 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving face generation quality and prompt following with synthetic captions
May 17, 2024



Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
ShapeFusion: A 3D diffusion model for localized shape editing
Apr 04, 2024



In the realm of 3D computer vision, parametric models have emerged as a ground-breaking methodology for the creation of realistic and expressive 3D avatars. Traditionally, they rely on Principal Component Analysis (PCA), given its ability to decompose data to an orthonormal space that maximally captures shape variations. However, due to the orthogonality constraints and the global nature of PCA's decomposition, these models struggle to perform localized and disentangled editing of 3D shapes, which severely affects their use in applications requiring fine control such as face sculpting. In this paper, we leverage diffusion models to enable diverse and fully localized edits on 3D meshes, while completely preserving the un-edited regions. We propose an effective diffusion masking training strategy that, by design, facilitates localized manipulation of any shape region, without being limited to predefined regions or to sparse sets of predefined control vertices. Following our framework, a user can explicitly set their manipulation region of choice and define an arbitrary set of vertices as handles to edit a 3D mesh. Compared to the current state-of-the-art our method leads to more interpretable shape manipulations than methods relying on latent code state, greater localization and generation diversity while offering faster inference than optimization based approaches. Project page: https://rolpotamias.github.io/Shapefusion/
Locally Adaptive Neural 3D Morphable Models
Jan 05, 2024We present the Locally Adaptive Morphable Model (LAMM), a highly flexible Auto-Encoder (AE) framework for learning to generate and manipulate 3D meshes. We train our architecture following a simple self-supervised training scheme in which input displacements over a set of sparse control vertices are used to overwrite the encoded geometry in order to transform one training sample into another. During inference, our model produces a dense output that adheres locally to the specified sparse geometry while maintaining the overall appearance of the encoded object. This approach results in state-of-the-art performance in both disentangling manipulated geometry and 3D mesh reconstruction. To the best of our knowledge LAMM is the first end-to-end framework that enables direct local control of 3D vertex geometry in a single forward pass. A very efficient computational graph allows our network to train with only a fraction of the memory required by previous methods and run faster during inference, generating 12k vertex meshes at $>$60fps on a single CPU thread. We further leverage local geometry control as a primitive for higher level editing operations and present a set of derivative capabilities such as swapping and sampling object parts. Code and pretrained models can be found at https://github.com/michaeltrs/LAMM.
Rethinking the Domain Gap in Near-infrared Face Recognition
Dec 01, 2023



Heterogeneous face recognition (HFR) involves the intricate task of matching face images across the visual domains of visible (VIS) and near-infrared (NIR). While much of the existing literature on HFR identifies the domain gap as a primary challenge and directs efforts towards bridging it at either the input or feature level, our work deviates from this trend. We observe that large neural networks, unlike their smaller counterparts, when pre-trained on large scale homogeneous VIS data, demonstrate exceptional zero-shot performance in HFR, suggesting that the domain gap might be less pronounced than previously believed. By approaching the HFR problem as one of low-data fine-tuning, we introduce a straightforward framework: comprehensive pre-training, succeeded by a regularized fine-tuning strategy, that matches or surpasses the current state-of-the-art on four publicly available benchmarks. Corresponding codes can be found at https://github.com/michaeltrs/RethinkNIRVIS.
ViTs for SITS: Vision Transformers for Satellite Image Time Series
Jan 26, 2023



In this paper we introduce the Temporo-Spatial Vision Transformer (TSViT), a fully-attentional model for general Satellite Image Time Series (SITS) processing based on the Vision Transformer (ViT). TSViT splits a SITS record into non-overlapping patches in space and time which are tokenized and subsequently processed by a factorized temporo-spatial encoder. We argue, that in contrast to natural images, a temporal-then-spatial factorization is more intuitive for SITS processing and present experimental evidence for this claim. Additionally, we enhance the model's discriminative power by introducing two novel mechanisms for acquisition-time-specific temporal positional encodings and multiple learnable class tokens. The effect of all novel design choices is evaluated through an extensive ablation study. Our proposed architecture achieves state-of-the-art performance, surpassing previous approaches by a significant margin in three publicly available SITS semantic segmentation and classification datasets. All model, training and evaluation codes are made publicly available to facilitate further research.
