 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteLMT: Learned Sample Routing for Hybrid LLM Translation Deployment
Apr 24, 2026Large Language Models (LLMs) have achieved remarkable performance in Machine Translation (MT), but deploying them at scale remains prohibitively expensive. A widely adopted remedy is the hybrid system paradigm, which balances cost and quality by serving most requests with a small model and selectively routing a fraction to a large model. However, existing routing strategies often rely on heuristics, external predictors, or absolute quality estimation, which fail to capture whether the large model actually provides a worthwhile improvement over the small one. In this paper, we formulate routing as a budget allocation problem and identify marginal gain, i.e., the large model's improvement over the small model, as the optimal signal for budgeted decisions. Building on this, we propose \textbf{RouteLMT} (routing for LLM-based MT), an efficient in-model router that predicts this expected gain by probing the small translators prompt-token representation, without requiring external models or hypothesis decoding. Extensive experiments demonstrate that our RouteLMT outperforms heuristics, quality/difficulty estimation baselines, achieving a superior quality-budget Pareto frontier. Furthermore, we analyze regression risks and show that a simple guarded variant can mitigate severe quality losses.
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Nov 10, 2025



Large language models have significantly advanced Multilingual Machine Translation (MMT), yet the broad language coverage, consistent translation quality, and English-centric bias remain open challenges. To address these challenges, we introduce \textbf{LMT}, a suite of \textbf{L}arge-scale \textbf{M}ultilingual \textbf{T}ranslation models centered on both Chinese and English, covering 60 languages and 234 translation directions. During development, we identify a previously overlooked phenomenon of \textbf{directional degeneration}, where symmetric multi-way fine-tuning data overemphasize reverse directions (X $\to$ En/Zh), leading to excessive many-to-one mappings and degraded translation quality. We propose \textbf{Strategic Downsampling}, a simple yet effective method to mitigate this degeneration. In addition, we design \textbf{Parallel Multilingual Prompting (PMP)}, which leverages typologically related auxiliary languages to enhance cross-lingual transfer. Through rigorous data curation and refined adaptation strategies, LMT achieves SOTA performance among models of comparable language coverage, with our 4B model (LMT-60-4B) surpassing the much larger Aya-101-13B and NLLB-54B models by a substantial margin. We release LMT in four sizes (0.6B/1.7B/4B/8B) to catalyze future research and provide strong baselines for inclusive, scalable, and high-quality MMT \footnote{\href{https://github.com/NiuTrans/LMT}{https://github.com/NiuTrans/LMT}}.
LaTeXTrans: Structured LaTeX Translation with Multi-Agent Coordination
Aug 26, 2025Despite the remarkable progress of modern machine translation (MT) systems on general-domain texts, translating structured LaTeX-formatted documents remains a significant challenge. These documents typically interleave natural language with domain-specific syntax, such as mathematical equations, tables, figures, and cross-references, all of which must be accurately preserved to maintain semantic integrity and compilability. In this paper, we introduce LaTeXTrans, a collaborative multi-agent system designed to address this challenge. LaTeXTrans ensures format preservation, structural fidelity, and terminology consistency through six specialized agents: 1) a Parser that decomposes LaTeX into translation-friendly units via placeholder substitution and syntax filtering; 2) a Translator, Validator, Summarizer, and Terminology Extractor that work collaboratively to ensure context-aware, self-correcting, and terminology-consistent translations; 3) a Generator that reconstructs the translated content into well-structured LaTeX documents. Experimental results demonstrate that LaTeXTrans can outperform mainstream MT systems in both translation accuracy and structural fidelity, offering an effective and practical solution for translating LaTeX-formatted documents.
