 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Joint Speech-Text Representations Without Alignment
Aug 11, 2023



The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023



In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.
A Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale
Apr 19, 2023



Unpaired text and audio injection have emerged as dominant methods for improving ASR performance in the absence of a large labeled corpus. However, little guidance exists on deploying these methods to improve production ASR systems that are trained on very large supervised corpora and with realistic requirements like a constrained model size and CPU budget, streaming capability, and a rich lattice for rescoring and for downstream NLU tasks. In this work, we compare three state-of-the-art semi-supervised methods encompassing both unpaired text and audio as well as several of their combinations in a controlled setting using joint training. We find that in our setting these methods offer many improvements beyond raw WER, including substantial gains in tail-word WER, decoder computation during inference, and lattice density.
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
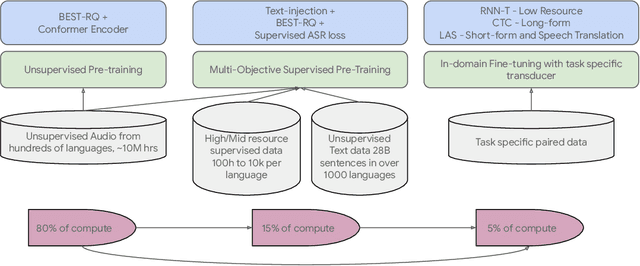
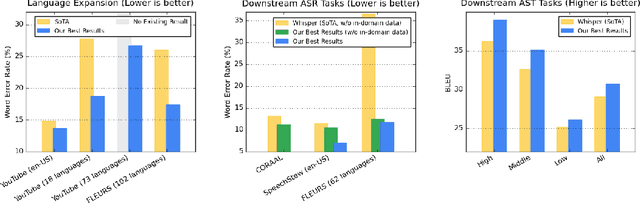

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
End-to-End Speech Recognition: A Survey
Mar 03, 2023



In the last decade of automatic speech recognition (ASR) research, the introduction of deep learning brought considerable reductions in word error rate of more than 50% relative, compared to modeling without deep learning. In the wake of this transition, a number of all-neural ASR architectures were introduced. These so-called end-to-end (E2E) models provide highly integrated, completely neural ASR models, which rely strongly on general machine learning knowledge, learn more consistently from data, while depending less on ASR domain-specific experience. The success and enthusiastic adoption of deep learning accompanied by more generic model architectures lead to E2E models now becoming the prominent ASR approach. The goal of this survey is to provide a taxonomy of E2E ASR models and corresponding improvements, and to discuss their properties and their relation to the classical hidden Markov model (HMM) based ASR architecture. All relevant aspects of E2E ASR are covered in this work: modeling, training, decoding, and external language model integration, accompanied by discussions of performance and deployment opportunities, as well as an outlook into potential future developments.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023



We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023



In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
Dual Learning for Large Vocabulary On-Device ASR
Jan 11, 2023



Dual learning is a paradigm for semi-supervised machine learning that seeks to leverage unsupervised data by solving two opposite tasks at once. In this scheme, each model is used to generate pseudo-labels for unlabeled examples that are used to train the other model. Dual learning has seen some use in speech processing by pairing ASR and TTS as dual tasks. However, these results mostly address only the case of using unpaired examples to compensate for very small supervised datasets, and mostly on large, non-streaming models. Dual learning has not yet been proven effective for using unsupervised data to improve realistic on-device streaming models that are already trained on large supervised corpora. We provide this missing piece though an analysis of an on-device-sized streaming conformer trained on the entirety of Librispeech, showing relative WER improvements of 10.7%/5.2% without an LM and 11.7%/16.4% with an LM.