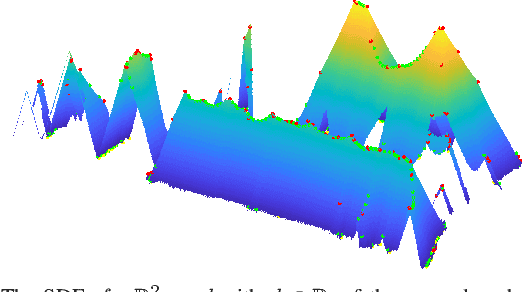
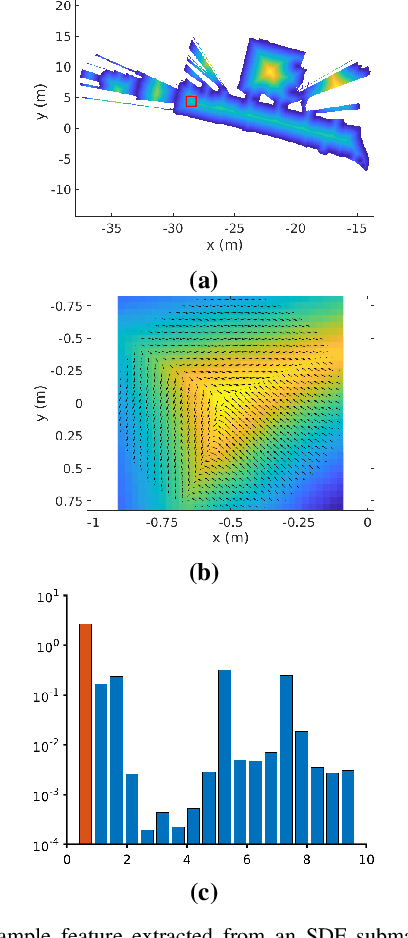
In many applications, maintaining a consistent map of the environment is key to enabling robotic platforms to perform higher-level decision making. Detection of already visited locations is one of the primary ways in which map consistency is maintained, especially in situations where external positioning systems are unavailable or unreliable. Mapping in 2D is an important field in robotics, largely due to the fact that man-made environments such as warehouses and homes, where robots are expected to play an increasing role, can often be approximated as planar. Place recognition in this context remains challenging: 2D lidar scans contain scant information with which to characterize, and therefore recognize, a location. This paper introduces a novel approach aimed at addressing this problem. At its core, the system relies on the use of the distance function for representation of geometry. This representation allows extraction of features which describe the geometry of both surfaces and free-space in the environment. We propose a feature for this purpose. Through evaluations on public datasets, we demonstrate the utility of free-space in the description of places, and show an increase in localization performance over a state-of-the-art descriptor extracted from surface geometry.
On Flying Backwards: Preventing Run-away of Small, Low-speed, Fixed-wing UAVs in Strong Winds
Aug 04, 2019
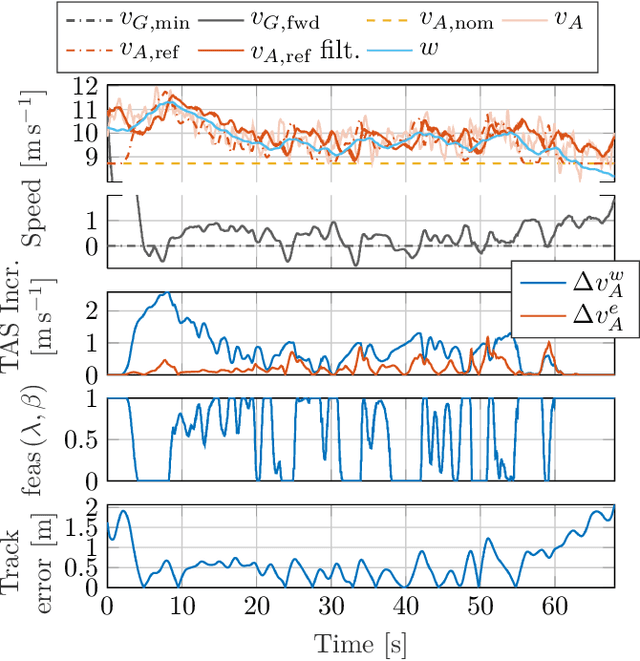

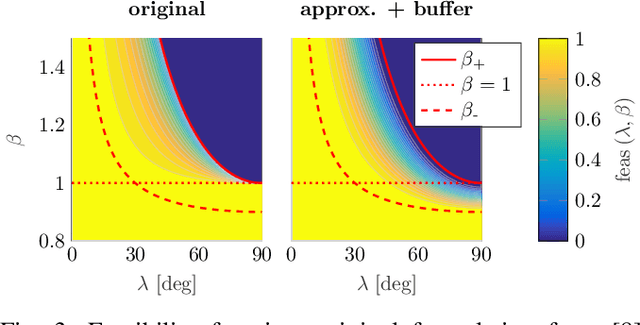
Small, low-speed fixed-wing Unmanned Aerial Vehicles (UAVs) operating autonomously, beyond-visual-line-of-sight (BVLOS) will inevitably encounter winds rising to levels near or exceeding the vehicles' nominal airspeed. In this paper, we develop a nonlinear lateral-directional path following guidance law with explicit consideration of online wind estimates. Energy efficient airspeed reference compensation logic is developed for excess wind scenarios (i.e. when the wind speed rises above the airspeed), enabling either mitigation, prevention, or over-powering of excess wind induced run-away from a given path. The developed guidance law is demonstrated on a representative small, low-speed test UAV in two flight experiments conducted in mountainous regions of Switzerland with strong, turbulent wind conditions, gusts reaching up to 13 meters per second. We demonstrate track-keeping errors of less than 1 meter consistently maintained during a representative duration of gusting, excess winds and a mean ground speed undershoot of 0.5 meters per second from the commanded minimum forward ground speed demonstrated in over 5 minutes of the showcased flight results.
Learning Densities in Feature Space for Reliable Segmentation of Indoor Scenes
Aug 01, 2019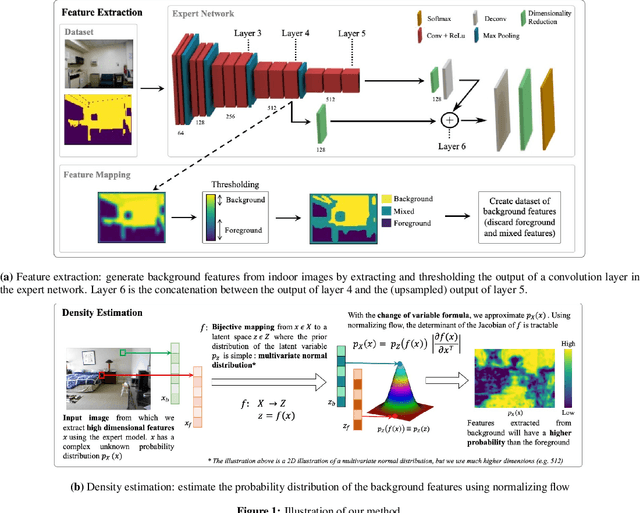
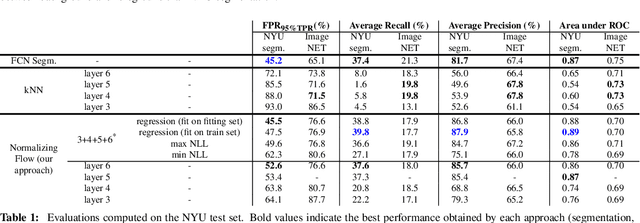


Deep learning has enabled remarkable advances in semantic segmentation and scene understanding. Yet, introducing novel elements, called out-of-distribution (OoD) data, decreases the performance of existing methods, which are usually limited to a fixed set of classes. This is a problem as autonomous agents will inevitably come across a wide range of objects, all of which cannot be included during training. We propose a novel method to distinguish any object (foreground) from empty building structure (background) in indoor environments. We use normalizing flow to estimate the probability distribution of high-dimensional background descriptors. Foreground objects are therefore detected as areas in an image for which the descriptors are unlikely given the background distribution. As our method does not explicitly learn the representation of individual objects, its performance generalizes well outside of the training examples. Our model results in an innovative solution to reliably segment foreground from background in indoor scenes, which opens the way to a safer deployment of robots in human environments.
