 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations
Aug 13, 2020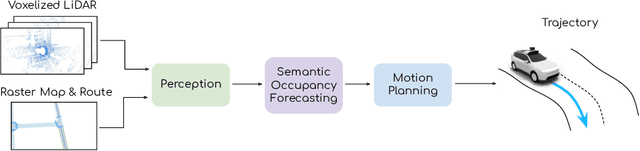
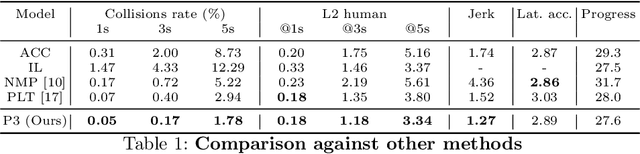
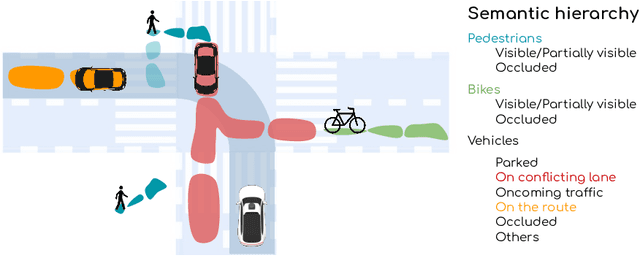
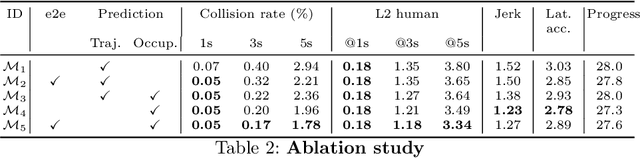
In this paper we propose a novel end-to-end learnable network that performs joint perception, prediction and motion planning for self-driving vehicles and produces interpretable intermediate representations. Unlike existing neural motion planners, our motion planning costs are consistent with our perception and prediction estimates. This is achieved by a novel differentiable semantic occupancy representation that is explicitly used as cost by the motion planning process. Our network is learned end-to-end from human demonstrations. The experiments in a large-scale manual-driving dataset and closed-loop simulation show that the proposed model significantly outperforms state-of-the-art planners in imitating the human behaviors while producing much safer trajectories.
End-to-end Contextual Perception and Prediction with Interaction Transformer
Aug 13, 2020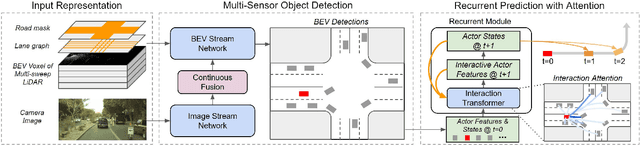
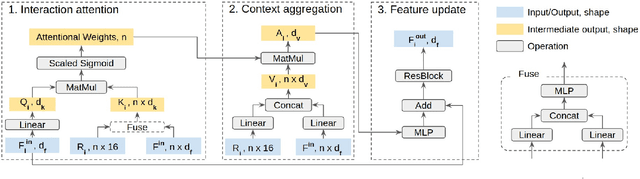
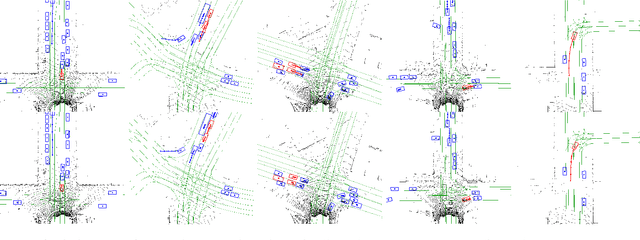
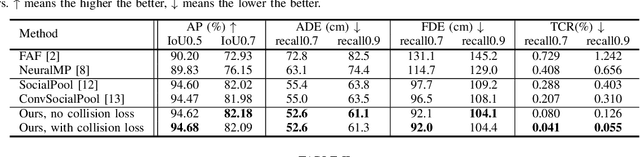
In this paper, we tackle the problem of detecting objects in 3D and forecasting their future motion in the context of self-driving. Towards this goal, we design a novel approach that explicitly takes into account the interactions between actors. To capture their spatial-temporal dependencies, we propose a recurrent neural network with a novel Transformer architecture, which we call the Interaction Transformer. Importantly, our model can be trained end-to-end, and runs in real-time. We validate our approach on two challenging real-world datasets: ATG4D and nuScenes. We show that our approach can outperform the state-of-the-art on both datasets. In particular, we significantly improve the social compliance between the estimated future trajectories, resulting in far fewer collisions between the predicted actors.