Embedding Earth: Self-supervised contrastive pre-training for dense land cover classification
Mar 11, 2022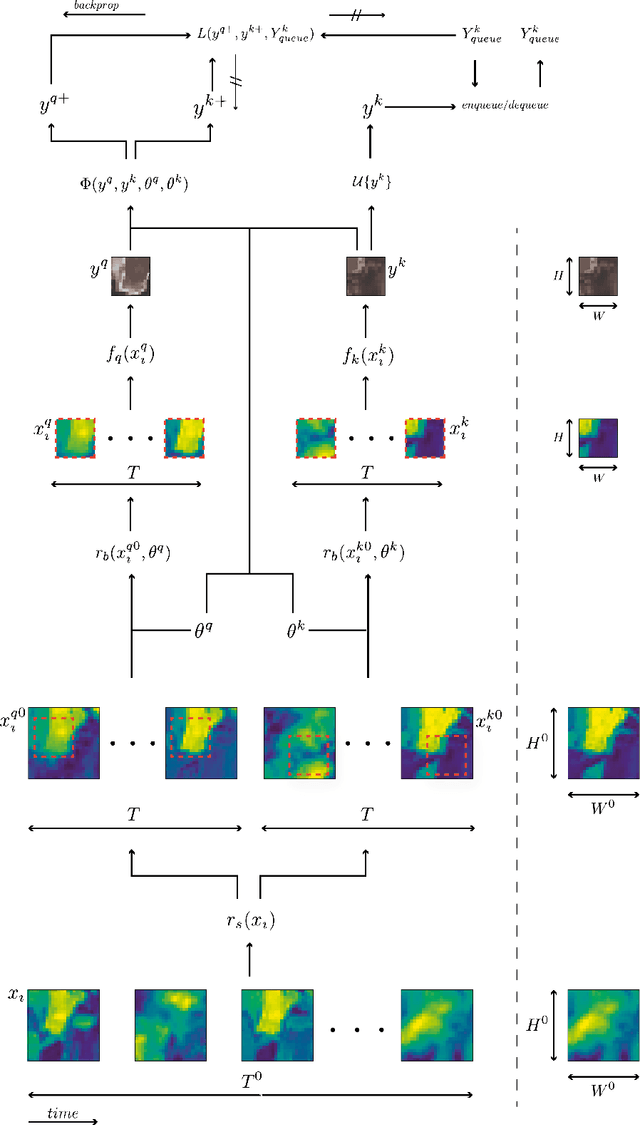
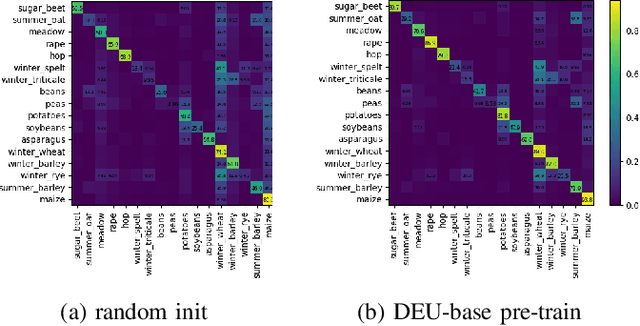
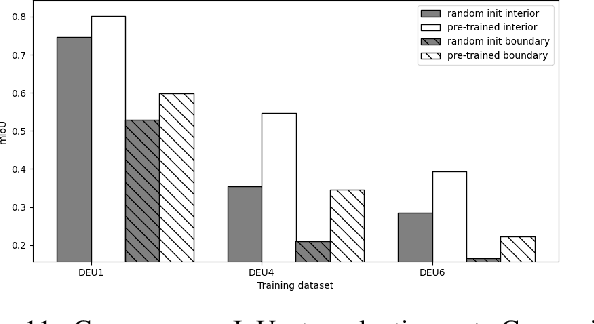
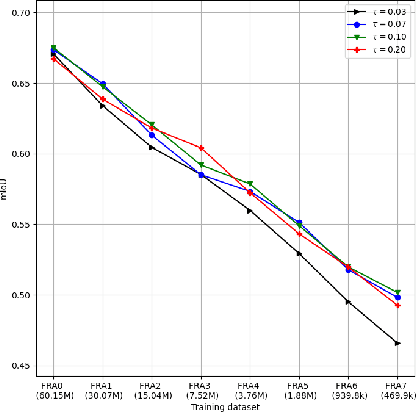
In training machine learning models for land cover semantic segmentation there is a stark contrast between the availability of satellite imagery to be used as inputs and ground truth data to enable supervised learning. While thousands of new satellite images become freely available on a daily basis, getting ground truth data is still very challenging, time consuming and costly. In this paper we present Embedding Earth a self-supervised contrastive pre-training method for leveraging the large availability of satellite imagery to improve performance on downstream dense land cover classification tasks. Performing an extensive experimental evaluation spanning four countries and two continents we use models pre-trained with our proposed method as initialization points for supervised land cover semantic segmentation and observe significant improvements up to 25% absolute mIoU. In every case tested we outperform random initialization, especially so when ground