 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETQUS: Decomposition-Enhanced Transformers for QUery-focused Summarization
Mar 07, 2025



Query-focused tabular summarization is an emerging task in table-to-text generation that synthesizes a summary response from tabular data based on user queries. Traditional transformer-based approaches face challenges due to token limitations and the complexity of reasoning over large tables. To address these challenges, we introduce DETQUS (Decomposition-Enhanced Transformers for QUery-focused Summarization), a system designed to improve summarization accuracy by leveraging tabular decomposition alongside a fine-tuned encoder-decoder model. DETQUS employs a large language model to selectively reduce table size, retaining only query-relevant columns while preserving essential information. This strategy enables more efficient processing of large tables and enhances summary quality. Our approach, equipped with table-based QA model Omnitab, achieves a ROUGE-L score of 0.4437, outperforming the previous state-of-the-art REFACTOR model (ROUGE-L: 0.422). These results highlight DETQUS as a scalable and effective solution for query-focused tabular summarization, offering a structured alternative to more complex architectures.
Seismic inversion using hybrid quantum neural networks
Mar 06, 2025



Quantum computing leverages qubits, exploiting superposition and entanglement to solve problems intractable for classical computers, offering significant computational advantages. Quantum machine learning (QML), which integrates quantum computing with machine learning, holds immense potential across various fields but remains largely unexplored in geosciences. However, its progress is hindered by the limitations of current NISQ hardware. To address these challenges, hybrid quantum neural networks (HQNNs) have emerged, combining quantum layers within classical neural networks to leverage the strengths of both paradigms. To the best of our knowledge, this study presents the first application of QML to subsurface imaging through the development of hybrid quantum physics-informed neural networks (HQ-PINNs) for seismic inversion. We apply the HQ-PINN framework to invert pre-stack and post-stack seismic datasets, estimating P- and S-impedances. The proposed HQ-PINN architecture follows an encoder-decoder structure, where the encoder (HQNN), processes seismic data to estimate elastic parameters, while the decoder utilizes these parameters to generate the corresponding seismic data based on geophysical relationships. The HQ-PINN model is trained by minimizing the misfit between the input and predicted seismic data generated by the decoder. We systematically evaluate various quantum layer configurations, differentiation methods, and quantum device simulators on the inversion performance, and demonstrate real-world applicability through the individual and simultaneous inversion cases of the Sleipner dataset. The HQ-PINN framework consistently and efficiently estimated accurate subsurface impedances across the synthetic and field case studies, establishing the feasibility of leveraging QML for seismic inversion, thereby paving the way for broader applications of quantum computing in geosciences.
Enhancing Diffusion Posterior Sampling for Inverse Problems by Integrating Crafted Measurements
Nov 15, 2024



Diffusion models have emerged as a powerful foundation model for visual generation. With an appropriate sampling process, it can effectively serve as a generative prior to solve general inverse problems. Current posterior sampling based methods take the measurement (i.e., degraded image sample) into the posterior sampling to infer the distribution of the target data (i.e., clean image sample). However, in this manner, we show that high-frequency information can be prematurely introduced during the early stages, which could induce larger posterior estimate errors during the restoration sampling. To address this issue, we first reveal that forming the log posterior gradient with the noisy measurement ( i.e., samples from a diffusion forward process) instead of the clean one can benefit the reverse process. Consequently, we propose a novel diffusion posterior sampling method DPS-CM, which incorporates a Crafted Measurement (i.e., samples generated by a reverse denoising process, compared to random sampling with noise in standard methods) to form the posterior estimate. This integration aims to mitigate the misalignment with the diffusion prior caused by cumulative posterior estimate errors. Experimental results demonstrate that our approach significantly improves the overall capacity to solve general and noisy inverse problems, such as Gaussian deblurring, super-resolution, inpainting, nonlinear deblurring, and tasks with Poisson noise, relative to existing approaches.
Real-Time Weapon Detection Using YOLOv8 for Enhanced Safety
Oct 23, 2024



