 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHOY! Animatable Humans under Occlusion from YouTube Videos with Gaussian Splatting and Video Diffusion Priors
Mar 18, 2026We present AHOY, a method for reconstructing complete, animatable 3D Gaussian avatars from in-the-wild monocular video despite heavy occlusion. Existing methods assume unoccluded input-a fully visible subject, often in a canonical pose-excluding the vast majority of real-world footage where people are routinely occluded by furniture, objects, or other people. Reconstructing from such footage poses fundamental challenges: large body regions may never be observed, and multi-view supervision per pose is unavailable. We address these challenges with four contributions: (i) a hallucination-as-supervision pipeline that uses identity-finetuned diffusion models to generate dense supervision for previously unobserved body regions; (ii) a two-stage canonical-to-pose-dependent architecture that bootstraps from sparse observations to full pose-dependent Gaussian maps; (iii) a map-pose/LBS-pose decoupling that absorbs multi-view inconsistencies from the generated data; (iv) a head/body split supervision strategy that preserves facial identity. We evaluate on YouTube videos and on multi-view capture data with significant occlusion and demonstrate state-of-the-art reconstruction quality. We also demonstrate that the resulting avatars are robust enough to be animated with novel poses and composited into 3DGS scenes captured using cell-phone video. Our project page is available at https://miraymen.github.io/ahoy/
Animated 3DGS Avatars in Diverse Scenes with Consistent Lighting and Shadows
Jan 04, 2026We present a method for consistent lighting and shadows when animated 3D Gaussian Splatting (3DGS) avatars interact with 3DGS scenes or with dynamic objects inserted into otherwise static scenes. Our key contribution is Deep Gaussian Shadow Maps (DGSM), a modern analogue of the classical shadow mapping algorithm tailored to the volumetric 3DGS representation. Building on the classic deep shadow mapping idea, we show that 3DGS admits closed form light accumulation along light rays, enabling volumetric shadow computation without meshing. For each estimated light, we tabulate transmittance over concentric radial shells and store them in octahedral atlases, which modern GPUs can sample in real time per query to attenuate affected scene Gaussians and thus cast and receive shadows consistently. To relight moving avatars, we approximate the local environment illumination with HDRI probes represented in a spherical harmonic (SH) basis and apply a fast per Gaussian radiance transfer, avoiding explicit BRDF estimation or offline optimization. We demonstrate environment consistent lighting for avatars from AvatarX and ActorsHQ, composited into ScanNet++, DL3DV, and SuperSplat scenes, and show interactions with inserted objects. Across single and multi avatar settings, DGSM and SH relighting operate fully in the volumetric 3DGS representation, yielding coherent shadows and relighting while avoiding meshing.
Omni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting
Nov 13, 2025We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS), a neural scene representation that has recently achieved state-of-the-art photorealistic results for novel-view synthesis but remains under-explored for human-scene animation and interaction. Unlike existing animation pipelines that use meshes or point clouds as the underlying 3D representation, our approach introduces the use of 3DGS as the 3D representation to the problem of animating humans in scenes. By representing humans and scenes as Gaussians, our approach allows for geometry-consistent free-viewpoint rendering of humans interacting with 3D scenes. Our key insight is that the rendering can be decoupled from the motion synthesis and each sub-problem can be addressed independently, without the need for paired human-scene data. Central to our method is a Gaussian-aligned motion module that synthesizes motion without explicit scene geometry, using opacity-based cues and projected Gaussian structures to guide human placement and pose alignment. To ensure natural interactions, we further propose a human-scene Gaussian refinement optimization that enforces realistic contact and navigation. We evaluate our approach on scenes from Scannet++ and the SuperSplat library, and on avatars reconstructed from sparse and dense multi-view human capture. Finally, we demonstrate that our framework allows for novel applications such as geometry-consistent free-viewpoint rendering of edited monocular RGB videos with new animated humans, showcasing the unique advantage of 3DGS for monocular video-based human animation.
