 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGTuner: Efficient Hyper-parameter Search for Knowledge Graph Learning
May 05, 2022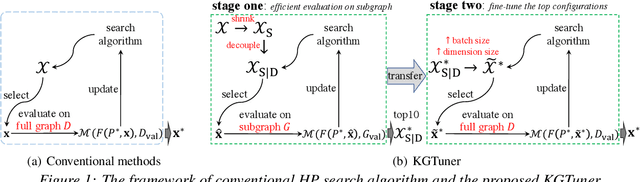
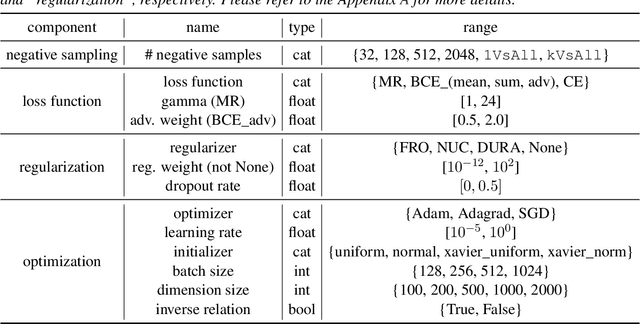
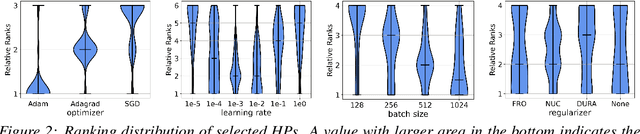

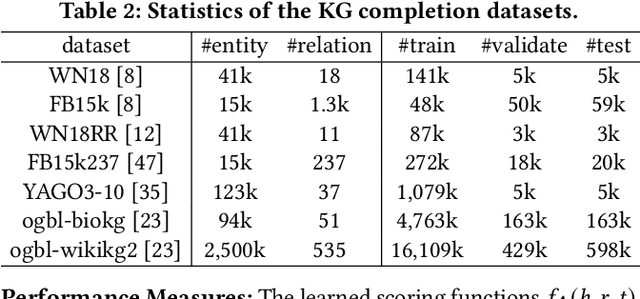
While hyper-parameters (HPs) are important for knowledge graph (KG) learning, existing methods fail to search them efficiently. To solve this problem, we first analyze the properties of different HPs and measure the transfer ability from small subgraph to the full graph. Based on the analysis, we propose an efficient two-stage search algorithm KGTuner, which efficiently explores HP configurations on small subgraph at the first stage and transfers the top-performed configurations for fine-tuning on the large full graph at the second stage. Experiments show that our method can consistently find better HPs than the baseline algorithms within the same time budget, which achieves {9.1\%} average relative improvement for four embedding models on the large-scale KGs in open graph benchmark.
Bridging the Gap of AutoGraph between Academia and Industry: Analysing AutoGraph Challenge at KDD Cup 2020
Apr 06, 2022
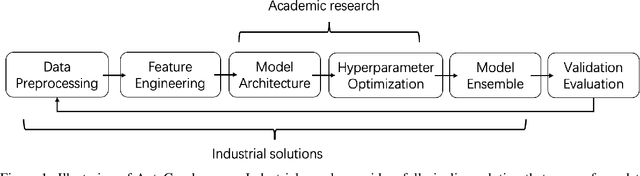

Graph structured data is ubiquitous in daily life and scientific areas and has attracted increasing attention. Graph Neural Networks (GNNs) have been proved to be effective in modeling graph structured data and many variants of GNN architectures have been proposed. However, much human effort is often needed to tune the architecture depending on different datasets. Researchers naturally adopt Automated Machine Learning on Graph Learning, aiming to reduce the human effort and achieve generally top-performing GNNs, but their methods focus more on the architecture search. To understand GNN practitioners' automated solutions, we organized AutoGraph Challenge at KDD Cup 2020, emphasizing on automated graph neural networks for node classification. We received top solutions especially from industrial tech companies like Meituan, Alibaba and Twitter, which are already open sourced on Github. After detailed comparisons with solutions from academia, we quantify the gaps between academia and industry on modeling scope, effectiveness and efficiency, and show that (1) academia AutoML for Graph solutions focus on GNN architecture search while industrial solutions, especially the winning ones in the KDD Cup, tend to obtain an overall solution (2) by neural architecture search only, academia solutions achieve on average 97.3% accuracy of industrial solutions (3) academia solutions are cheap to obtain with several GPU hours while industrial solutions take a few months' labors. Academic solutions also contain much fewer parameters.