RoVRM: A Robust Visual Reward Model Optimized via Auxiliary Textual Preference Data
Aug 22, 2024



Large vision-language models (LVLMs) often fail to align with human preferences, leading to issues like generating misleading content without proper visual context (also known as hallucination). A promising solution to this problem is using human-preference alignment techniques, such as best-of-n sampling and reinforcement learning. However, these techniques face the difficulty arising from the scarcity of visual preference data, which is required to train a visual reward model (VRM). In this work, we continue the line of research. We present a Robust Visual Reward Model (RoVRM) which improves human-preference alignment for LVLMs. RoVRM leverages auxiliary textual preference data through a three-phase progressive training and optimal transport-based preference data selection to effectively mitigate the scarcity of visual preference data. We experiment with RoVRM on the commonly used vision-language tasks based on the LLaVA-1.5-7B and -13B models. Experimental results demonstrate that RoVRM consistently outperforms traditional VRMs. Furthermore, our three-phase progressive training and preference data selection approaches can yield consistent performance gains over ranking-based alignment techniques, such as direct preference optimization.
Learning Evaluation Models from Large Language Models for Sequence Generation
Aug 08, 2023



Large language models achieve state-of-the-art performance on sequence generation evaluation, but typically have a large number of parameters. This is a computational challenge as presented by applying their evaluation capability at scale. To overcome the challenge, in this paper, we propose \textbf{ECT}, an \textbf{e}valuation \textbf{c}apability \textbf{t}ransfer method, to transfer the evaluation capability from LLMs to relatively lightweight language models. Based on the proposed ECT, we learn various evaluation models from ChatGPT, and employ them as reward models to improve sequence generation models via reinforcement learning and reranking approaches. Experimental results on machine translation, text style transfer, and summarization tasks demonstrate the effectiveness of our ECT. Notably, applying the learned evaluation models to sequence generation models results in better generated sequences as evaluated by commonly used metrics and ChatGPT.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Sequence Generation
