 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally Efficient Horizon-Free Reinforcement Learning for Linear Mixture MDPs
May 23, 2022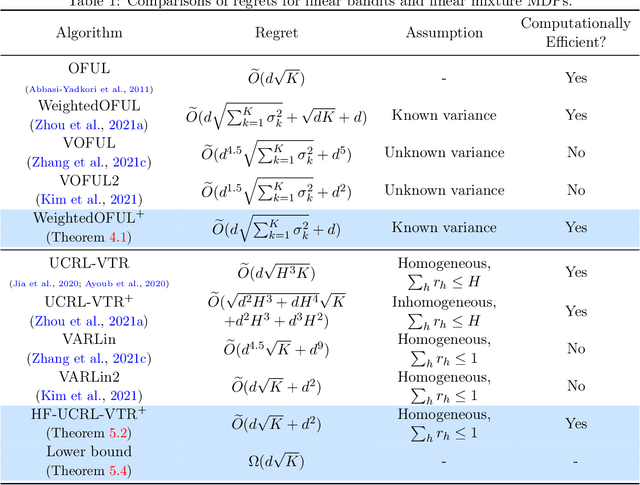
Recent studies have shown that episodic reinforcement learning (RL) is not more difficult than contextual bandits, even with a long planning horizon and unknown state transitions. However, these results are limited to either tabular Markov decision processes (MDPs) or computationally inefficient algorithms for linear mixture MDPs. In this paper, we propose the first computationally efficient horizon-free algorithm for linear mixture MDPs, which achieves the optimal $\tilde O(d\sqrt{K} +d^2)$ regret up to logarithmic factors. Our algorithm adapts a weighted least square estimator for the unknown transitional dynamic, where the weight is both \emph{variance-aware} and \emph{uncertainty-aware}. When applying our weighted least square estimator to heterogeneous linear bandits, we can obtain an $\tilde O(d\sqrt{\sum_{k=1}^K \sigma_k^2} +d)$ regret in the first $K$ rounds, where $d$ is the dimension of the context and $\sigma_k^2$ is the variance of the reward in the $k$-th round. This also improves upon the best-known algorithms in this setting when $\sigma_k^2$'s are known.
Nearly Optimal Algorithms for Linear Contextual Bandits with Adversarial Corruptions
May 13, 2022
We study the linear contextual bandit problem in the presence of adversarial corruption, where the reward at each round is corrupted by an adversary, and the corruption level (i.e., the sum of corruption magnitudes over the horizon) is $C\geq 0$. The best-known algorithms in this setting are limited in that they either are computationally inefficient or require a strong assumption on the corruption, or their regret is at least $C$ times worse than the regret without corruption. In this paper, to overcome these limitations, we propose a new algorithm based on the principle of optimism in the face of uncertainty. At the core of our algorithm is a weighted ridge regression where the weight of each chosen action depends on its confidence up to some threshold. We show that for both known $C$ and unknown $C$ cases, our algorithm with proper choice of hyperparameter achieves a regret that nearly matches the lower bounds. Thus, our algorithm is nearly optimal up to logarithmic factors for both cases. Notably, our algorithm achieves the near-optimal regret for both corrupted and uncorrupted cases ($C=0$) simultaneously.
On the Convergence of Certified Robust Training with Interval Bound Propagation
Mar 16, 2022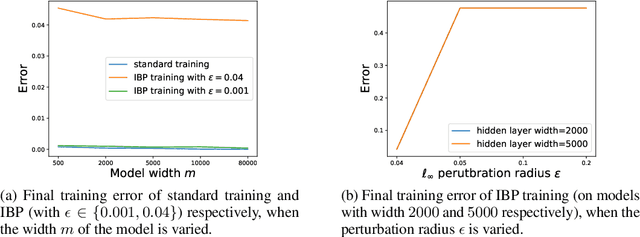
Interval Bound Propagation (IBP) is so far the base of state-of-the-art methods for training neural networks with certifiable robustness guarantees when potential adversarial perturbations present, while the convergence of IBP training remains unknown in existing literature. In this paper, we present a theoretical analysis on the convergence of IBP training. With an overparameterized assumption, we analyze the convergence of IBP robust training. We show that when using IBP training to train a randomly initialized two-layer ReLU neural network with logistic loss, gradient descent can linearly converge to zero robust training error with a high probability if we have sufficiently small perturbation radius and large network width.
Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime
Mar 07, 2022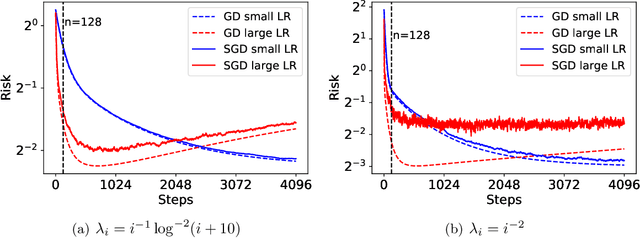
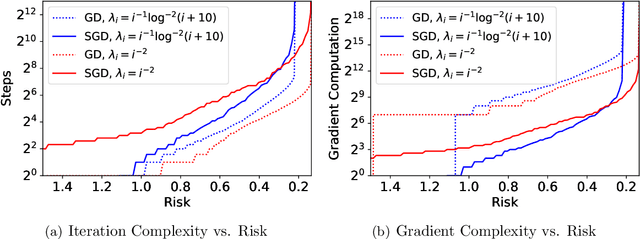
Stochastic gradient descent (SGD) has achieved great success due to its superior performance in both optimization and generalization. Most of existing generalization analyses are made for single-pass SGD, which is a less practical variant compared to the commonly-used multi-pass SGD. Besides, theoretical analyses for multi-pass SGD often concern a worst-case instance in a class of problems, which may be pessimistic to explain the superior generalization ability for some particular problem instance. The goal of this paper is to sharply characterize the generalization of multi-pass SGD, by developing an instance-dependent excess risk bound for least squares in the interpolation regime, which is expressed as a function of the iteration number, stepsize, and data covariance. We show that the excess risk of SGD can be exactly decomposed into the excess risk of GD and a positive fluctuation error, suggesting that SGD always performs worse, instance-wisely, than GD, in generalization. On the other hand, we show that although SGD needs more iterations than GD to achieve the same level of excess risk, it saves the number of stochastic gradient evaluations, and therefore is preferable in terms of computational time.
Bandit Learning with General Function Classes: Heteroscedastic Noise and Variance-dependent Regret Bounds
Feb 28, 2022
We consider learning a stochastic bandit model, where the reward function belongs to a general class of uniformly bounded functions, and the additive noise can be heteroscedastic. Our model captures contextual linear bandits and generalized linear bandits as special cases. While previous works (Kirschner and Krause, 2018; Zhou et al., 2021) based on weighted ridge regression can deal with linear bandits with heteroscedastic noise, they are not directly applicable to our general model due to the curse of nonlinearity. In order to tackle this problem, we propose a multi-level learning framework for the general bandit model. The core idea of our framework is to partition the observed data into different levels according to the variance of their respective reward and perform online learning at each level collaboratively. Under our framework, we first design an algorithm that constructs the variance-aware confidence set based on empirical risk minimization and prove a variance-dependent regret bound. For generalized linear bandits, we further propose an algorithm based on follow-the-regularized-leader (FTRL) subroutine and online-to-confidence-set conversion, which can achieve a tighter variance-dependent regret under certain conditions.