truth data are scarse. Through a series of ablation studies we explore the qualities of the proposed approach and find that learnt features can generalize between disparate regions opening up the possibility of using the proposed pre-training scheme as a replacement to random initialization for Earth observation tasks. Code will be uploaded soon at https://github.com/michaeltrs/DeepSatModels.
DeepSatData: Building large scale datasets of satellite images for training machine learning models
May 06, 2021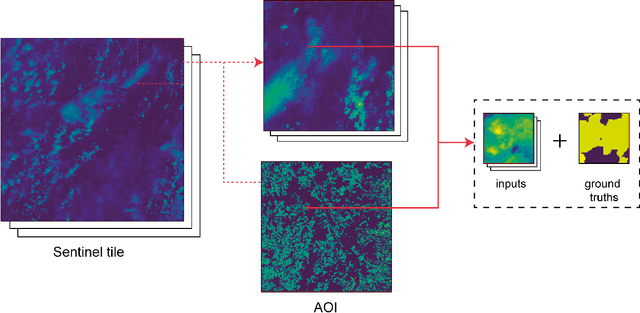
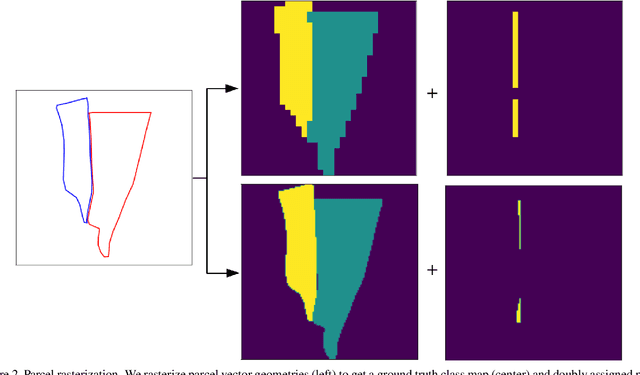
This report presents design considerations for automatically generating satellite imagery datasets for training machine learning models with emphasis placed on dense classification tasks, e.g. semantic segmentation. The implementation presented makes use of freely available Sentinel-2 data which allows generation of large scale datasets required for training deep neural networks. We discuss issues faced from the point of view of deep neural network training and evaluation such as checking the quality of ground truth data and comment on the scalability of the approach. Accompanying code is provided in https://github.com/michaeltrs/DeepSatData.
