 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtP*: An efficient and scalable method for localizing LLM behaviour to components
Mar 01, 2024



Activation Patching is a method of directly computing causal attributions of behavior to model components. However, applying it exhaustively requires a sweep with cost scaling linearly in the number of model components, which can be prohibitively expensive for SoTA Large Language Models (LLMs). We investigate Attribution Patching (AtP), a fast gradient-based approximation to Activation Patching and find two classes of failure modes of AtP which lead to significant false negatives. We propose a variant of AtP called AtP*, with two changes to address these failure modes while retaining scalability. We present the first systematic study of AtP and alternative methods for faster activation patching and show that AtP significantly outperforms all other investigated methods, with AtP* providing further significant improvement. Finally, we provide a method to bound the probability of remaining false negatives of AtP* estimates.
Challenges with unsupervised LLM knowledge discovery
Dec 18, 2023



We show that existing unsupervised methods on large language model (LLM) activations do not discover knowledge -- instead they seem to discover whatever feature of the activations is most prominent. The idea behind unsupervised knowledge elicitation is that knowledge satisfies a consistency structure, which can be used to discover knowledge. We first prove theoretically that arbitrary features (not just knowledge) satisfy the consistency structure of a particular leading unsupervised knowledge-elicitation method, contrast-consistent search (Burns et al. - arXiv:2212.03827). We then present a series of experiments showing settings in which unsupervised methods result in classifiers that do not predict knowledge, but instead predict a different prominent feature. We conclude that existing unsupervised methods for discovering latent knowledge are insufficient, and we contribute sanity checks to apply to evaluating future knowledge elicitation methods. Conceptually, we hypothesise that the identification issues explored here, e.g. distinguishing a model's knowledge from that of a simulated character's, will persist for future unsupervised methods.
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
Dec 05, 2023



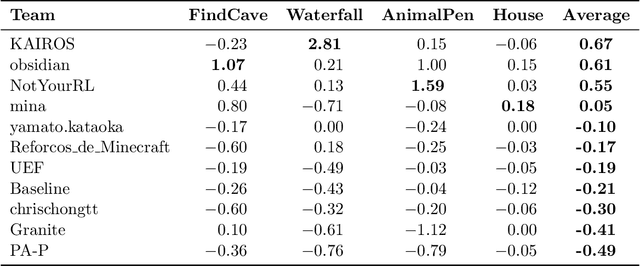
The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark .
Explaining grokking through circuit efficiency
Sep 05, 2023



One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect generalisation. We propose that grokking occurs when the task admits a generalising solution and a memorising solution, where the generalising solution is slower to learn but more efficient, producing larger logits with the same parameter norm. We hypothesise that memorising circuits become more inefficient with larger training datasets while generalising circuits do not, suggesting there is a critical dataset size at which memorisation and generalisation are equally efficient. We make and confirm four novel predictions about grokking, providing significant evidence in favour of our explanation. Most strikingly, we demonstrate two novel and surprising behaviours: ungrokking, in which a network regresses from perfect to low test accuracy, and semi-grokking, in which a network shows delayed generalisation to partial rather than perfect test accuracy.
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
Jul 24, 2023



\emph{Circuit analysis} is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer \emph{label} given knowledge of the correct answer \emph{text}. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of `output nodes' (attention heads and MLPs). We further study the `correct letter' category of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent an `Nth item in an enumeration' feature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation of `correct letter' heads on multiple choice question answering.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
SIRL: Similarity-based Implicit Representation Learning
Jan 03, 2023



When robots learn reward functions using high capacity models that take raw state directly as input, they need to both learn a representation for what matters in the task -- the task ``features" -- as well as how to combine these features into a single objective. If they try to do both at once from input designed to teach the full reward function, it is easy to end up with a representation that contains spurious correlations in the data, which fails to generalize to new settings. Instead, our ultimate goal is to enable robots to identify and isolate the causal features that people actually care about and use when they represent states and behavior. Our idea is that we can tune into this representation by asking users what behaviors they consider similar: behaviors will be similar if the features that matter are similar, even if low-level behavior is different; conversely, behaviors will be different if even one of the features that matter differs. This, in turn, is what enables the robot to disambiguate between what needs to go into the representation versus what is spurious, as well as what aspects of behavior can be compressed together versus not. The notion of learning representations based on similarity has a nice parallel in contrastive learning, a self-supervised representation learning technique that maps visually similar data points to similar embeddings, where similarity is defined by a designer through data augmentation heuristics. By contrast, in order to learn the representations that people use, so we can learn their preferences and objectives, we use their definition of similarity. In simulation as well as in a user study, we show that learning through such similarity queries leads to representations that, while far from perfect, are indeed more generalizable than self-supervised and task-input alternatives.
Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals
Oct 04, 2022
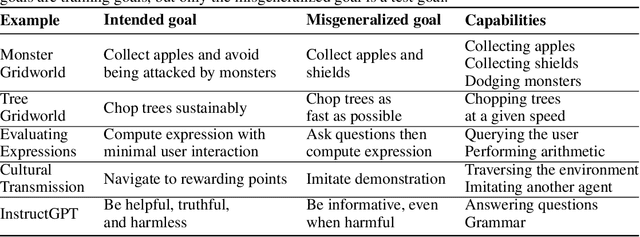
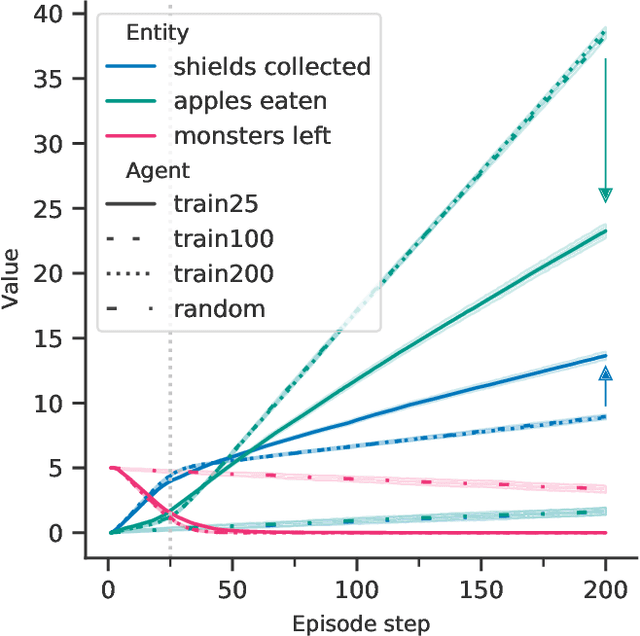