LoCo: Local Contrastive Representation Learning
Aug 04, 2020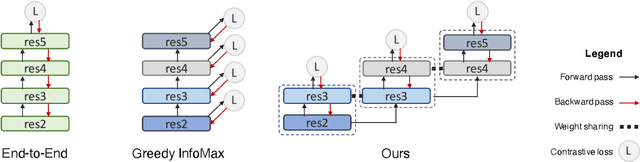
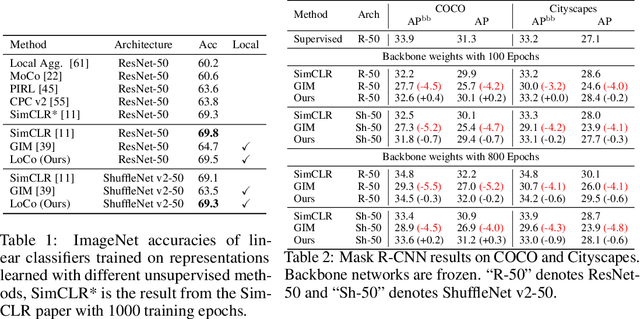
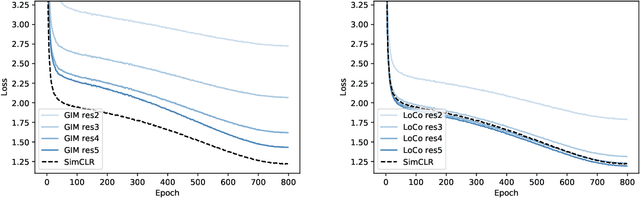
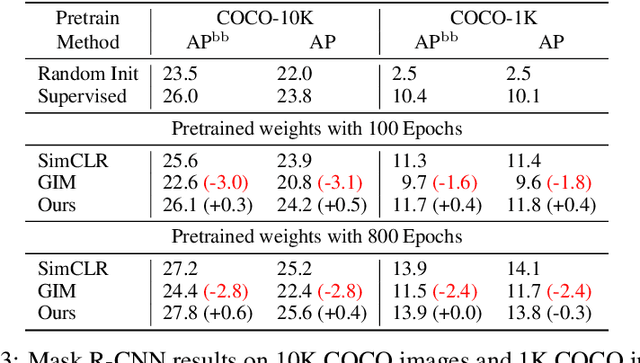
Deep neural nets typically perform end-to-end backpropagation to learn the weights, a procedure that creates synchronization constraints in the weight update step across layers and is not biologically plausible. Recent advances in unsupervised contrastive representation learning point to the question of whether a learning algorithm can also be made local, that is, the updates of lower layers do not directly depend on the computation of upper layers. While Greedy InfoMax separately learns each block with a local objective, we found that it consistently hurts readout accuracy in state-of-the-art unsupervised contrastive learning algorithms, possibly due to the greedy objective as well as gradient isolation. In this work, we discover that by overlapping local blocks stacking on top of each other, we effectively increase the decoder depth and allow upper blocks to implicitly send feedbacks to lower blocks. This simple design closes the performance gap between local learning and end-to-end contrastive learning algorithms for the first time. Aside from standard ImageNet experiments, we also show results on complex downstream tasks such as object detection and instance segmentation directly using readout features.