SPAD : Spatially Aware Multiview Diffusers
Feb 07, 2024



We present SPAD, a novel approach for creating consistent multi-view images from text prompts or single images. To enable multi-view generation, we repurpose a pretrained 2D diffusion model by extending its self-attention layers with cross-view interactions, and fine-tune it on a high quality subset of Objaverse. We find that a naive extension of the self-attention proposed in prior work (e.g. MVDream) leads to content copying between views. Therefore, we explicitly constrain the cross-view attention based on epipolar geometry. To further enhance 3D consistency, we utilize Plucker coordinates derived from camera rays and inject them as positional encoding. This enables SPAD to reason over spatial proximity in 3D well. In contrast to recent works that can only generate views at fixed azimuth and elevation, SPAD offers full camera control and achieves state-of-the-art results in novel view synthesis on unseen objects from the Objaverse and Google Scanned Objects datasets. Finally, we demonstrate that text-to-3D generation using SPAD prevents the multi-face Janus issue. See more details at our webpage: https://yashkant.github.io/spad
iNVS: Repurposing Diffusion Inpainters for Novel View Synthesis
Oct 24, 2023



We present a method for generating consistent novel views from a single source image. Our approach focuses on maximizing the reuse of visible pixels from the source image. To achieve this, we use a monocular depth estimator that transfers visible pixels from the source view to the target view. Starting from a pre-trained 2D inpainting diffusion model, we train our method on the large-scale Objaverse dataset to learn 3D object priors. While training we use a novel masking mechanism based on epipolar lines to further improve the quality of our approach. This allows our framework to perform zero-shot novel view synthesis on a variety of objects. We evaluate the zero-shot abilities of our framework on three challenging datasets: Google Scanned Objects, Ray Traced Multiview, and Common Objects in 3D. See our webpage for more details: https://yashkant.github.io/invs/
Invertible Neural Skinning
Feb 18, 2023



Building animatable and editable models of clothed humans from raw 3D scans and poses is a challenging problem. Existing reposing methods suffer from the limited expressiveness of Linear Blend Skinning (LBS), require costly mesh extraction to generate each new pose, and typically do not preserve surface correspondences across different poses. In this work, we introduce Invertible Neural Skinning (INS) to address these shortcomings. To maintain correspondences, we propose a Pose-conditioned Invertible Network (PIN) architecture, which extends the LBS process by learning additional pose-varying deformations. Next, we combine PIN with a differentiable LBS module to build an expressive and end-to-end Invertible Neural Skinning (INS) pipeline. We demonstrate the strong performance of our method by outperforming the state-of-the-art reposing techniques on clothed humans and preserving surface correspondences, while being an order of magnitude faster. We also perform an ablation study, which shows the usefulness of our pose-conditioning formulation, and our qualitative results display that INS can rectify artefacts introduced by LBS well. See our webpage for more details: https://yashkant.github.io/invertible-neural-skinning/
Context-self contrastive pretraining for crop type semantic segmentation
Apr 09, 2021
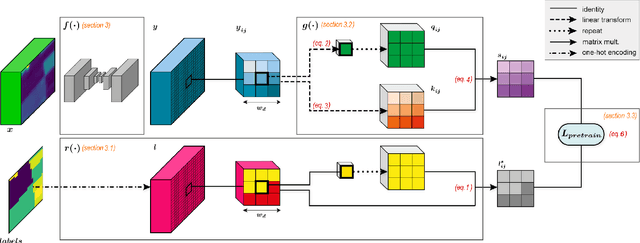
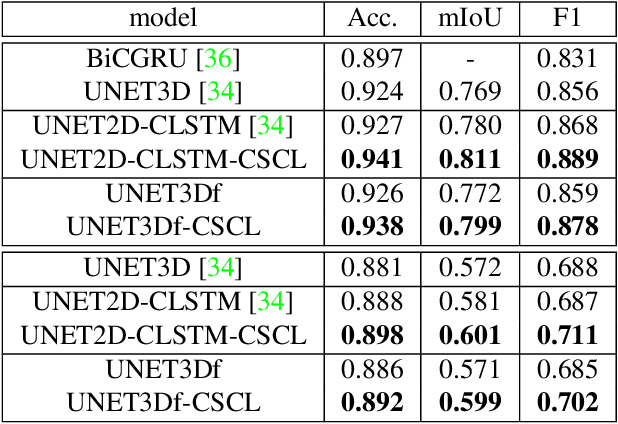
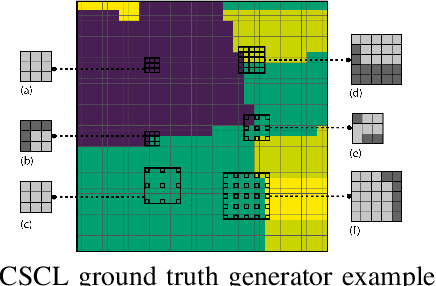
In this paper we propose a fully-supervised pretraining scheme based on contrastive learning particularly tailored to dense classification tasks. The proposed Context-Self Contrastive Loss (CSCL) learns an embedding space that makes semantic boundaries pop-up by use of a similarity metric between every location in an training sample and its local context. For crop type semantic segmentation from satellite images we find performance at parcel boundaries to be a critical bottleneck and explain how CSCL tackles the underlying cause of that problem, improving the state-of-the-art performance in this task. Additionally, using images from the Sentinel-2 (S2) satellite missions we compile the largest, to our knowledge, dataset of satellite image timeseries densely annotated by crop type and parcel identities, which we make publicly available together with the data generation pipeline. Using that data we find CSCL, even with minimal pretraining, to improve all respective baselines and present a process for semantic segmentation at super-resolution for obtaining crop classes at a more granular level. The proposed method is further validated on the task of semantic segmentation on 2D and 3D volumetric images showing consistent performance improvements upon competitive baselines.