Benign Overfitting in Two-layer Convolutional Neural Networks
Feb 14, 2022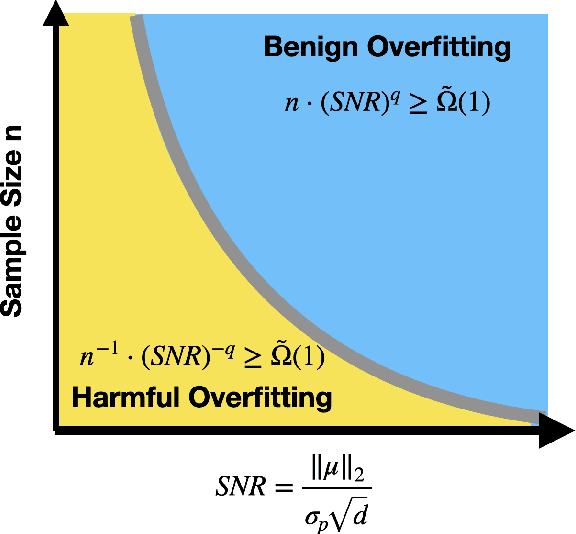
Modern neural networks often have great expressive power and can be trained to overfit the training data, while still achieving a good test performance. This phenomenon is referred to as "benign overfitting". Recently, there emerges a line of works studying "benign overfitting" from the theoretical perspective. However, they are limited to linear models or kernel/random feature models, and there is still a lack of theoretical understanding about when and how benign overfitting occurs in neural networks. In this paper, we study the benign overfitting phenomenon in training a two-layer convolutional neural network (CNN). We show that when the signal-to-noise ratio satisfies a certain condition, a two-layer CNN trained by gradient descent can achieve arbitrarily small training and test loss. On the other hand, when this condition does not hold, overfitting becomes harmful and the obtained CNN can only achieve constant level test loss. These together demonstrate a sharp phase transition between benign overfitting and harmful overfitting, driven by the signal-to-noise ratio. To the best of our knowledge, this is the first work that precisely characterizes the conditions under which benign overfitting can occur in training convolutional neural networks.
Learning Contextual Bandits Through Perturbed Rewards
Jan 24, 2022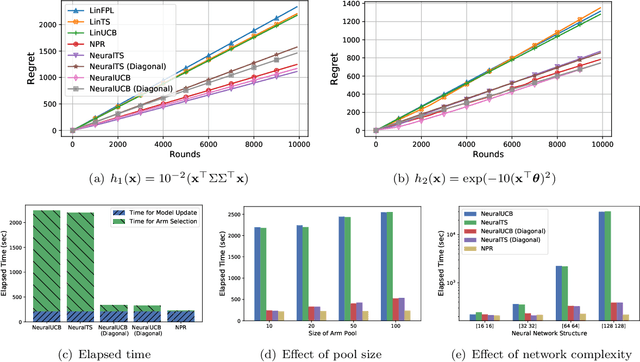

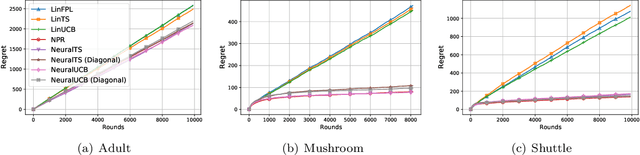
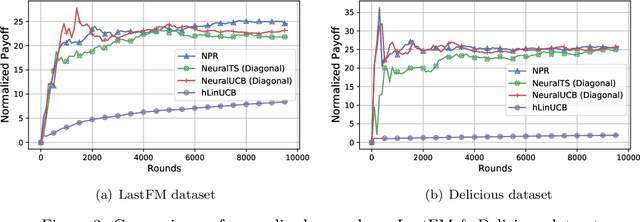
Thanks to the power of representation learning, neural contextual bandit algorithms demonstrate remarkable performance improvement against their classical counterparts. But because their exploration has to be performed in the entire neural network parameter space to obtain nearly optimal regret, the resulting computational cost is prohibitively high. We perturb the rewards when updating the neural network to eliminate the need of explicit exploration and the corresponding computational overhead. We prove that a $\tilde{O}(\tilde{d}\sqrt{T})$ regret upper bound is still achievable under standard regularity conditions, where $T$ is the number of rounds of interactions and $\tilde{d}$ is the effective dimension of a neural tangent kernel matrix. Extensive comparisons with several benchmark contextual bandit algorithms, including two recent neural contextual bandit models, demonstrate the effectiveness and computational efficiency of our proposed neural bandit algorithm.
Benign Overfitting in Adversarially Robust Linear Classification
Dec 31, 2021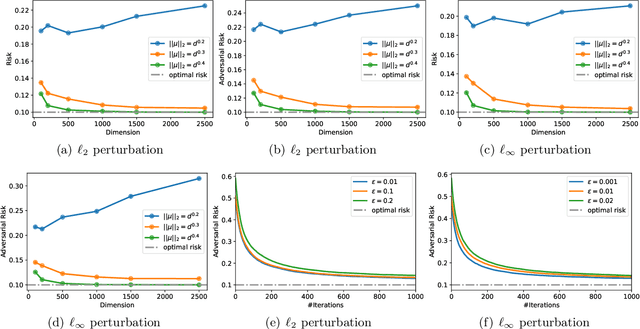
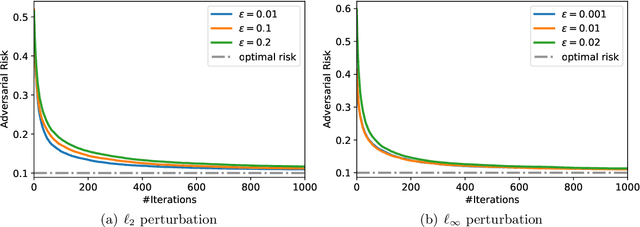
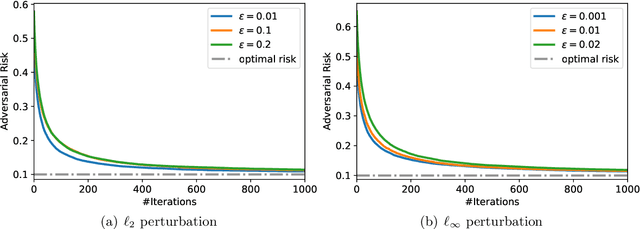
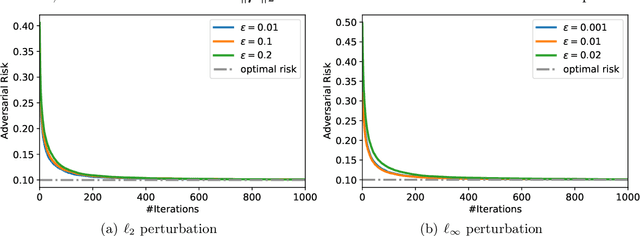
"Benign overfitting", where classifiers memorize noisy training data yet still achieve a good generalization performance, has drawn great attention in the machine learning community. To explain this surprising phenomenon, a series of works have provided theoretical justification in over-parameterized linear regression, classification, and kernel methods. However, it is not clear if benign overfitting still occurs in the presence of adversarial examples, i.e., examples with tiny and intentional perturbations to fool the classifiers. In this paper, we show that benign overfitting indeed occurs in adversarial training, a principled approach to defend against adversarial examples. In detail, we prove the risk bounds of the adversarially trained linear classifier on the mixture of sub-Gaussian data under $\ell_p$ adversarial perturbations. Our result suggests that under moderate perturbations, adversarially trained linear classifiers can achieve the near-optimal standard and adversarial risks, despite overfitting the noisy training data. Numerical experiments validate our theoretical findings.