LevelSet R-CNN: A Deep Variational Method for Instance Segmentation
Jul 30, 2020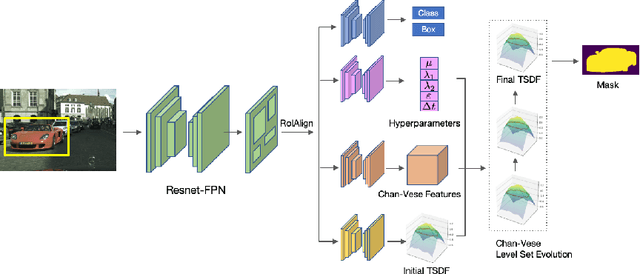
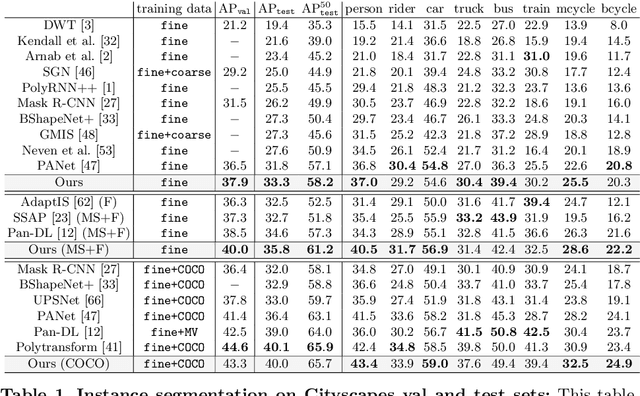


Obtaining precise instance segmentation masks is of high importance in many modern applications such as robotic manipulation and autonomous driving. Currently, many state of the art models are based on the Mask R-CNN framework which, while very powerful, outputs masks at low resolutions which could result in imprecise boundaries. On the other hand, classic variational methods for segmentation impose desirable global and local data and geometry constraints on the masks by optimizing an energy functional. While mathematically elegant, their direct dependence on good initialization, non-robust image cues and manual setting of hyperparameters renders them unsuitable for modern applications. We propose LevelSet R-CNN, which combines the best of both worlds by obtaining powerful feature representations that are combined in an end-to-end manner with a variational segmentation framework. We demonstrate the effectiveness of our approach on COCO and Cityscapes datasets.
RadarNet: Exploiting Radar for Robust Perception of Dynamic Objects
Jul 28, 2020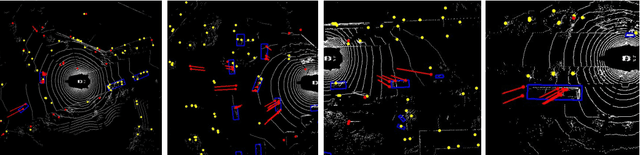

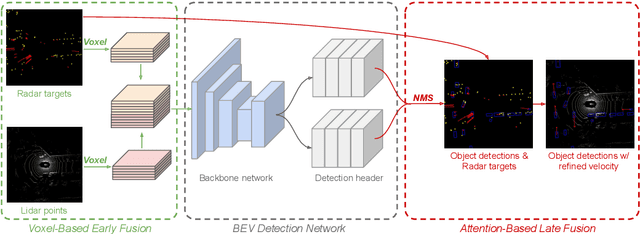
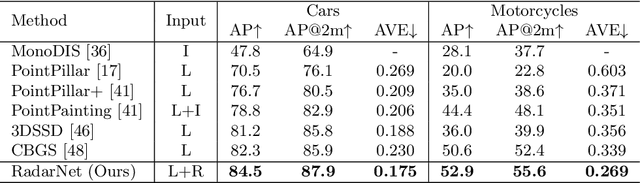
We tackle the problem of exploiting Radar for perception in the context of self-driving as Radar provides complementary information to other sensors such as LiDAR or cameras in the form of Doppler velocity. The main challenges of using Radar are the noise and measurement ambiguities which have been a struggle for existing simple input or output fusion methods. To better address this, we propose a new solution that exploits both LiDAR and Radar sensors for perception. Our approach, dubbed RadarNet, features a voxel-based early fusion and an attention-based late fusion, which learn from data to exploit both geometric and dynamic information of Radar data. RadarNet achieves state-of-the-art results on two large-scale real-world datasets in the tasks of object detection and velocity estimation. We further show that exploiting Radar improves the perception capabilities of detecting faraway objects and understanding the motion of dynamic objects.
Learning Lane Graph Representations for Motion Forecasting
Jul 27, 2020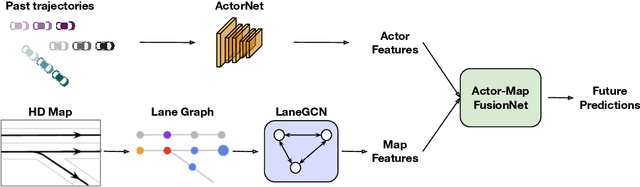
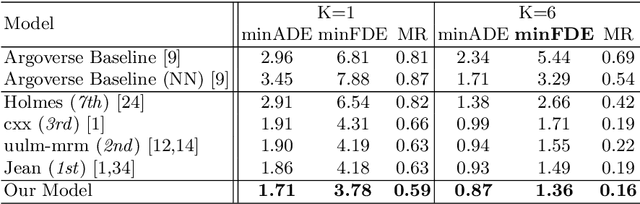
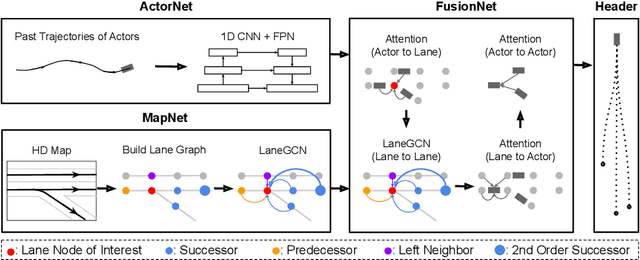
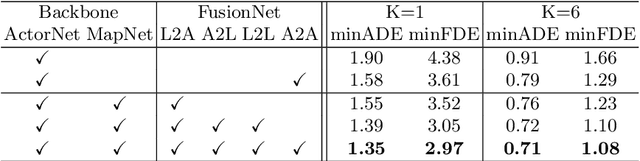
We propose a motion forecasting model that exploits a novel structured map representation as well as actor-map interactions. Instead of encoding vectorized maps as raster images, we construct a lane graph from raw map data to explicitly preserve the map structure. To capture the complex topology and long range dependencies of the lane graph, we propose LaneGCN which extends graph convolutions with multiple adjacency matrices and along-lane dilation. To capture the complex interactions between actors and maps, we exploit a fusion network consisting of four types of interactions, actor-to-lane, lane-to-lane, lane-to-actor and actor-to-actor. Powered by LaneGCN and actor-map interactions, our model is able to predict accurate and realistic multi-modal trajectories. Our approach significantly outperforms the state-of-the-art on the large scale Argoverse motion forecasting benchmark.
Implicit Latent Variable Model for Scene-Consistent Motion Forecasting
Jul 23, 2020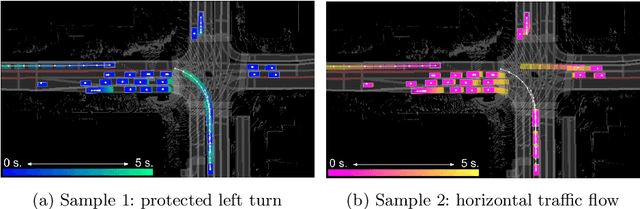
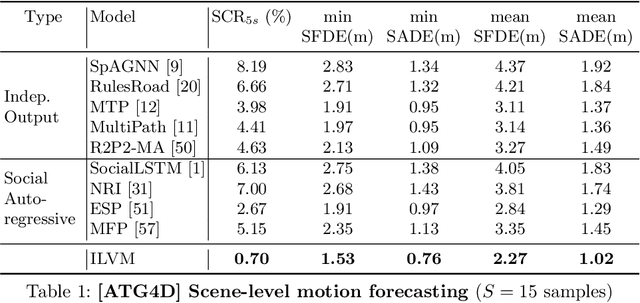

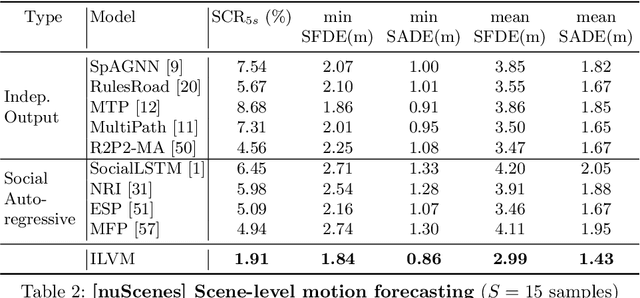
In order to plan a safe maneuver an autonomous vehicle must accurately perceive its environment, and understand the interactions among traffic participants. In this paper, we aim to learn scene-consistent motion forecasts of complex urban traffic directly from sensor data. In particular, we propose to characterize the joint distribution over future trajectories via an implicit latent variable model. We model the scene as an interaction graph and employ powerful graph neural networks to learn a distributed latent representation of the scene. Coupled with a deterministic decoder, we obtain trajectory samples that are consistent across traffic participants, achieving state-of-the-art results in motion forecasting and interaction understanding. Last but not least, we demonstrate that our motion forecasts result in safer and more comfortable motion planning.