This research paper presents the development of an AI model utilizing YOLOv8 for real-time weapon detection, aimed at enhancing safety in public spaces such as schools, airports, and public transportation systems. As incidents of violence continue to rise globally, there is an urgent need for effective surveillance technologies that can quickly identify potential threats. Our approach focuses on leveraging advanced deep learning techniques to create a highly accurate and efficient system capable of detecting weapons in real-time video streams. The model was trained on a comprehensive dataset containing thousands of images depicting various types of firearms and edged weapons, ensuring a robust learning process. We evaluated the model's performance using key metrics such as precision, recall, F1-score, and mean Average Precision (mAP) across multiple Intersection over Union (IoU) thresholds, revealing a significant capability to differentiate between weapon and non-weapon classes with minimal error. Furthermore, we assessed the system's operational efficiency, demonstrating that it can process frames at high speeds suitable for real-time applications. The findings indicate that our YOLOv8-based weapon detection model not only contributes to the existing body of knowledge in computer vision but also addresses critical societal needs for improved safety measures in vulnerable environments. By harnessing the power of artificial intelligence, this research lays the groundwork for developing practical solutions that can be deployed in security settings, ultimately enhancing the protective capabilities of law enforcement and public safety agencies.
Craft: Cross-modal Aligned Features Improve Robustness of Prompt Tuning
Jul 24, 2024



Prompt Tuning has emerged as a prominent research paradigm for adapting vision-language models to various downstream tasks. However, recent research indicates that prompt tuning methods often lead to overfitting due to limited training samples. In this paper, we propose a Cross-modal Aligned Feature Tuning (Craft) method to address this issue. Cross-modal alignment is conducted by first selecting anchors from the alternative domain and deriving relative representations of the embeddings for the selected anchors. Optimizing for a feature alignment loss over anchor-aligned text and image modalities creates a more unified text-image common space. Overfitting in prompt tuning also deteriorates model performance on out-of-distribution samples. To further improve the prompt model's robustness, we propose minimizing Maximum Mean Discrepancy (MMD) over the anchor-aligned feature spaces to mitigate domain shift. The experiment on four different prompt tuning structures consistently shows the improvement of our method, with increases of up to $6.1\%$ in the Base-to-Novel generalization task, $5.8\%$ in the group robustness task, and $2.7\%$ in the out-of-distribution tasks. The code will be available at https://github.com/Jingchensun/Craft
Discriminative Adversarial Unlearning
Feb 13, 2024



We introduce a novel machine unlearning framework founded upon the established principles of the min-max optimization paradigm. We capitalize on the capabilities of strong Membership Inference Attacks (MIA) to facilitate the unlearning of specific samples from a trained model. We consider the scenario of two networks, the attacker $\mathbf{A}$ and the trained defender $\mathbf{D}$ pitted against each other in an adversarial objective, wherein the attacker aims at teasing out the information of the data to be unlearned in order to infer membership, and the defender unlearns to defend the network against the attack, whilst preserving its general performance. The algorithm can be trained end-to-end using backpropagation, following the well known iterative min-max approach in updating the attacker and the defender. We additionally incorporate a self-supervised objective effectively addressing the feature space discrepancies between the forget set and the validation set, enhancing unlearning performance. Our proposed algorithm closely approximates the ideal benchmark of retraining from scratch for both random sample forgetting and class-wise forgetting schemes on standard machine-unlearning datasets. Specifically, on the class unlearning scheme, the method demonstrates near-optimal performance and comprehensively overcomes known methods over the random sample forgetting scheme across all metrics and multiple network pruning strategies.
DispersioNET: Joint Inversion of Rayleigh-Wave Multimode Phase Velocity Dispersion Curves using Convolutional Neural Networks
Oct 21, 2023



Rayleigh wave dispersion curves have been widely used in near-surface studies, and are primarily inverted for the shear wave (S-wave) velocity profiles. However, the inverse problem is ill-posed, non-unique and nonlinear. Here, we introduce DispersioNET, a deep learning model based on convolution neural networks (CNN) to perform the joint inversion of Rayleigh wave fundamental and higher order mode phase velocity dispersion curves. DispersioNET is trained and tested on both noise-free and noisy dispersion curve datasets and predicts S-wave velocity profiles that match closely with the true velocities. The architecture is agnostic to variations in S-wave velocity profiles such as increasing velocity with depth and intermediate low-velocity layers, while also ensuring that the output remains independent of the number of layers.
Label-Retrieval-Augmented Diffusion Models for Learning from Noisy Labels
May 31, 2023