On the Convergence and Robustness of Adversarial Training
Dec 15, 2021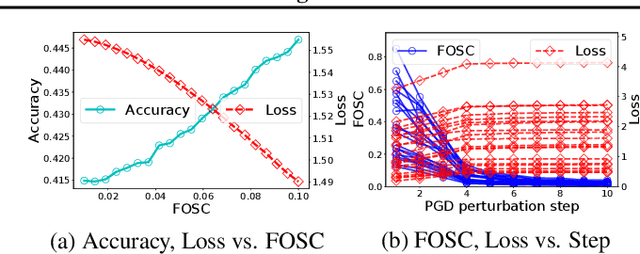

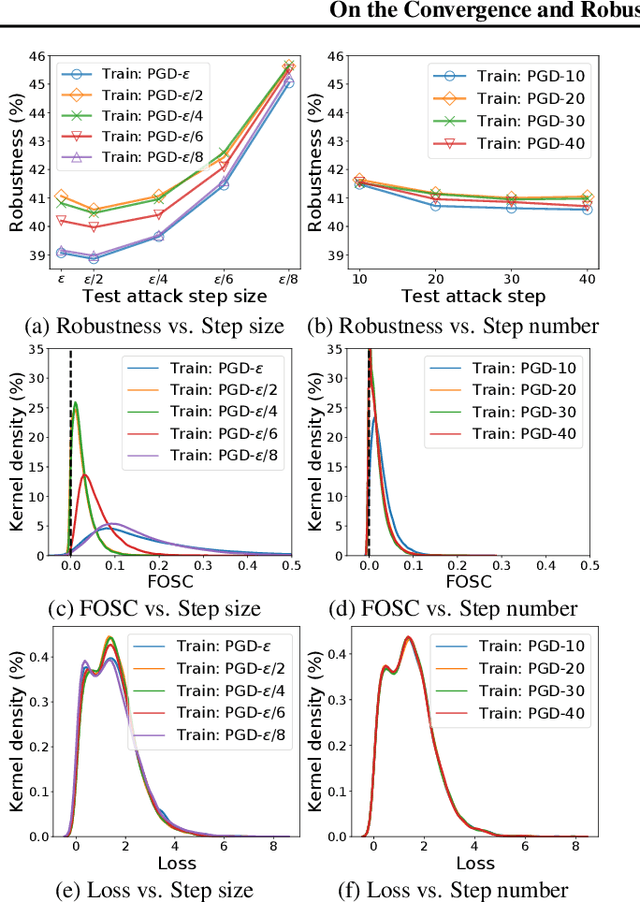

Improving the robustness of deep neural networks (DNNs) to adversarial examples is an important yet challenging problem for secure deep learning. Across existing defense techniques, adversarial training with Projected Gradient Decent (PGD) is amongst the most effective. Adversarial training solves a min-max optimization problem, with the \textit{inner maximization} generating adversarial examples by maximizing the classification loss, and the \textit{outer minimization} finding model parameters by minimizing the loss on adversarial examples generated from the inner maximization. A criterion that measures how well the inner maximization is solved is therefore crucial for adversarial training. In this paper, we propose such a criterion, namely First-Order Stationary Condition for constrained optimization (FOSC), to quantitatively evaluate the convergence quality of adversarial examples found in the inner maximization. With FOSC, we find that to ensure better robustness, it is essential to use adversarial examples with better convergence quality at the \textit{later stages} of training. Yet at the early stages, high convergence quality adversarial examples are not necessary and may even lead to poor robustness. Based on these observations, we propose a \textit{dynamic} training strategy to gradually increase the convergence quality of the generated adversarial examples, which significantly improves the robustness of adversarial training. Our theoretical and empirical results show the effectiveness of the proposed method.
Learning Stochastic Shortest Path with Linear Function Approximation
Oct 25, 2021
We study the stochastic shortest path (SSP) problem in reinforcement learning with linear function approximation, where the transition kernel is represented as a linear mixture of unknown models. We call this class of SSP problems the linear mixture SSP. We propose a novel algorithm for learning the linear mixture SSP, which can attain a $\tilde O(d B_{\star}^{1.5}\sqrt{K/c_{\min}})$ regret. Here $K$ is the number of episodes, $d$ is the dimension of the feature mapping in the mixture model, $B_{\star}$ bounds the expected cumulative cost of the optimal policy, and $c_{\min}>0$ is the lower bound of the cost function. Our algorithm also applies to the case when $c_{\min} = 0$, where a $\tilde O(K^{2/3})$ regret is guaranteed. To the best of our knowledge, this is the first algorithm with a sublinear regret guarantee for learning linear mixture SSP. In complement to the regret upper bounds, we also prove a lower bound of $\Omega(d B_{\star} \sqrt{K})$, which nearly matches our upper bound.