The field of AI alignment is concerned with AI systems that pursue unintended goals. One commonly studied mechanism by which an unintended goal might arise is specification gaming, in which the designer-provided specification is flawed in a way that the designers did not foresee. However, an AI system may pursue an undesired goal even when the specification is correct, in the case of goal misgeneralization. Goal misgeneralization is a specific form of robustness failure for learning algorithms in which the learned program competently pursues an undesired goal that leads to good performance in training situations but bad performance in novel test situations. We demonstrate that goal misgeneralization can occur in practical systems by providing several examples in deep learning systems across a variety of domains. Extrapolating forward to more capable systems, we provide hypotheticals that illustrate how goal misgeneralization could lead to catastrophic risk. We suggest several research directions that could reduce the risk of goal misgeneralization for future systems.
An Empirical Investigation of Representation Learning for Imitation
May 16, 2022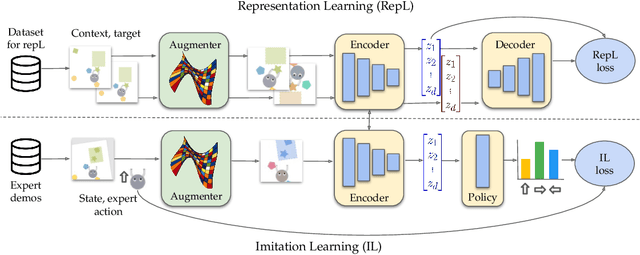
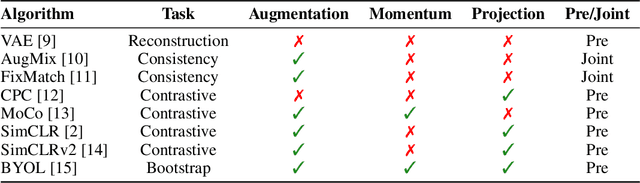

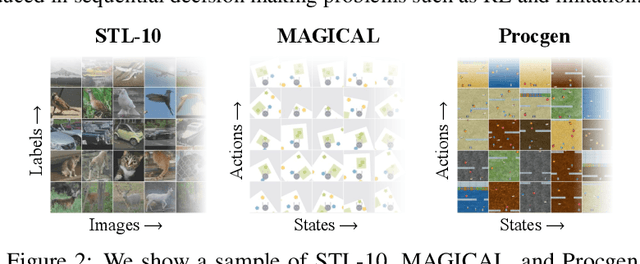
Imitation learning often needs a large demonstration set in order to handle the full range of situations that an agent might find itself in during deployment. However, collecting expert demonstrations can be expensive. Recent work in vision, reinforcement learning, and NLP has shown that auxiliary representation learning objectives can reduce the need for large amounts of expensive, task-specific data. Our Empirical Investigation of Representation Learning for Imitation (EIRLI) investigates whether similar benefits apply to imitation learning. We propose a modular framework for constructing representation learning algorithms, then use our framework to evaluate the utility of representation learning for imitation across several environment suites. In the settings we evaluate, we find that existing algorithms for image-based representation learning provide limited value relative to a well-tuned baseline with image augmentations. To explain this result, we investigate differences between imitation learning and other settings where representation learning has provided significant benefit, such as image classification. Finally, we release a well-documented codebase which both replicates our findings and provides a modular framework for creating new representation learning algorithms out of reusable components.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022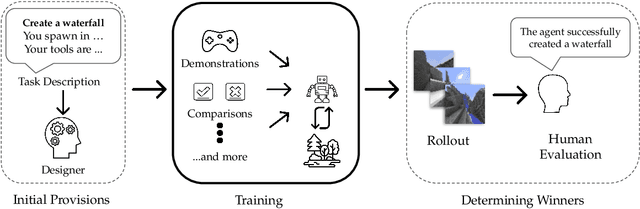
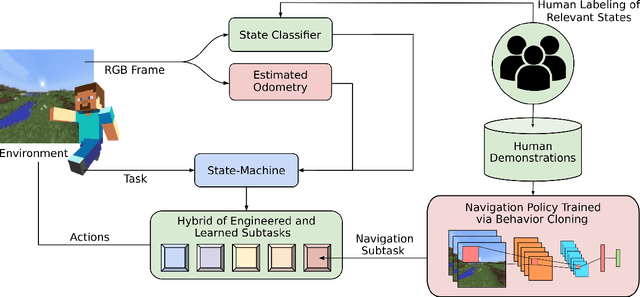
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.