Learning from noisy labels is an important and long-standing problem in machine learning for real applications. One of the main research lines focuses on learning a label corrector to purify potential noisy labels. However, these methods typically rely on strict assumptions and are limited to certain types of label noise. In this paper, we reformulate the label-noise problem from a generative-model perspective, $\textit{i.e.}$, labels are generated by gradually refining an initial random guess. This new perspective immediately enables existing powerful diffusion models to seamlessly learn the stochastic generative process. Once the generative uncertainty is modeled, we can perform classification inference using maximum likelihood estimation of labels. To mitigate the impact of noisy labels, we propose the $\textbf{L}$abel-$\textbf{R}$etrieval-$\textbf{A}$ugmented (LRA) diffusion model, which leverages neighbor consistency to effectively construct pseudo-clean labels for diffusion training. Our model is flexible and general, allowing easy incorporation of different types of conditional information, $\textit{e.g.}$, use of pre-trained models, to further boost model performance. Extensive experiments are conducted for evaluation. Our model achieves new state-of-the-art (SOTA) results on all the standard real-world benchmark datasets. Remarkably, by incorporating conditional information from the powerful CLIP model, our method can boost the current SOTA accuracy by 10-20 absolute points in many cases.
Clarinet: A Music Retrieval System
Oct 23, 2022



A MIDI based approach for music recognition is proposed and implemented in this paper. Our Clarinet music retrieval system is designed to search piano MIDI files with high recall and speed. We design a novel melody extraction algorithm that improves recall results by more than 10%. We also implement 3 algorithms for retrieval-two self designed (RSA Note and RSA Time), and a modified version of the Mongeau Sankoff Algorithm. Algorithms to achieve tempo and scale invariance are also discussed in this paper. The paper also contains detailed experimentation and benchmarks with four different metrics. Clarinet achieves recall scores of more than 94%.
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020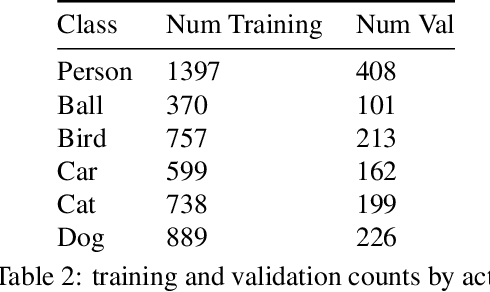
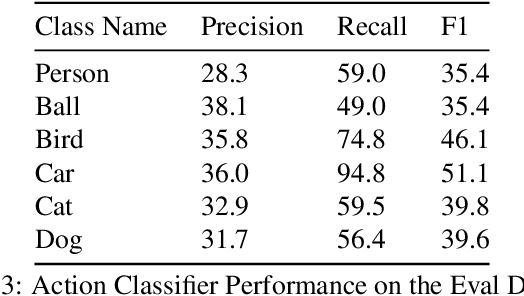
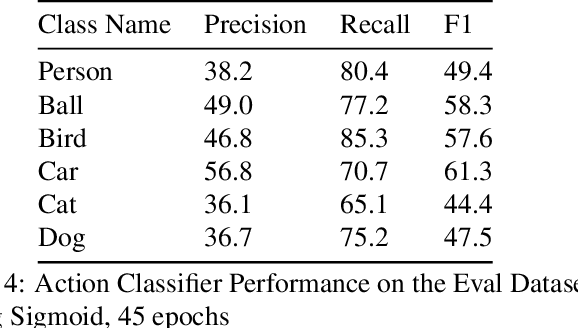
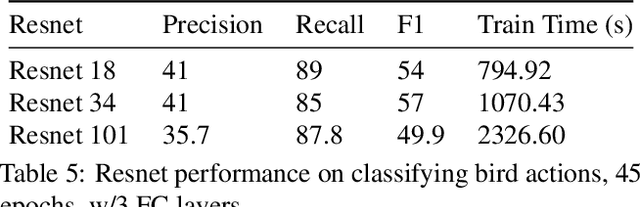
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester