 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona-DB: Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement
Feb 16, 2024The increasing demand for personalized interactions with large language models (LLMs) calls for the development of methodologies capable of accurately and efficiently identifying user opinions and preferences. Retrieval augmentation emerges as an effective strategy, as it can accommodate a vast number of users without the costs from fine-tuning. Existing research, however, has largely focused on enhancing the retrieval stage and devoted limited exploration toward optimizing the representation of the database, a crucial aspect for tasks such as personalization. In this work, we examine the problem from a novel angle, focusing on how data can be better represented for more efficient retrieval in the context of LLM customization. To tackle this challenge, we introduce Persona-DB, a simple yet effective framework consisting of a hierarchical construction process to improve generalization across task contexts and collaborative refinement to effectively bridge knowledge gaps among users. In the task of response forecasting, Persona-DB demonstrates superior efficiency in maintaining accuracy with a significantly reduced retrieval size, a critical advantage in scenarios with extensive histories or limited context windows. Our experiments also indicate a marked improvement of over 15% under cold-start scenarios, when users have extremely sparse data. Furthermore, our analysis reveals the increasing importance of collaborative knowledge as the retrieval capacity expands.
Factcheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of LLM Output
Nov 16, 2023



The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We design and build an annotation tool to speed up the labelling procedure and ease the workload of raters. It allows flexible incorporation of automatic results in any stage, e.g. automatically-retrieved evidence. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims with the best F1=0.53. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
Social Commonsense-Guided Search Query Generation for Open-Domain Knowledge-Powered Conversations
Oct 22, 2023



Open-domain dialog involves generating search queries that help obtain relevant knowledge for holding informative conversations. However, it can be challenging to determine what information to retrieve when the user is passive and does not express a clear need or request. To tackle this issue, we present a novel approach that focuses on generating internet search queries that are guided by social commonsense. Specifically, we leverage a commonsense dialog system to establish connections related to the conversation topic, which subsequently guides our query generation. Our proposed framework addresses passive user interactions by integrating topic tracking, commonsense response generation and instruction-driven query generation. Through extensive evaluations, we show that our approach overcomes limitations of existing query generation techniques that rely solely on explicit dialog information, and produces search queries that are more relevant, specific, and compelling, ultimately resulting in more engaging responses.
C-PMI: Conditional Pointwise Mutual Information for Turn-level Dialogue Evaluation
Jun 27, 2023
Existing reference-free turn-level evaluation metrics for chatbots inadequately capture the interaction between the user and the system. Consequently, they often correlate poorly with human evaluations. To address this issue, we propose a novel model-agnostic approach that leverages Conditional Pointwise Mutual Information (C-PMI) to measure the turn-level interaction between the system and the user based on a given evaluation dimension. Experimental results on the widely used FED dialogue evaluation dataset demonstrate that our approach significantly improves the correlation with human judgment compared with existing evaluation systems. By replacing the negative log-likelihood-based scorer with our proposed C-PMI scorer, we achieve a relative 60.5% higher Spearman correlation on average for the FED evaluation metric. Our code is publicly available at https://github.com/renll/C-PMI.
Inference-time Re-ranker Relevance Feedback for Neural Information Retrieval
May 19, 2023