Hierarchical Verification for Adversarial Robustness
Jul 23, 2020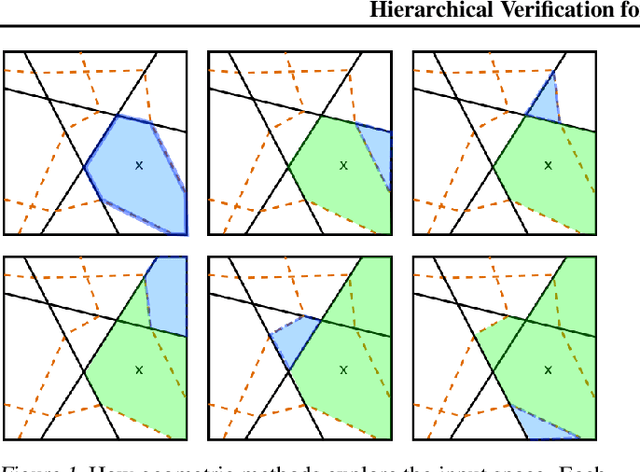
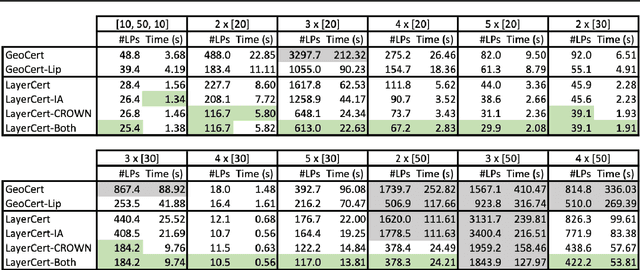
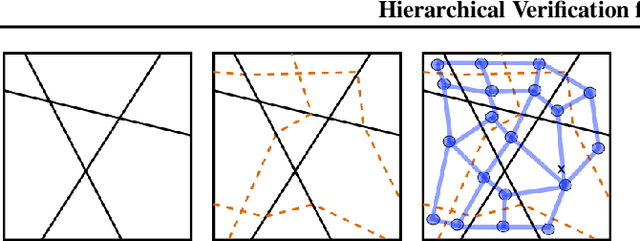
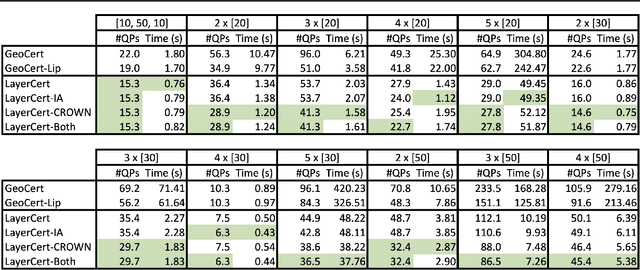
We introduce a new framework for the exact point-wise $\ell_p$ robustness verification problem that exploits the layer-wise geometric structure of deep feed-forward networks with rectified linear activations (ReLU networks). The activation regions of the network partition the input space, and one can verify the $\ell_p$ robustness around a point by checking all the activation regions within the desired radius. The GeoCert algorithm (Jordan et al., NeurIPS 2019) treats this partition as a generic polyhedral complex in order to detect which region to check next. In contrast, our LayerCert framework considers the \emph{nested hyperplane arrangement} structure induced by the layers of the ReLU network and explores regions in a hierarchical manner. We show that, under certain conditions on the algorithm parameters, LayerCert provably reduces the number and size of the convex programs that one needs to solve compared to GeoCert. Furthermore, our LayerCert framework allows the incorporation of lower bounding routines based on convex relaxations to further improve performance. Experimental results demonstrate that LayerCert can significantly reduce both the number of convex programs solved and the running time over the state-of-the-art.