Mar 17, 2022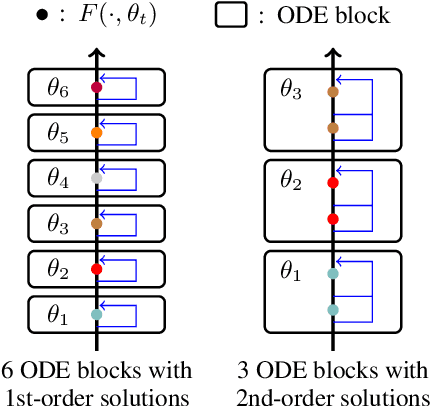
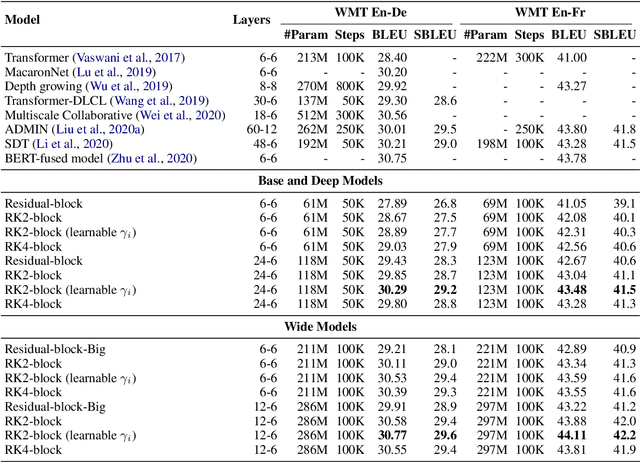
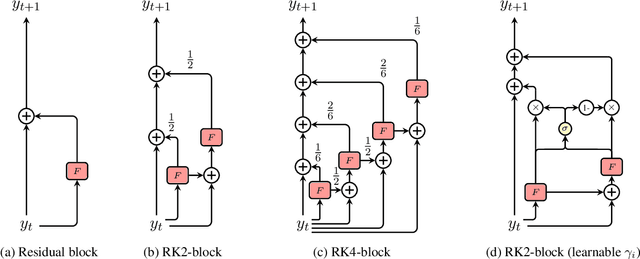
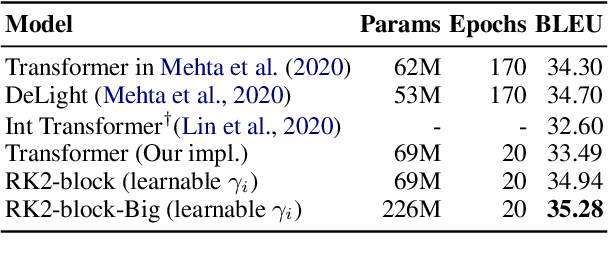
Residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODE). This paper explores a deeper relationship between Transformer and numerical ODE methods. We first show that a residual block of layers in Transformer can be described as a higher-order solution to ODE. Inspired by this, we design a new architecture, {\it ODE Transformer}, which is analogous to the Runge-Kutta method that is well motivated in ODE. As a natural extension to Transformer, ODE Transformer is easy to implement and efficient to use. Experimental results on the large-scale machine translation, abstractive summarization, and grammar error correction tasks demonstrate the high genericity of ODE Transformer. It can gain large improvements in model performance over strong baselines (e.g., 30.77 and 44.11 BLEU scores on the WMT'14 English-German and English-French benchmarks) at a slight cost in inference efficiency.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Neural Machine Translation
Apr 06, 2021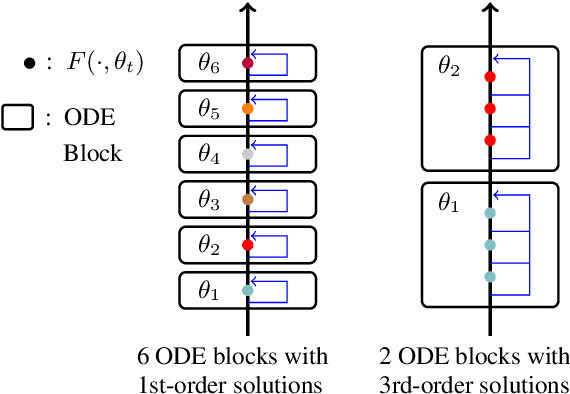
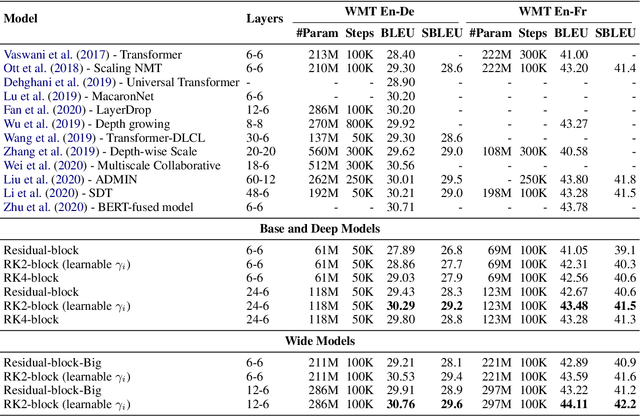
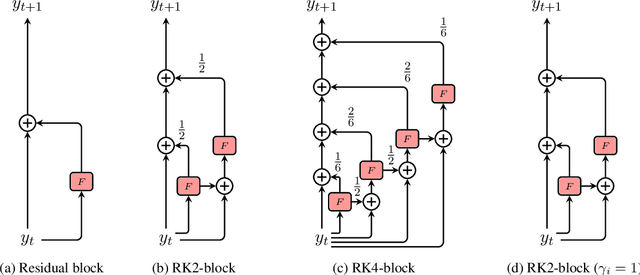
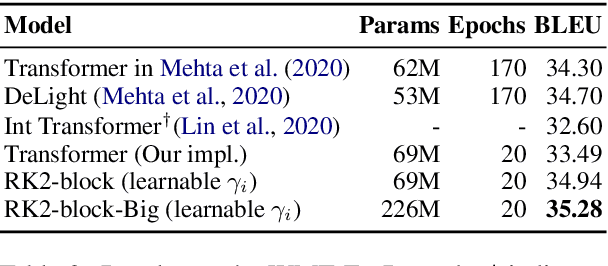
It has been found that residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODEs). In this paper, we explore a deeper relationship between Transformer and numerical methods of ODEs. We show that a residual block of layers in Transformer can be described as a higher-order solution to ODEs. This leads us to design a new architecture (call it ODE Transformer) analogous to the Runge-Kutta method that is well motivated in ODEs. As a natural extension to Transformer, ODE Transformer is easy to implement and parameter efficient. Our experiments on three WMT tasks demonstrate the genericity of this model, and large improvements in performance over several strong baselines. It achieves 30.76 and 44.11 BLEU scores on the WMT'14 En-De and En-Fr test data. This sets a new state-of-the-art on the WMT'14 En-Fr task.