Neural information retrieval often adopts a retrieve-and-rerank framework: a bi-encoder network first retrieves K (e.g., 100) candidates that are then re-ranked using a more powerful cross-encoder model to rank the better candidates higher. The re-ranker generally produces better candidate scores than the retriever, but is limited to seeing only the top K retrieved candidates, thus providing no improvements in retrieval performance as measured by Recall@K. In this work, we leverage the re-ranker to also improve retrieval by providing inference-time relevance feedback to the retriever. Concretely, we update the retriever's query representation for a test instance using a lightweight inference-time distillation of the re-ranker's prediction for that instance. The distillation loss is designed to bring the retriever's candidate scores closer to those of the re-ranker. A second retrieval step is then performed with the updated query vector. We empirically show that our approach, which can serve arbitrary retrieve-and-rerank pipelines, significantly improves retrieval recall in multiple domains, languages, and modalities.
SmartBook: AI-Assisted Situation Report Generation
Mar 28, 2023Emerging events, such as the COVID pandemic and the Ukraine Crisis, require a time-sensitive comprehensive understanding of the situation to allow for appropriate decision-making and effective action response. Automated generation of situation reports can significantly reduce the time, effort, and cost for domain experts when preparing their official human-curated reports. However, AI research toward this goal has been very limited, and no successful trials have yet been conducted to automate such report generation. We propose SmartBook, a novel task formulation targeting situation report generation, which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. We realize SmartBook for the Ukraine-Russia crisis by automatically generating intelligence analysis reports to assist expert analysts. The machine-generated reports are structured in the form of timelines, with each timeline organized by major events (or chapters), corresponding strategic questions (or sections) and their grounded summaries (or section content). Our proposed framework automatically detects real-time event-related strategic questions, which are more directed than manually-crafted analyst questions, which tend to be too complex, hard to parse, vague and high-level. Results from thorough qualitative evaluations show that roughly 82% of the questions in Smartbook have strategic importance, with at least 93% of the sections in the report being tactically useful. Further, experiments show that expert analysts tend to add more information into the SmartBook reports, with only 2.3% of the existing tokens being deleted, meaning SmartBook can serve as a useful foundation for analysts to build upon when creating intelligence reports.
SumREN: Summarizing Reported Speech about Events in News
Dec 02, 2022



A primary objective of news articles is to establish the factual record for an event, frequently achieved by conveying both the details of the specified event (i.e., the 5 Ws; Who, What, Where, When and Why regarding the event) and how people reacted to it (i.e., reported statements). However, existing work on news summarization almost exclusively focuses on the event details. In this work, we propose the novel task of summarizing the reactions of different speakers, as expressed by their reported statements, to a given event. To this end, we create a new multi-document summarization benchmark, SUMREN, comprising 745 summaries of reported statements from various public figures obtained from 633 news articles discussing 132 events. We propose an automatic silver training data generation approach for our task, which helps smaller models like BART achieve GPT-3 level performance on this task. Finally, we introduce a pipeline-based framework for summarizing reported speech, which we empirically show to generate summaries that are more abstractive and factual than baseline query-focused summarization approaches.
Entity-Conditioned Question Generation for Robust Attention Distribution in Neural Information Retrieval
Apr 24, 2022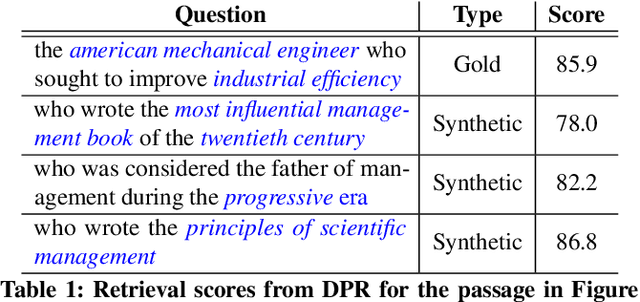
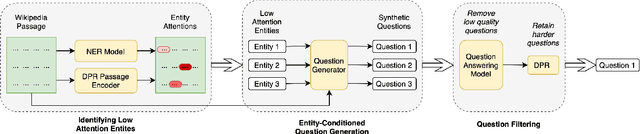

