 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Using Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Jul 29, 2025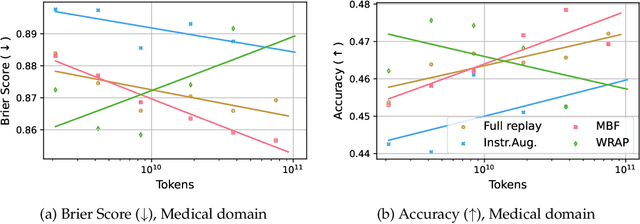
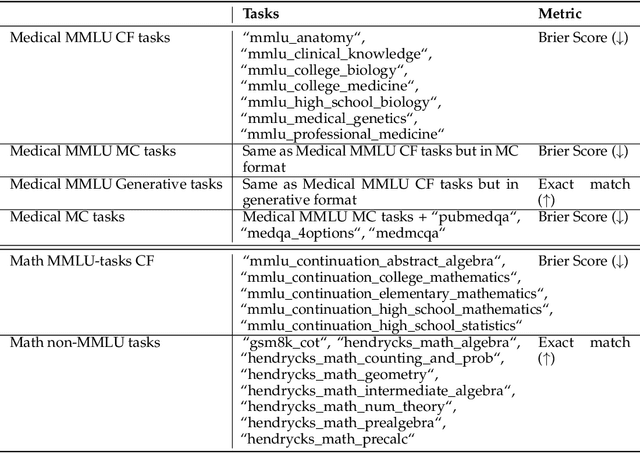
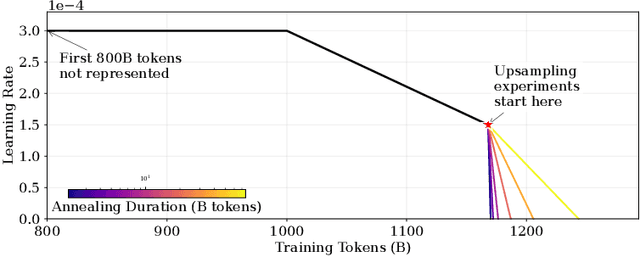
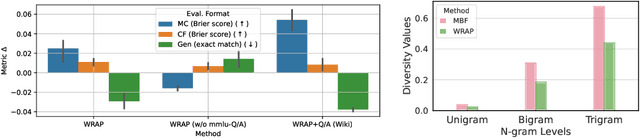
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to estimate the quality of data sources (e.g. synthetically generated or filtered web data, etc.) in order to make optimal decisions about resource allocation for data sourcing from these sources for the stage two pre-training phase, aka annealing, with the goal of specializing a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales -- a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods (e.g. synthetic data), data sources (e.g. user or web data) and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data -- the medical domain, and a domain underrepresented in the pretraining corpora -- the math domain. We show that one can efficiently estimate the scaling behaviors of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
Multi$^2$: Multi-Agent Test-Time Scalable Framework for Multi-Document Processing
Feb 27, 2025



Recent advances in test-time scaling have shown promising results in improving Large Language Models (LLMs) performance through strategic computation allocation during inference. While this approach has demonstrated strong performance improvements in logical and mathematical reasoning tasks, its application to natural language generation (NLG), especially summarization, has yet to be explored. Multi-Document Summarization (MDS) is a challenging task that focuses on extracting and synthesizing useful information from multiple lengthy documents. Unlike reasoning tasks, MDS requires a more nuanced approach to prompt design and ensemble, as there is no "best" prompt to satisfy diverse summarization requirements. To address this, we propose a novel framework that leverages inference-time scaling for this task. Precisely, we take prompt ensemble approach by leveraging various prompt to first generate candidate summaries and then ensemble them with an aggregator to produce a refined summary. We also introduce two new evaluation metrics: Consistency-Aware Preference (CAP) score and LLM Atom-Content-Unit (ACU) score, to enhance LLM's contextual understanding while mitigating its positional bias. Extensive experiments demonstrate the effectiveness of our approach in improving summary quality while identifying and analyzing the scaling boundaries in summarization tasks.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024



While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder
Mar 24, 2024



Detecting structural similarity between queries is essential for selecting examples in in-context learning models. However, assessing structural similarity based solely on the natural language expressions of queries, without considering SQL queries, presents a significant challenge. This paper explores the significance of this similarity metric and proposes a model for accurately estimating it. To achieve this, we leverage a dataset comprising 170k question pairs, meticulously curated to train a similarity prediction model. Our comprehensive evaluation demonstrates that the proposed model adeptly captures the structural similarity between questions, as evidenced by improvements in Kendall-Tau distance and precision@k metrics. Notably, our model outperforms strong competitive embedding models from OpenAI and Cohere. Furthermore, compared to these competitive models, our proposed encoder enhances the downstream performance of NL2SQL models in 1-shot in-context learning scenarios by 1-2\% for GPT-3.5-turbo, 4-8\% for CodeLlama-7B, and 2-3\% for CodeLlama-13B.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Visual Analytics for Generative Transformer Models
Nov 21, 2023While transformer-based models have achieved state-of-the-art results in a variety of classification and generation tasks, their black-box nature makes them challenging for interpretability. In this work, we present a novel visual analytical framework to support the analysis of transformer-based generative networks. In contrast to previous work, which has mainly focused on encoder-based models, our framework is one of the first dedicated to supporting the analysis of transformer-based encoder-decoder models and decoder-only models for generative and classification tasks. Hence, we offer an intuitive overview that allows the user to explore different facets of the model through interactive visualization. To demonstrate the feasibility and usefulness of our framework, we present three detailed case studies based on real-world NLP research problems.
Mixture-of-Linguistic-Experts Adapters for Improving and Interpreting Pre-trained Language Models
Oct 24, 2023



In this work, we propose a method that combines two popular research areas by injecting linguistic structures into pre-trained language models in the parameter-efficient fine-tuning (PEFT) setting. In our approach, parallel adapter modules encoding different linguistic structures are combined using a novel Mixture-of-Linguistic-Experts architecture, where Gumbel-Softmax gates are used to determine the importance of these modules at each layer of the model. To reduce the number of parameters, we first train the model for a fixed small number of steps before pruning the experts based on their importance scores. Our experiment results with three different pre-trained models show that our approach can outperform state-of-the-art PEFT methods with a comparable number of parameters. In addition, we provide additional analysis to examine the experts selected by each model at each layer to provide insights for future studies.
Diversity-Aware Coherence Loss for Improving Neural Topic Models
May 26, 2023The standard approach for neural topic modeling uses a variational autoencoder (VAE) framework that jointly minimizes the KL divergence between the estimated posterior and prior, in addition to the reconstruction loss. Since neural topic models are trained by recreating individual input documents, they do not explicitly capture the coherence between topic words on the corpus level. In this work, we propose a novel diversity-aware coherence loss that encourages the model to learn corpus-level coherence scores while maintaining a high diversity between topics. Experimental results on multiple datasets show that our method significantly improves the performance of neural topic models without requiring any pretraining or additional parameters.