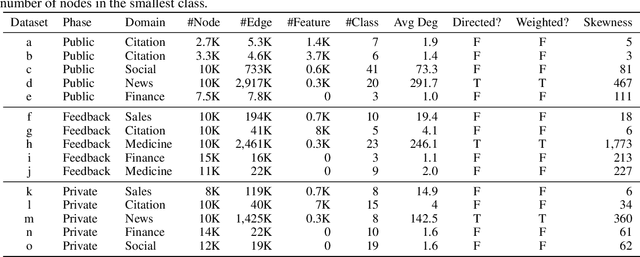
LoSAC: An Efficient Local Stochastic Average Control Method for Federated Optimization
Dec 20, 2021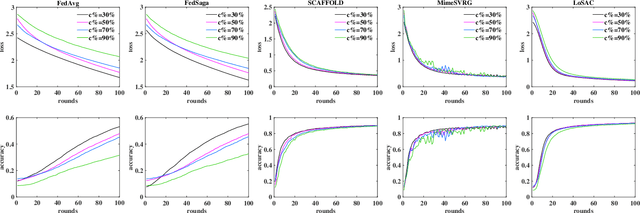
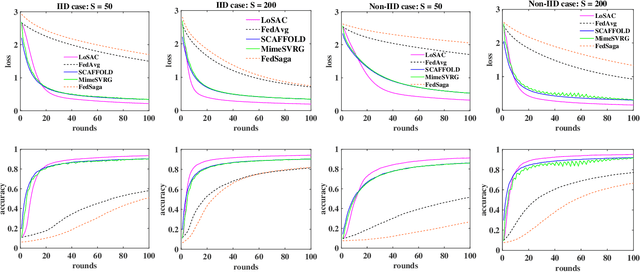
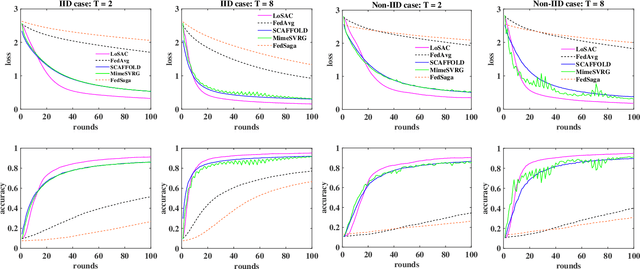
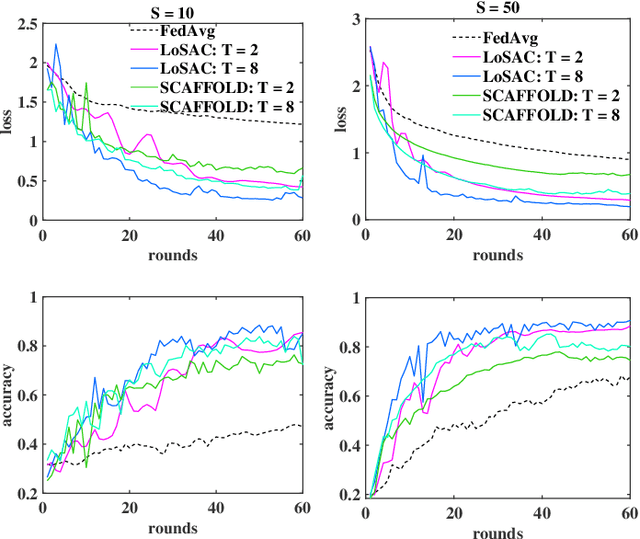
Federated optimization (FedOpt), which targets at collaboratively training a learning model across a large number of distributed clients, is vital for federated learning. The primary concerns in FedOpt can be attributed to the model divergence and communication efficiency, which significantly affect the performance. In this paper, we propose a new method, i.e., LoSAC, to learn from heterogeneous distributed data more efficiently. Its key algorithmic insight is to locally update the estimate for the global full gradient after {each} regular local model update. Thus, LoSAC can keep clients' information refreshed in a more compact way. In particular, we have studied the convergence result for LoSAC. Besides, the bonus of LoSAC is the ability to defend the information leakage from the recent technique Deep Leakage Gradients (DLG). Finally, experiments have verified the superiority of LoSAC comparing with state-of-the-art FedOpt algorithms. Specifically, LoSAC significantly improves communication efficiency by more than $100\%$ on average, mitigates the model divergence problem and equips with the defense ability against DLG.