We show that supervised neural information retrieval (IR) models are prone to learning sparse attention patterns over passage tokens, which can result in key phrases including named entities receiving low attention weights, eventually leading to model under-performance. Using a novel targeted synthetic data generation method that identifies poorly attended entities and conditions the generation episodes on those, we teach neural IR to attend more uniformly and robustly to all entities in a given passage. On two public IR benchmarks, we empirically show that the proposed method helps improve both the model's attention patterns and retrieval performance, including in zero-shot settings.
Synthetic Target Domain Supervision for Open Retrieval QA
Apr 20, 2022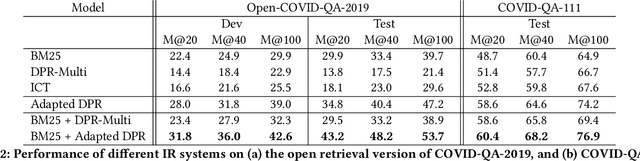
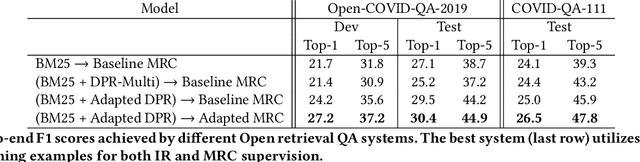
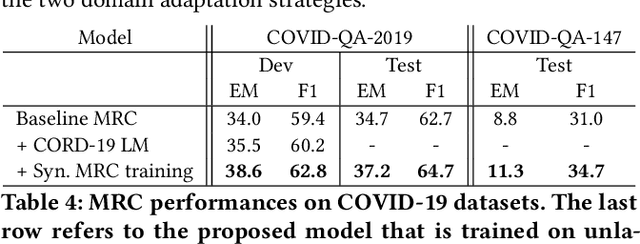
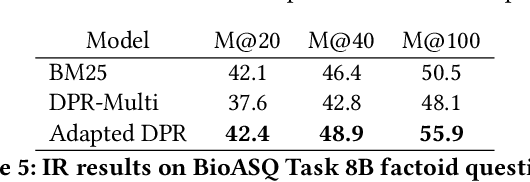
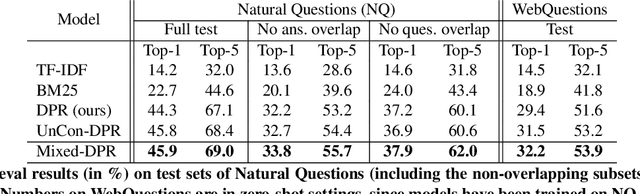
Neural passage retrieval is a new and promising approach in open retrieval question answering. In this work, we stress-test the Dense Passage Retriever (DPR) -- a state-of-the-art (SOTA) open domain neural retrieval model -- on closed and specialized target domains such as COVID-19, and find that it lags behind standard BM25 in this important real-world setting. To make DPR more robust under domain shift, we explore its fine-tuning with synthetic training examples, which we generate from unlabeled target domain text using a text-to-text generator. In our experiments, this noisy but fully automated target domain supervision gives DPR a sizable advantage over BM25 in out-of-domain settings, making it a more viable model in practice. Finally, an ensemble of BM25 and our improved DPR model yields the best results, further pushing the SOTA for open retrieval QA on multiple out-of-domain test sets.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

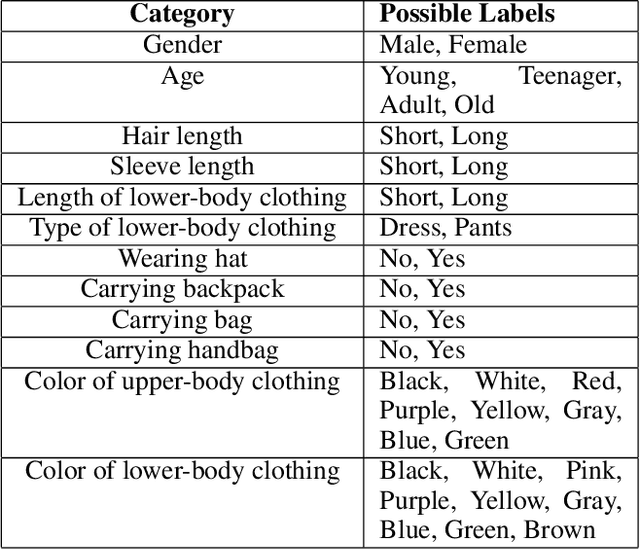
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.