Learning Light-Weight Translation Models from Deep Transformer
Dec 27, 2020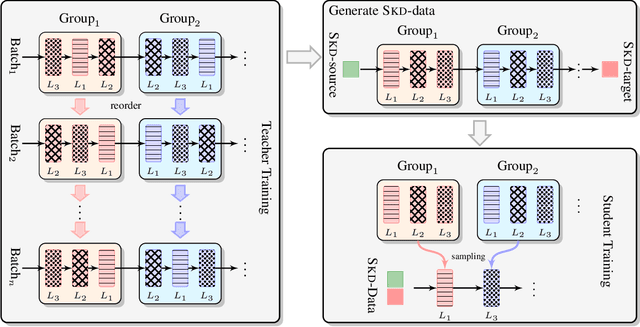
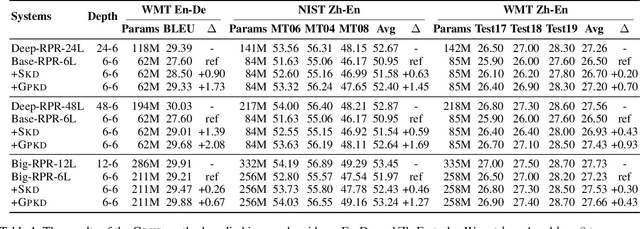
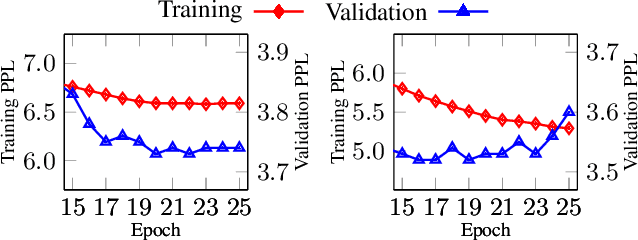
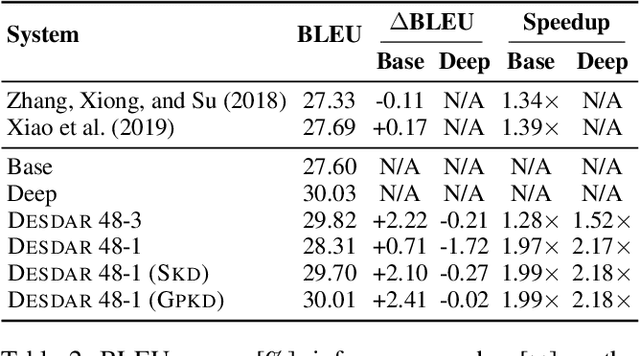
Recently, deep models have shown tremendous improvements in neural machine translation (NMT). However, systems of this kind are computationally expensive and memory intensive. In this paper, we take a natural step towards learning strong but light-weight NMT systems. We proposed a novel group-permutation based knowledge distillation approach to compressing the deep Transformer model into a shallow model. The experimental results on several benchmarks validate the effectiveness of our method. Our compressed model is 8X shallower than the deep model, with almost no loss in BLEU. To further enhance the teacher model, we present a Skipping Sub-Layer method to randomly omit sub-layers to introduce perturbation into training, which achieves a BLEU score of 30.63 on English-German newstest2014. The code is publicly available at https://github.com/libeineu/GPKD.