Hierarchical Heterogeneous Graph Representation Learning for Short Text Classification
Oct 30, 2021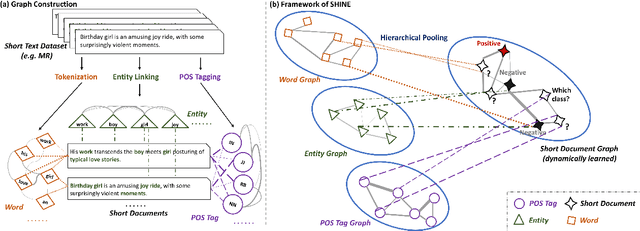
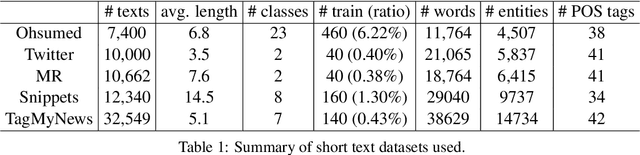
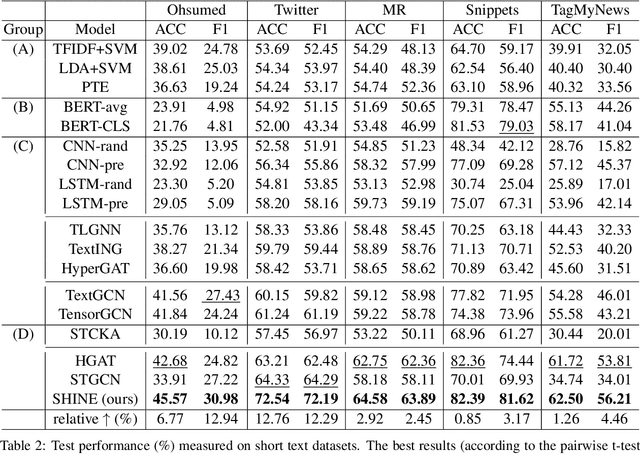
Short text classification is a fundamental task in natural language processing. It is hard due to the lack of context information and labeled data in practice. In this paper, we propose a new method called SHINE, which is based on graph neural network (GNN), for short text classification. First, we model the short text dataset as a hierarchical heterogeneous graph consisting of word-level component graphs which introduce more semantic and syntactic information. Then, we dynamically learn a short document graph that facilitates effective label propagation among similar short texts. Thus, compared with existing GNN-based methods, SHINE can better exploit interactions between nodes of the same types and capture similarities between short texts. Extensive experiments on various benchmark short text datasets show that SHINE consistently outperforms state-of-the-art methods, especially with fewer labels.