Revisiting Boustrophedon Coverage Path Planning as a Generalized Traveling Salesman Problem
Jul 22, 2019
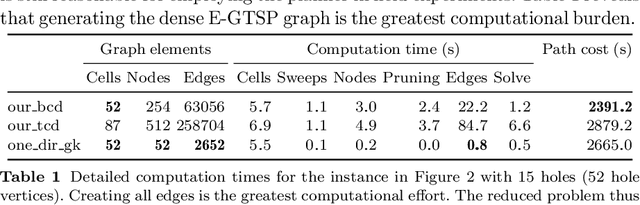
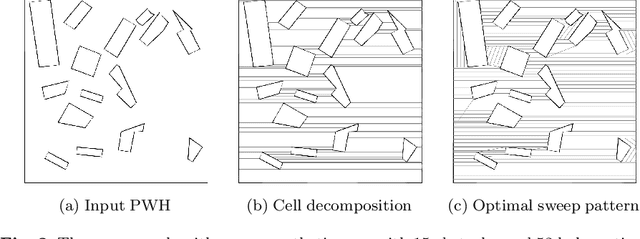

In this paper, we present a path planner for low-altitude terrain coverage in known environments with unmanned rotary-wing micro aerial vehicles (MAVs). Airborne systems can assist humanitarian demining by surveying suspected hazardous areas (SHAs) with cameras, ground-penetrating synthetic aperture radar (GPSAR), and metal detectors. Most available coverage planner implementations for MAVs do not consider obstacles and thus cannot be deployed in obstructed environments. We describe an open source framework to perform coverage planning in polygon flight corridors with obstacles. Our planner extends boustrophedon coverage planning by optimizing over different sweep combinations to find the optimal sweep path, and considers obstacles during transition flights between cells. We evaluate the path planner on 320 synthetic maps and show that it is able to solve realistic planning instances fast enough to run in the field. The planner achieves 14% lower path costs than a conventional coverage planner. We validate the planner on a real platform where we show low-altitude coverage over a sloped terrain with trees.
Large-scale, real-time visual-inertial localization revisited
Jun 30, 2019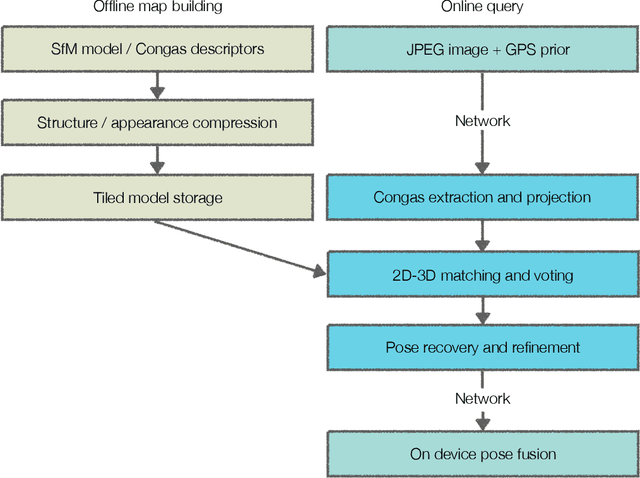

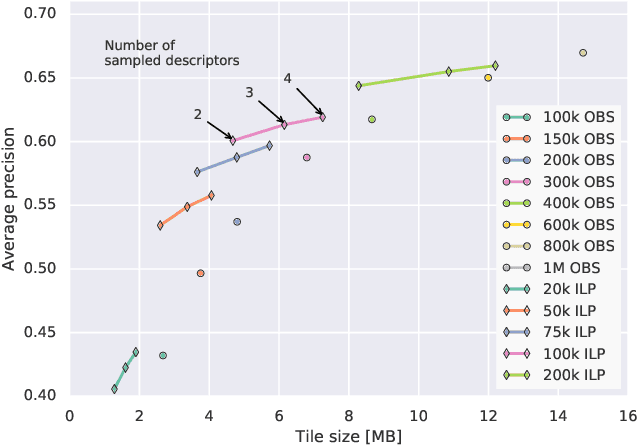
The overarching goals in image-based localization are scale, robustness and speed. In recent years, approaches based on local features and sparse 3D point-cloud models have both dominated the benchmarks and seen successful realworld deployment. They enable applications ranging from robot navigation, autonomous driving, virtual and augmented reality to device geo-localization. Recently end-to-end learned localization approaches have been proposed which show promising results on small scale datasets. However the positioning accuracy, scalability, latency and compute & storage requirements of these approaches remain open challenges. We aim to deploy localization at global-scale where one thus relies on methods using local features and sparse 3D models. Our approach spans from offline model building to real-time client-side