 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Multimodal Topic Modeling: A Comprehensive Evaluation
Mar 26, 2024



Neural topic models can successfully find coherent and diverse topics in textual data. However, they are limited in dealing with multimodal datasets (e.g., images and text). This paper presents the first systematic and comprehensive evaluation of multimodal topic modeling of documents containing both text and images. In the process, we propose two novel topic modeling solutions and two novel evaluation metrics. Overall, our evaluation on an unprecedented rich and diverse collection of datasets indicates that both of our models generate coherent and diverse topics. Nevertheless, the extent to which one method outperforms the other depends on the metrics and dataset combinations, which suggests further exploration of hybrid solutions in the future. Notably, our succinct human evaluation aligns with the outcomes determined by our proposed metrics. This alignment not only reinforces the credibility of our metrics but also highlights the potential for their application in guiding future multimodal topic modeling endeavors.
Diversity-Aware Coherence Loss for Improving Neural Topic Models
May 26, 2023



The standard approach for neural topic modeling uses a variational autoencoder (VAE) framework that jointly minimizes the KL divergence between the estimated posterior and prior, in addition to the reconstruction loss. Since neural topic models are trained by recreating individual input documents, they do not explicitly capture the coherence between topic words on the corpus level. In this work, we propose a novel diversity-aware coherence loss that encourages the model to learn corpus-level coherence scores while maintaining a high diversity between topics. Experimental results on multiple datasets show that our method significantly improves the performance of neural topic models without requiring any pretraining or additional parameters.
Regional Differences in Information Privacy Concerns After the Facebook-Cambridge Analytica Data Scandal
Feb 16, 2022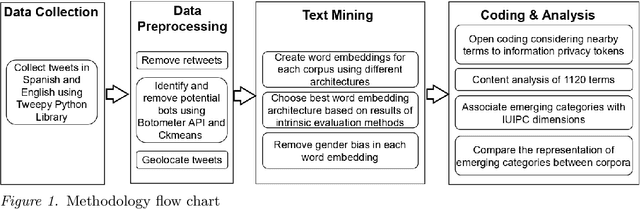
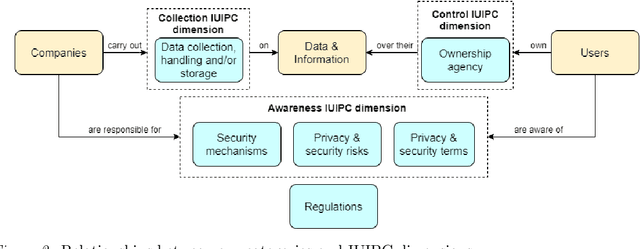

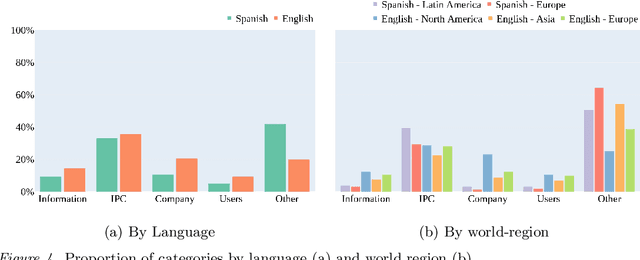
While there is increasing global attention to data privacy, most of their current theoretical understanding is based on research conducted in a few countries. Prior work argues that people's cultural backgrounds might shape their privacy concerns; thus, we could expect people from different world regions to conceptualize them in diverse ways. We collected and analyzed a large-scale dataset of tweets about the #CambridgeAnalytica scandal in Spanish and English to start exploring this hypothesis. We employed word embeddings and qualitative analysis to identify which information privacy concerns are present and characterize language and regional differences in emphasis on these concerns. Our results suggest that related concepts, such as regulations, can be added to current information privacy frameworks. We also observe a greater emphasis on data collection in English than in Spanish. Additionally, data from North America exhibits a narrower focus on awareness compared to other regions under study. Our results call for more diverse sources of data and nuanced analysis of data privacy concerns around the globe.