Pooling Architecture Search for Graph Classification
Aug 24, 2021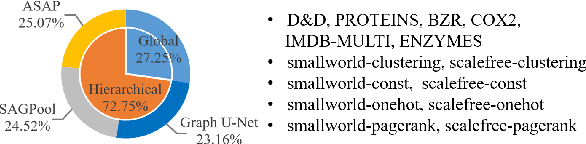
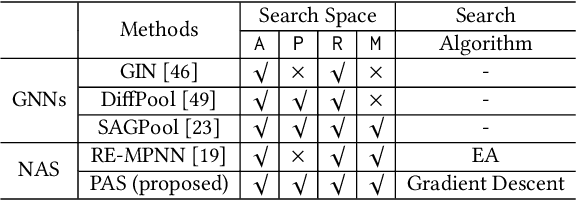
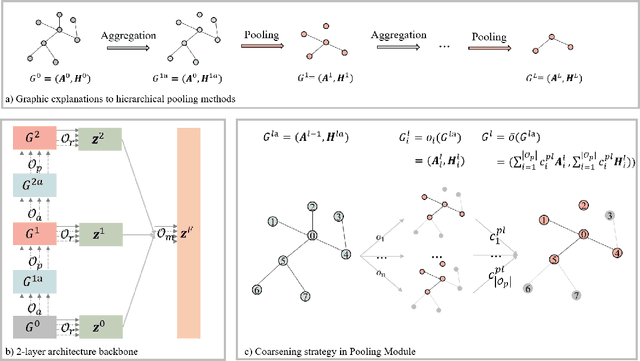
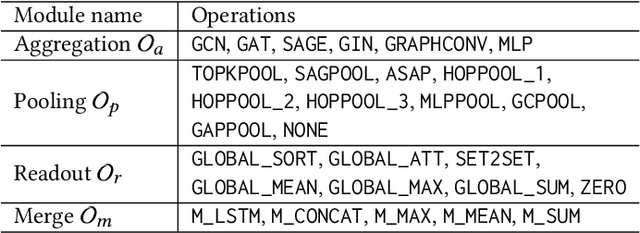
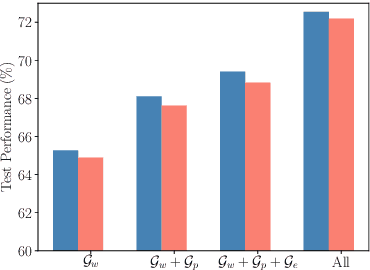
Graph classification is an important problem with applications across many domains, like chemistry and bioinformatics, for which graph neural networks (GNNs) have been state-of-the-art (SOTA) methods. GNNs are designed to learn node-level representation based on neighborhood aggregation schemes, and to obtain graph-level representation, pooling methods are applied after the aggregation operation in existing GNN models to generate coarse-grained graphs. However,due to highly diverse applications of graph classification, and the performance of existing pooling methods vary on different graphs. In other words, it is a challenging problem to design a universal pooling architecture to perform well in most cases, leading to a demand for data-specific pooling methods in real-world applications. To address this problem, we propose to use neural architecture search (NAS) to search for adaptive pooling architectures for graph classification. Firstly we designed a unified framework consisting of four modules: Aggregation, Pooling, Readout, and Merge, which can cover existing human-designed pooling methods for graph classification. Based on this framework, a novel search space is designed by incorporating popular operations in human-designed architectures. Then to enable efficient search, a coarsening strategy is proposed to continuously relax the search space, thus a differentiable search method can be adopted. Extensive experiments on six real-world datasets from three domains are conducted, and the results demonstrate the effectiveness and efficiency of the proposed framework.
TabGNN: Multiplex Graph Neural Network for Tabular Data Prediction
Aug 20, 2021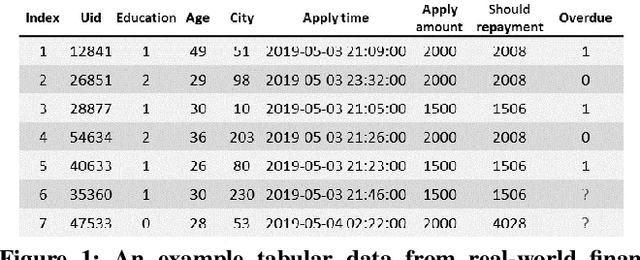
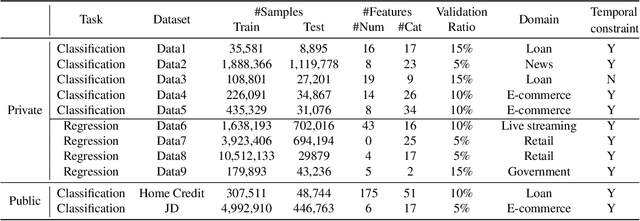
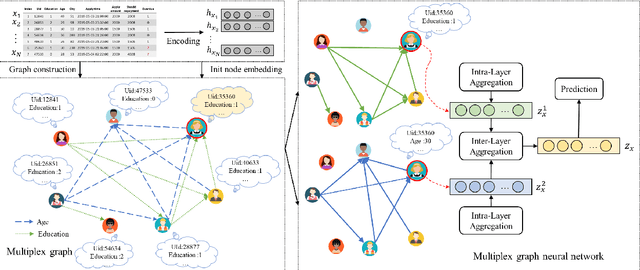
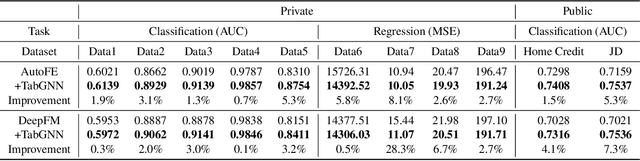
Tabular data prediction (TDP) is one of the most popular industrial applications, and various methods have been designed to improve the prediction performance. However, existing works mainly focus on feature interactions and ignore sample relations, e.g., users with the same education level might have a similar ability to repay the debt. In this work, by explicitly and systematically modeling sample relations, we propose a novel framework TabGNN based on recently popular graph neural networks (GNN). Specifically, we firstly construct a multiplex graph to model the multifaceted sample relations, and then design a multiplex graph neural network to learn enhanced representation for each sample. To integrate TabGNN with the tabular solution in our company, we concatenate the learned embeddings and the original ones, which are then fed to prediction models inside the solution. Experiments on eleven TDP datasets from various domains, including classification and regression ones, show that TabGNN can consistently improve the performance compared to the tabular solution AutoFE in 4Paradigm.
Knowledge Graph Reasoning with Relational Directed Graph
Aug 13, 2021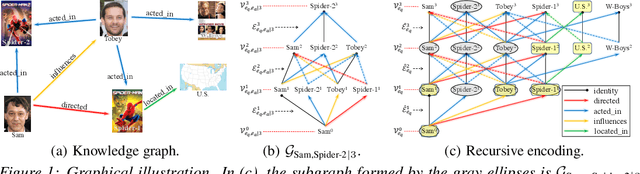
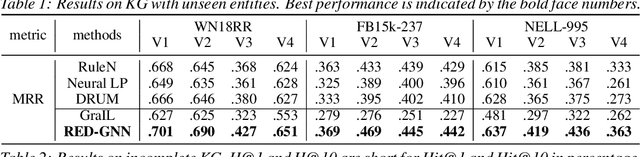
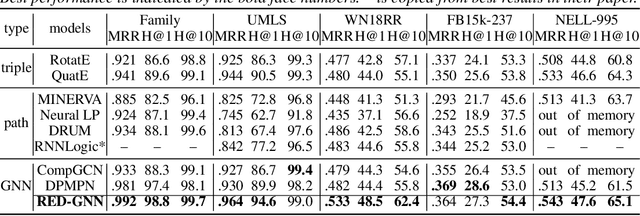
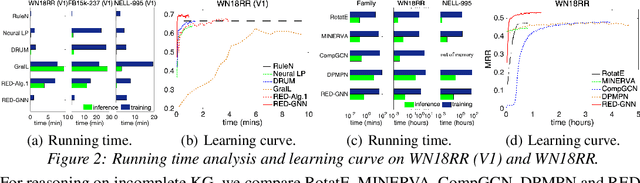
Reasoning on the knowledge graph (KG) aims to infer new facts from existing ones. Methods based on the relational path in the literature have shown strong, interpretable, and inductive reasoning ability. However, the paths are naturally limited in capturing complex topology in KG. In this paper, we introduce a novel relational structure, i.e., relational directed graph (r-digraph), which is composed of overlapped relational paths, to capture the KG's structural information. Since the digraph exhibits more complex structure than paths, constructing and learning on the r-digraph are challenging. Here, we propose a variant of graph neural network, i.e., RED-GNN, to address the above challenges by learning the RElational Digraph with a variant of GNN. Specifically, RED-GNN recursively encodes multiple r-digraphs with shared edges and selects the strongly correlated edges through query-dependent attention weights. We demonstrate the significant gains on reasoning both KG with unseen entities and incompletion KG benchmarks by the r-digraph, the efficiency of RED-GNN, and the interpretable dependencies learned on the r-digraph.
AutoSF+: Towards Automatic Scoring Function Design for Knowledge Graph Embedding
Jul 01, 2021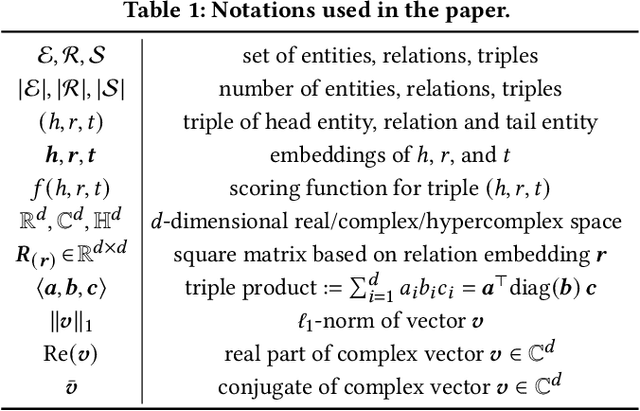
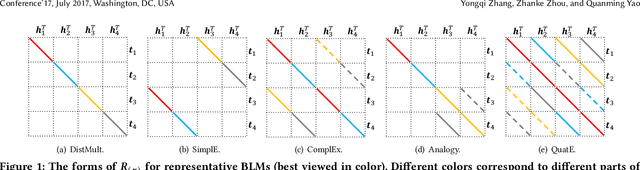
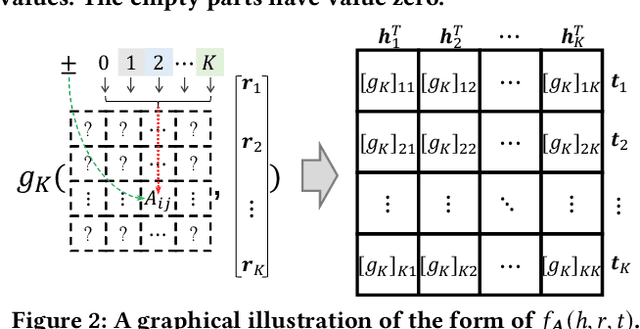
Scoring functions, which measure the plausibility of triples, have become the crux of knowledge graph embedding (KGE). Plenty of scoring functions, targeting at capturing different kinds of relations in KGs, have been designed by experts in recent years. However, as relations can exhibit intricate patterns that are hard to infer before training, none of them can consistently perform the best on existing benchmark tasks. AutoSF has shown the significance of using automated machine learning (AutoML) to design KG- dependent scoring functions. In this paper, we propose AutoSF+ as an extension of AutoSF. First, we improve the search algorithm with the evolutionary search, which can better explore the search space. Second, we evaluate AutoSF+ on the recently developed benchmark OGB. Besides, we apply AutoSF+ to the new task, i.e., entity classification, to show that it can improve the task beyond KG completion.
Efficient Data-specific Model Search for Collaborative Filtering
Jun 14, 2021
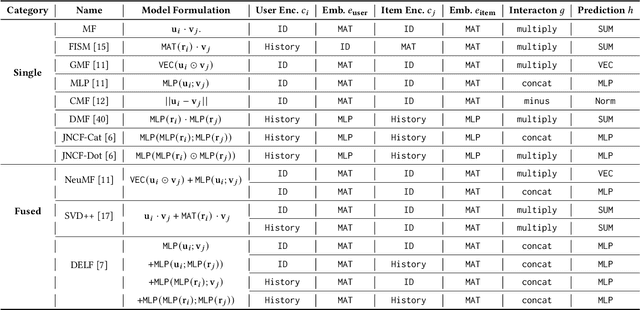
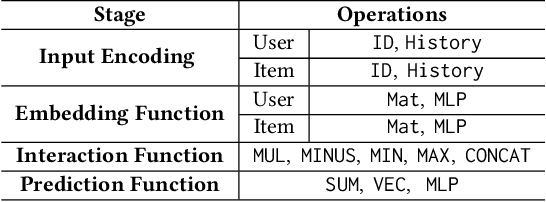
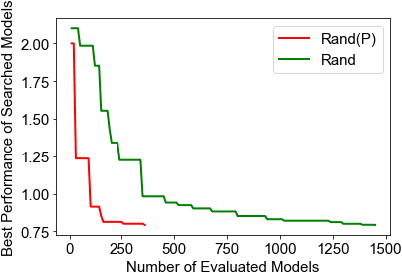
Collaborative filtering (CF), as a fundamental approach for recommender systems, is usually built on the latent factor model with learnable parameters to predict users' preferences towards items. However, designing a proper CF model for a given data is not easy, since the properties of datasets are highly diverse. In this paper, motivated by the recent advances in automated machine learning (AutoML), we propose to design a data-specific CF model by AutoML techniques. The key here is a new framework that unifies state-of-the-art (SOTA) CF methods and splits them into disjoint stages of input encoding, embedding function, interaction function, and prediction function. We further develop an easy-to-use, robust, and efficient search strategy, which utilizes random search and a performance predictor for efficient searching within the above framework. In this way, we can combinatorially generalize data-specific CF models, which have not been visited in the literature, from SOTA ones. Extensive experiments on five real-world datasets demonstrate that our method can consistently outperform SOTA ones for various CF tasks. Further experiments verify the rationality of the proposed framework and the efficiency of the search strategy. The searched CF models can also provide insights for exploring more effective methods in the future
Efficient Relation-aware Scoring Function Search for Knowledge Graph Embedding
Apr 22, 2021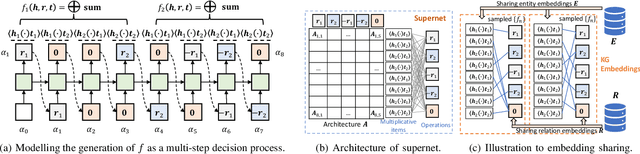
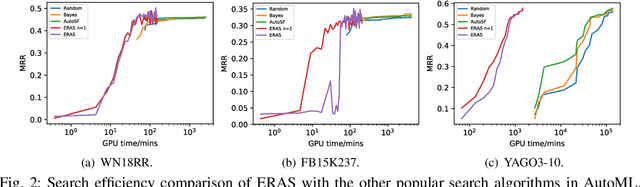
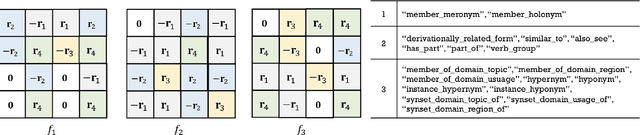
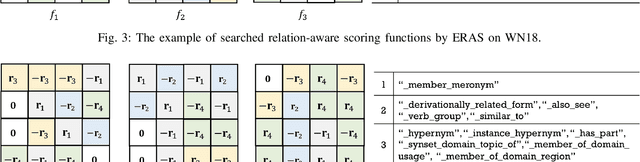
The scoring function, which measures the plausibility of triplets in knowledge graphs (KGs), is the key to ensure the excellent performance of KG embedding, and its design is also an important problem in the literature. Automated machine learning (AutoML) techniques have recently been introduced into KG to design task-aware scoring functions, which achieve state-of-the-art performance in KG embedding. However, the effectiveness of searched scoring functions is still not as good as desired. In this paper, observing that existing scoring functions can exhibit distinct performance on different semantic patterns, we are motivated to explore such semantics by searching relation-aware scoring functions. But the relation-aware search requires a much larger search space than the previous one. Hence, we propose to encode the space as a supernet and propose an efficient alternative minimization algorithm to search through the supernet in a one-shot manner. Finally, experimental results on benchmark datasets demonstrate that the proposed method can efficiently search relation-aware scoring functions, and achieve better embedding performance than state-of-the-art methods.