Multi-Agent Routing Value Iteration Network
Jul 09, 2020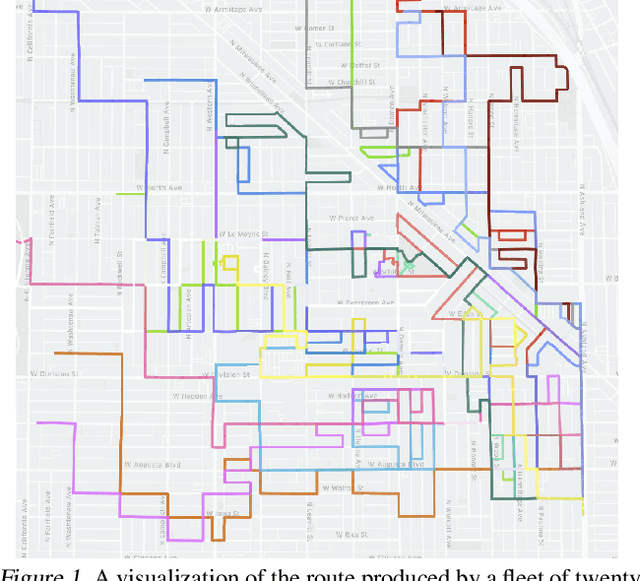

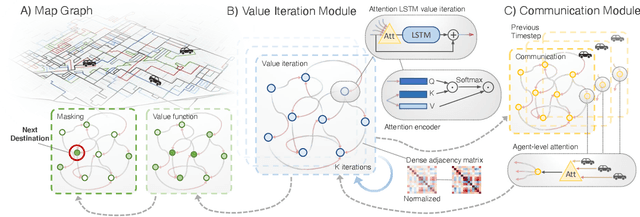
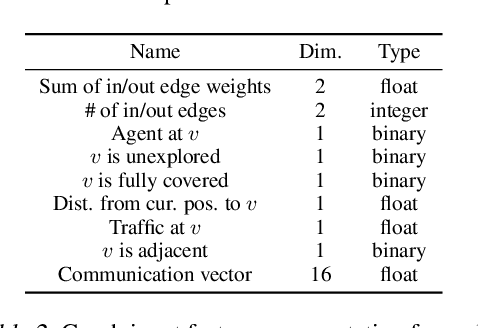
In this paper we tackle the problem of routing multiple agents in a coordinated manner. This is a complex problem that has a wide range of applications in fleet management to achieve a common goal, such as mapping from a swarm of robots and ride sharing. Traditional methods are typically not designed for realistic environments hich contain sparsely connected graphs and unknown traffic, and are often too slow in runtime to be practical. In contrast, we propose a graph neural network based model that is able to perform multi-agent routing based on learned value iteration in a sparsely connected graph with dynamically changing traffic conditions. Moreover, our learned communication module enables the agents to coordinate online and adapt to changes more effectively. We created a simulated environment to mimic realistic mapping performed by autonomous vehicles with unknown minimum edge coverage and traffic conditions; our approach significantly outperforms traditional solvers both in terms of total cost and runtime. We also show that our model trained with only two agents on graphs with a maximum of 25 nodes can easily generalize to situations with more agents and/or nodes.
PnPNet: End-to-End Perception and Prediction with Tracking in the Loop
Jun 27, 2020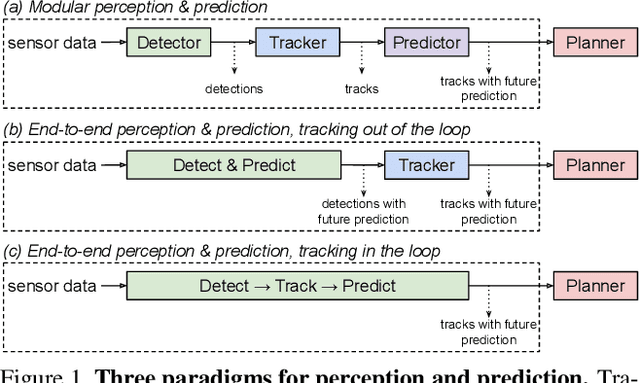
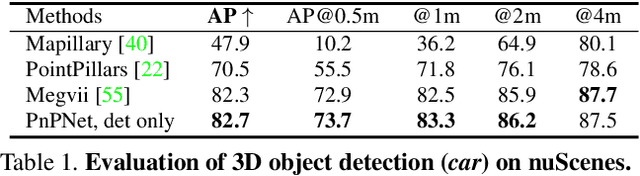
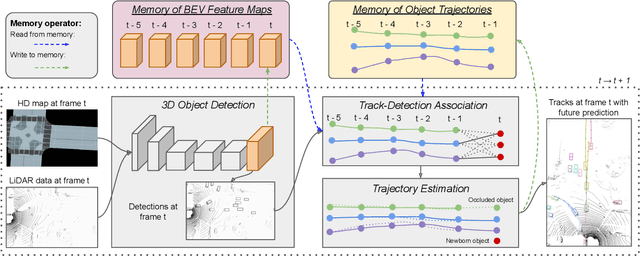

We tackle the problem of joint perception and motion forecasting in the context of self-driving vehicles. Towards this goal we propose PnPNet, an end-to-end model that takes as input sequential sensor data, and outputs at each time step object tracks and their future trajectories. The key component is a novel tracking module that generates object tracks online from detections and exploits trajectory level features for motion forecasting. Specifically, the object tracks get updated at each time step by solving both the data association problem and the trajectory estimation problem. Importantly, the whole model is end-to-end trainable and benefits from joint optimization of all tasks. We validate PnPNet on two large-scale driving datasets, and show significant improvements over the state-of-the-art with better occlusion recovery and more accurate future prediction.