Context-self contrastive pretraining for crop type semantic segmentation
Apr 09, 2021
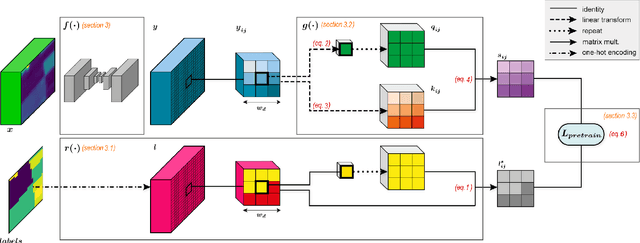
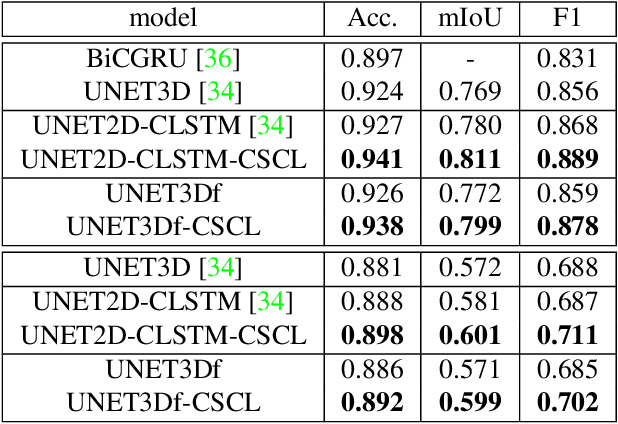
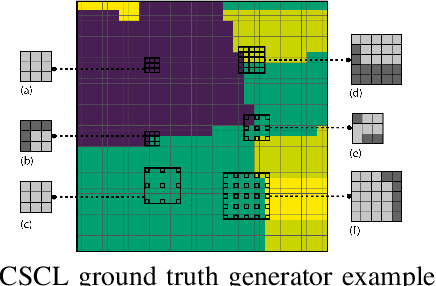
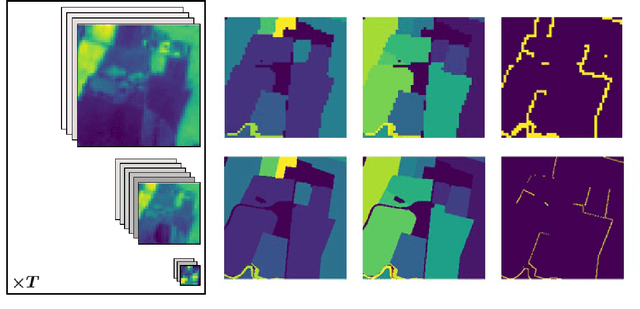
In this paper we propose a fully-supervised pretraining scheme based on contrastive learning particularly tailored to dense classification tasks. The proposed Context-Self Contrastive Loss (CSCL) learns an embedding space that makes semantic boundaries pop-up by use of a similarity metric between every location in an training sample and its local context. For crop type semantic segmentation from satellite images we find performance at parcel boundaries to be a critical bottleneck and explain how CSCL tackles the underlying cause of that problem, improving the state-of-the-art performance in this task. Additionally, using images from the Sentinel-2 (S2) satellite missions we compile the largest, to our knowledge, dataset of satellite image timeseries densely annotated by crop type and parcel identities, which we make publicly available together with the data generation pipeline. Using that data we find CSCL, even with minimal pretraining, to improve all respective baselines and present a process for semantic segmentation at super-resolution for obtaining crop classes at a more granular level. The proposed method is further validated on the task of semantic segmentation on 2D and 3D volumetric images showing consistent performance improvements upon competitive baselines.
