 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Backbone Search for Scene Text Recognition
Paper and Code


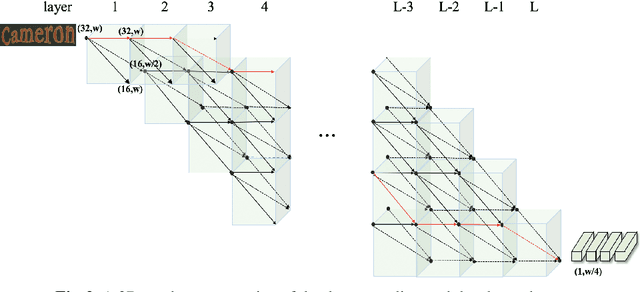
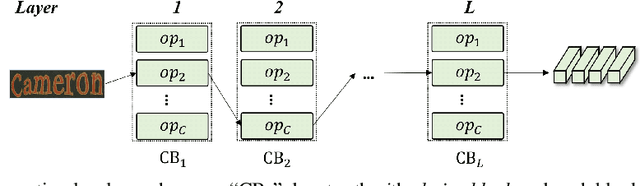
Scene text recognition (STR) is very challenging due to the diversity of text instances and the complexity of scenes. The community has paid increasing attention to boost the performance by improving the pre-processing image module, like rectification and deblurring, or the sequence translator. However, another critical module, i.e., the feature sequence extractor, has not been extensively explored. In this work, inspired by the success of neural architecture search (NAS), which can identify better architectures than human-designed ones, we propose automated STR (AutoSTR) to search data-dependent backbones to boost text recognition performance. First, we design a domain-specific search space for STR, which contains both choices on operations and constraints on the downsampling path. Then, we propose a two-step search algorithm, which decouples operations and downsampling path, for an efficient search in the given space. Experiments demonstrate that, by searching data-dependent backbones, AutoSTR can outperform the state-of-the-art approaches on standard benchmarks with much fewer FLOPS and model parameters.