A Simple and Effective Approach to Robust Unsupervised Bilingual Dictionary Induction
Nov 30, 2020
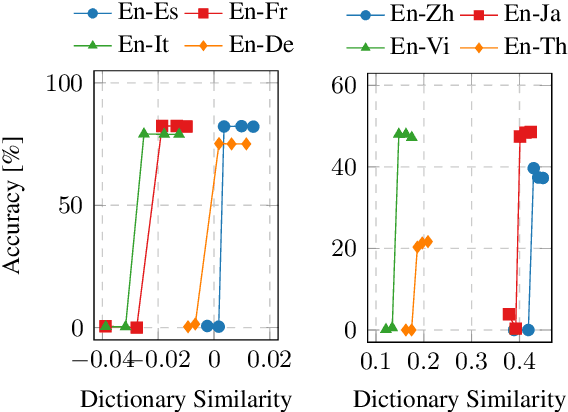
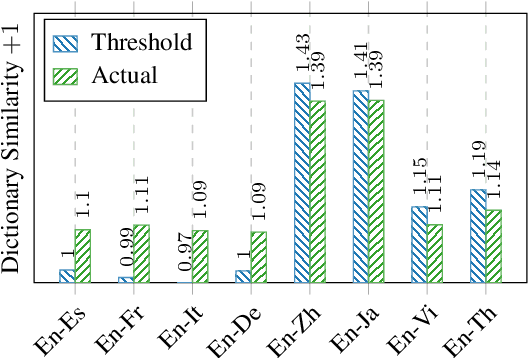

Unsupervised Bilingual Dictionary Induction methods based on the initialization and the self-learning have achieved great success in similar language pairs, e.g., English-Spanish. But they still fail and have an accuracy of 0% in many distant language pairs, e.g., English-Japanese. In this work, we show that this failure results from the gap between the actual initialization performance and the minimum initialization performance for the self-learning to succeed. We propose Iterative Dimension Reduction to bridge this gap. Our experiments show that this simple method does not hamper the performance of similar language pairs and achieves an accuracy of 13.64~55.53% between English and four distant languages, i.e., Chinese, Japanese, Vietnamese and Thai.
Shallow-to-Deep Training for Neural Machine Translation
Oct 08, 2020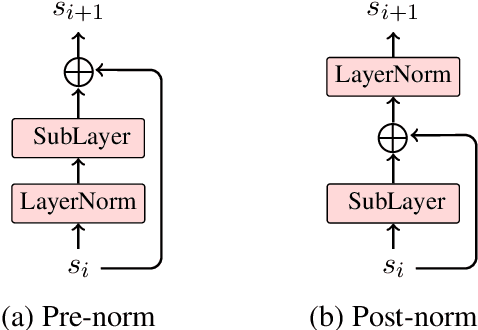
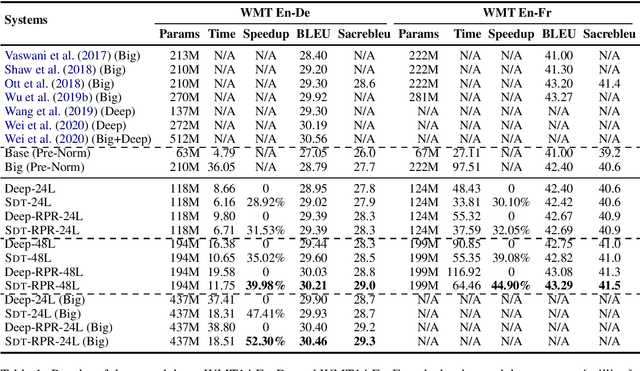
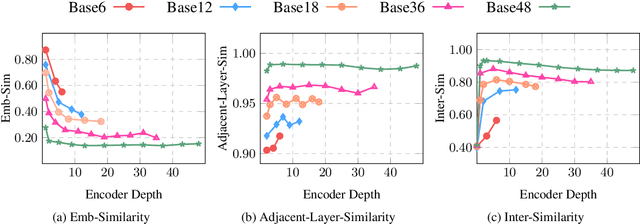

Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but training an extremely deep encoder is time consuming. Moreover, why deep models help NMT is an open question. In this paper, we investigate the behavior of a well-tuned deep Transformer system. We find that stacking layers is helpful in improving the representation ability of NMT models and adjacent layers perform similarly. This inspires us to develop a shallow-to-deep training method that learns deep models by stacking shallow models. In this way, we successfully train a Transformer system with a 54-layer encoder. Experimental results on WMT'16 English-German and WMT'14 English-French translation tasks show that it is $1.4$ $\times$ faster than training from scratch, and achieves a BLEU score of $30.33$ and $43.29$ on two tasks. The code is publicly available at https://github.com/libeineu/SDT-Training/.