Using Fully Convolutional Neural Networks to detect manipulated images in videos
Nov 29, 2019
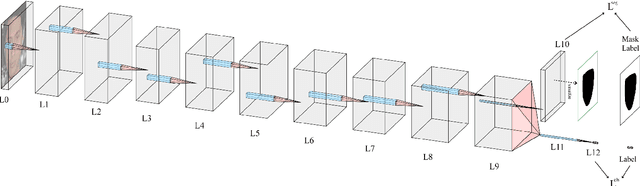

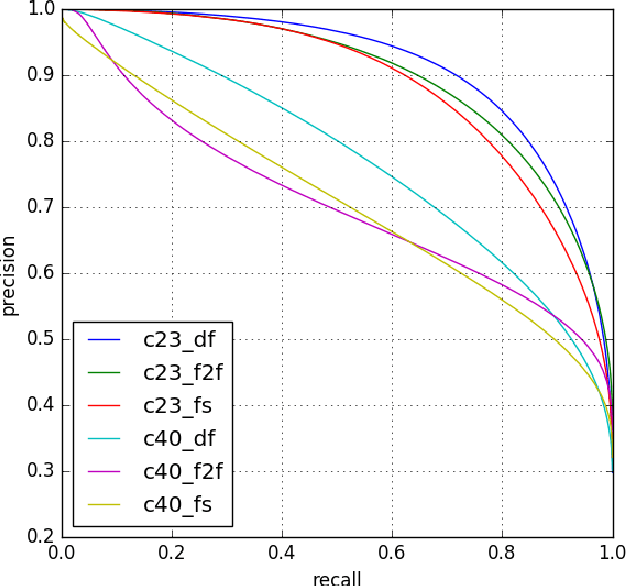
We propose a compact architecture based on fully convolutional neural networks (FCN) to detect manipulated images of human faces. In contrast to existing FCN architectures for classification, here the final layer feature map exhibits large spatial dimensions with non-global receptive field. The final layer features are spatially averaged using global average pooling (GAP) to provide more robust features. We leverage the structure of the FCN to derive a straightforward way for joint classification and forgery localization training and show that the network's classification performance improves significantly by the addition of a pixelwise classification loss. The trained networks achieve state of the art results in binary classification in the {\it FaceForensics++} dataset and competitive performance in other tasks using a significantly reduced number of parameters and small resolution input images. Additionally, we examine how well the proposed architecture can detect fully generated images using faces from the recently proposed PGAN and StyleGAN methods. We show that this task is easier to learn than detecting manipulated images and that for both cases there is only a small drop of performance when the network is trained using more than one manipulation technique in the training data.
Synthesising 3D Facial Motion from "In-the-Wild" Speech
Apr 15, 2019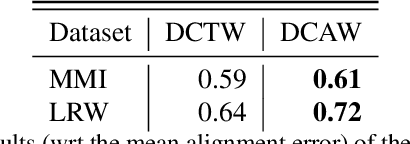
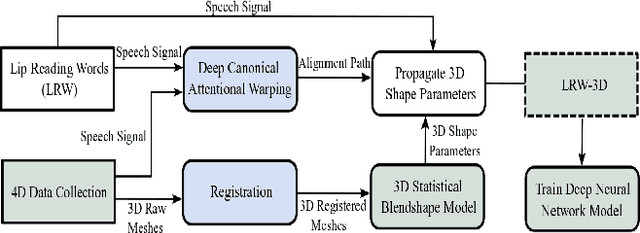

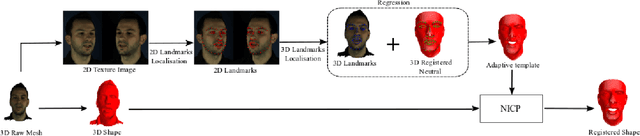
Synthesising 3D facial motion from speech is a crucial problem manifesting in a multitude of applications such as computer games and movies. Recently proposed methods tackle this problem in controlled conditions of speech. In this paper, we introduce the first methodology for 3D facial motion synthesis from speech captured in arbitrary recording conditions ("in-the-wild") and independent of the speaker. For our purposes, we captured 4D sequences of people uttering 500 words, contained in the Lip Reading Words (LRW) a publicly available large-scale in-the-wild dataset, and built a set of 3D blendshapes appropriate for speech. We correlate the 3D shape parameters of the speech blendshapes to the LRW audio samples by means of a novel time-warping technique, named Deep Canonical Attentional Warping (DCAW), that can simultaneously learn hierarchical non-linear representations and a warping path in an end-to-end manner. We thoroughly evaluate our proposed methods, and show the ability of a deep learning model to synthesise 3D facial motion in handling different speakers and continuous speech signals in uncontrolled conditions.