Lifting AutoEncoders: Unsupervised Learning of a Fully-Disentangled 3D Morphable Model using Deep Non-Rigid Structure from Motion
Apr 26, 2019
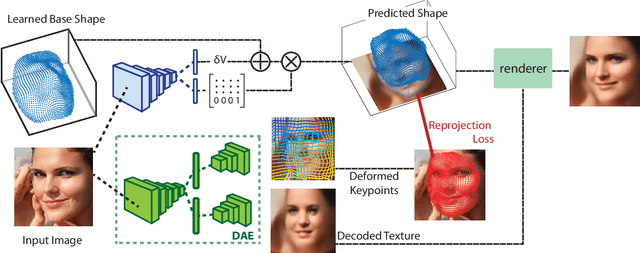
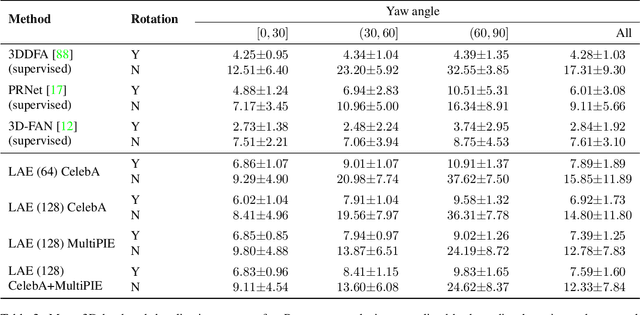

In this work we introduce Lifting Autoencoders, a generative 3D surface-based model of object categories. We bring together ideas from non-rigid structure from motion, image formation, and morphable models to learn a controllable, geometric model of 3D categories in an entirely unsupervised manner from an unstructured set of images. We exploit the 3D geometric nature of our model and use normal information to disentangle appearance into illumination, shading and albedo. We further use weak supervision to disentangle the non-rigid shape variability of human faces into identity and expression. We combine the 3D representation with a differentiable renderer to generate RGB images and append an adversarially trained refinement network to obtain sharp, photorealistic image reconstruction results. The learned generative model can be controlled in terms of interpretable geometry and appearance factors, allowing us to perform photorealistic image manipulation of identity, expression, 3D pose, and illumination properties.
Dense Pose Transfer
Sep 06, 2018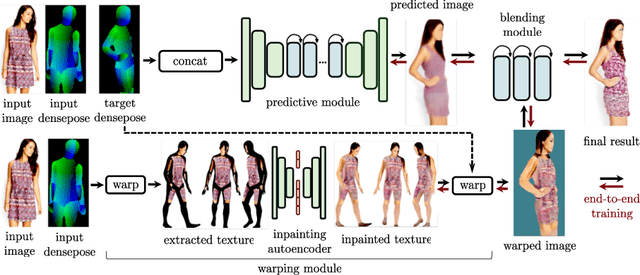
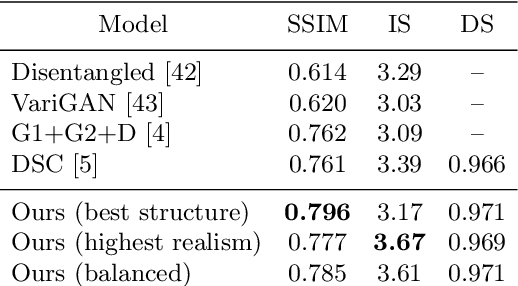
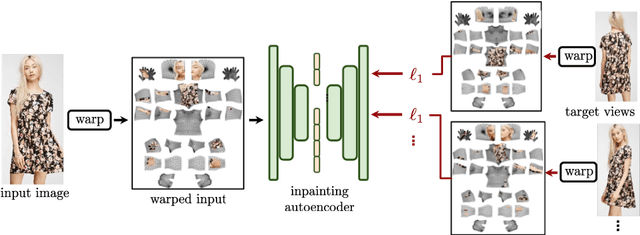
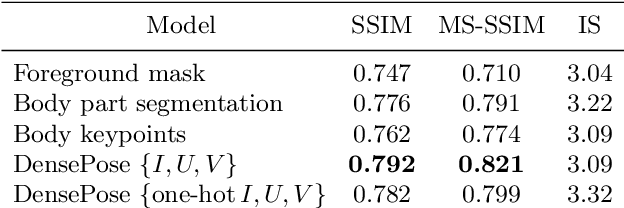
In this work we integrate ideas from surface-based modeling with neural synthesis: we propose a combination of surface-based pose estimation and deep generative models that allows us to perform accurate pose transfer, i.e. synthesize a new image of a person based on a single image of that person and the image of a pose donor. We use a dense pose estimation system that maps pixels from both images to a common surface-based coordinate system, allowing the two images to be brought in correspondence with each other. We inpaint and refine the source image intensities in the surface coordinate system, prior to warping them onto the target pose. These predictions are fused with those of a convolutional predictive module through a neural synthesis module allowing for training the whole pipeline jointly end-to-end, optimizing a combination of adversarial and perceptual losses. We show that dense pose estimation is a substantially more powerful conditioning input than landmark-, or mask-based alternatives, and report systematic improvements over state of the art generators on DeepFashion and MVC datasets.