pose fusion. The system compresses appearance and geometry of the scene for efficient model storage and lookup leading to scalability beyond what what has been previously demonstrated. It allows for low-latency localization queries and efficient fusion run in real-time on mobile platforms by combining server-side localization with real-time visual-inertial-based camera pose tracking. In order to further improve efficiency we leverage a combination of priors, nearest neighbor search, geometric match culling and a cascaded pose candidate refinement step. This combination outperforms previous approaches when working with large scale models and allows deployment at unprecedented scale. We demonstrate the effectiveness of our approach on a proof-of-concept system localizing 2.5 million images against models from four cities in different regions on the world achieving query latencies in the 200ms range.
3D Multi-Robot Patrolling with a Two-Level Coordination Strategy
Jun 23, 2019

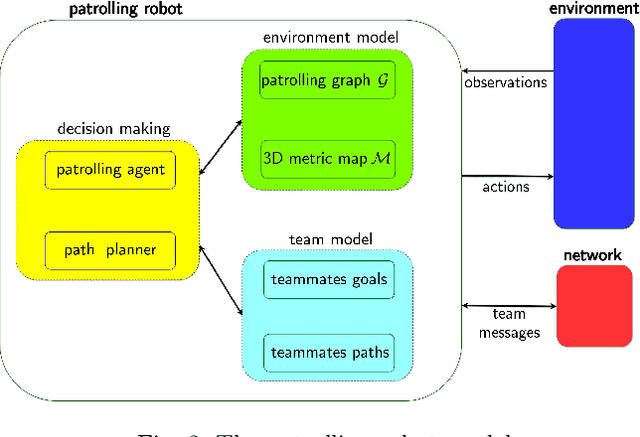
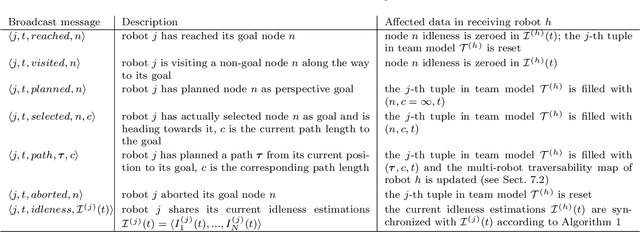
Teams of UGVs patrolling harsh and complex 3D environments can experience interference and spatial conflicts with one another. Neglecting the occurrence of these events crucially hinders both soundness and reliability of a patrolling process. This work presents a distributed multi-robot patrolling technique, which uses a two-level coordination strategy to minimize and explicitly manage the occurrence of conflicts and interference. The first level guides the agents to single out exclusive target nodes on a topological map. This target selection relies on a shared idleness representation and a coordination mechanism preventing topological conflicts. The second level hosts coordination strategies based on a metric representation of space and is supported by a 3D SLAM system. Here, each robot path planner negotiates spatial conflicts by applying a multi-robot traversability function. Continuous interactions between these two levels ensure coordination and conflicts resolution. Both simulations and real-world experiments are presented to validate the performances of the proposed patrolling strategy in 3D environments. Results show this is a promising solution for managing spatial conflicts and preventing deadlocks.
AMZ Driverless: The Full Autonomous Racing System
May 13, 2019



This paper presents the algorithms and system architecture of an autonomous racecar. The introduced vehicle is powered by a software stack designed for robustness, reliability, and extensibility. In order to autonomously race around a previously unknown track, the proposed solution combines state of the art techniques from different fields of robotics. Specifically, perception, estimation, and control are incorporated into one high-performance autonomous racecar. This complex robotic system, developed by AMZ Driverless and ETH Zurich, finished 1st overall at each competition we attended: Formula Student Germany 2017, Formula Student Italy 2018 and Formula Student Germany 2018. We discuss the findings and learnings from these competitions and present an experimental evaluation of each module of our solution.
The Fishyscapes Benchmark: Measuring Blind Spots in Semantic Segmentation
May 13, 2019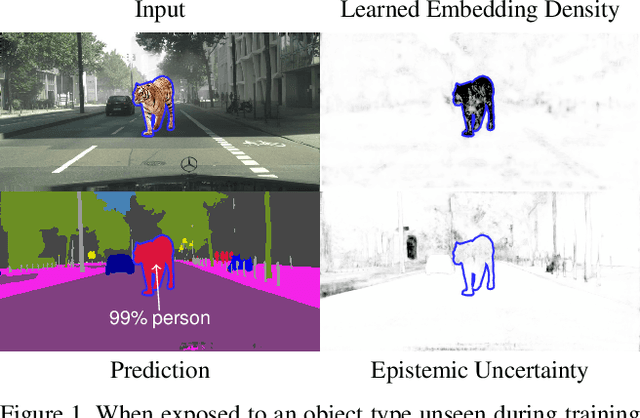
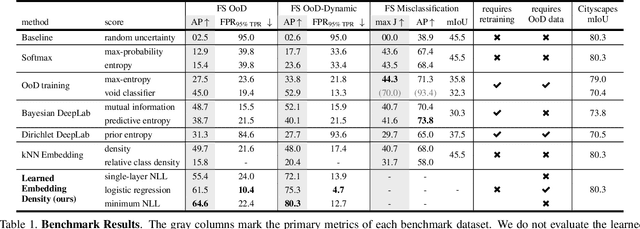
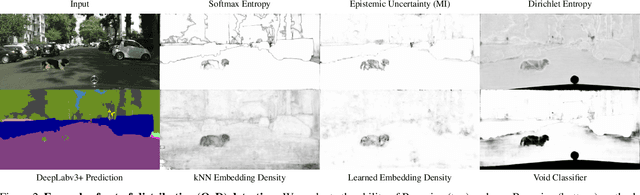

Deep learning has enabled impressive progress in the accuracy of semantic segmentation. Yet, the ability to estimate uncertainty and detect failure is key for safety-critical applications like autonomous driving. Existing uncertainty estimates have mostly been evaluated on simple tasks, and it is unclear whether these methods generalize to more complex scenarios. We present Fishyscapes, the first public benchmark for uncertainty estimation in a real-world task of semantic segmentation for urban driving. It evaluates pixel-wise uncertainty estimates and covers the detection of both out-of-distribution objects and misclassifications. We adapt state-of-the-art methods to recent semantic segmentation models and compare approaches based on softmax confidence, Bayesian learning, and embedding density. A thorough evaluation of these methods reveals a clear gap to their alleged capabilities. Our results show that failure detection is far from solved even for ordinary situations, while our benchmark allows measuring advancements beyond the state-of-the-art.