 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaPT: A Dual-Path Framework for Multilingual Multi-hop Question Answering
Mar 19, 2026Retrieval-augmented generation (RAG) systems have made significant progress in solving complex multi-hop question answering (QA) tasks in the English scenario. However, RAG systems inevitably face the application scenario of retrieving across multilingual corpora and queries, leaving several open challenges. The first one involves the absence of benchmarks that assess RAG systems' capabilities under the multilingual multi-hop (MM-hop) QA setting. The second centers on the overreliance on LLMs' strong semantic understanding in English, which diminishes effectiveness in multilingual scenarios. To address these challenges, we first construct multilingual multi-hop QA benchmarks by translating English-only benchmarks into five languages, and then we propose DaPT, a novel multilingual RAG framework. DaPT generates sub-question graphs in parallel for both the source-language query and its English translation counterpart, then merges them before employing a bilingual retrieval-and-answer strategy to sequentially solve sub-questions. Our experimental results demonstrate that advanced RAG systems suffer from a significant performance imbalance in multilingual scenarios. Furthermore, our proposed method consistently yields more accurate and concise answers compared to the baselines, significantly enhancing RAG performance on this task. For instance, on the most challenging MuSiQue benchmark, DaPT achieves a relative improvement of 18.3\% in average EM score over the strongest baseline.
When Scaling Fails: Mitigating Audio Perception Decay of LALMs via Multi-Step Perception-Aware Reasoning
Feb 28, 2026Test-Time Scaling has shown notable efficacy in addressing complex problems through scaling inference compute. However, within Large Audio-Language Models (LALMs), an unintuitive phenomenon exists: post-training models for structured reasoning trajectories results in marginal or even negative gains compared to post-training for direct answering. To investigate it, we introduce CAFE, an evaluation framework designed to precisely quantify audio reasoning errors. Evaluation results reveal LALMs struggle with perception during reasoning and encounter a critical bottleneck: reasoning performance suffers from audio perception decay as reasoning length extends. To address it, we propose MPAR$^2$, a paradigm that encourages dynamic perceptual reasoning and decomposes complex questions into perception-rich sub-problems. Leveraging reinforcement learning, MPAR$^2$ improves perception performance on CAFE from 31.74% to 63.51% and effectively mitigates perception decay, concurrently enhancing reasoning capabilities to achieve a significant 74.59% accuracy on the MMAU benchmark. Further analysis demonstrates that MPAR$^2$ reinforces LALMs to attend to audio input and dynamically adapts reasoning budget to match task complexity.
LaTeXTrans: Structured LaTeX Translation with Multi-Agent Coordination
Aug 26, 2025Despite the remarkable progress of modern machine translation (MT) systems on general-domain texts, translating structured LaTeX-formatted documents remains a significant challenge. These documents typically interleave natural language with domain-specific syntax, such as mathematical equations, tables, figures, and cross-references, all of which must be accurately preserved to maintain semantic integrity and compilability. In this paper, we introduce LaTeXTrans, a collaborative multi-agent system designed to address this challenge. LaTeXTrans ensures format preservation, structural fidelity, and terminology consistency through six specialized agents: 1) a Parser that decomposes LaTeX into translation-friendly units via placeholder substitution and syntax filtering; 2) a Translator, Validator, Summarizer, and Terminology Extractor that work collaboratively to ensure context-aware, self-correcting, and terminology-consistent translations; 3) a Generator that reconstructs the translated content into well-structured LaTeX documents. Experimental results demonstrate that LaTeXTrans can outperform mainstream MT systems in both translation accuracy and structural fidelity, offering an effective and practical solution for translating LaTeX-formatted documents.
Bayesian Optimisation-Assisted Neural Network Training Technique for Radio Localisation
Mar 08, 2022
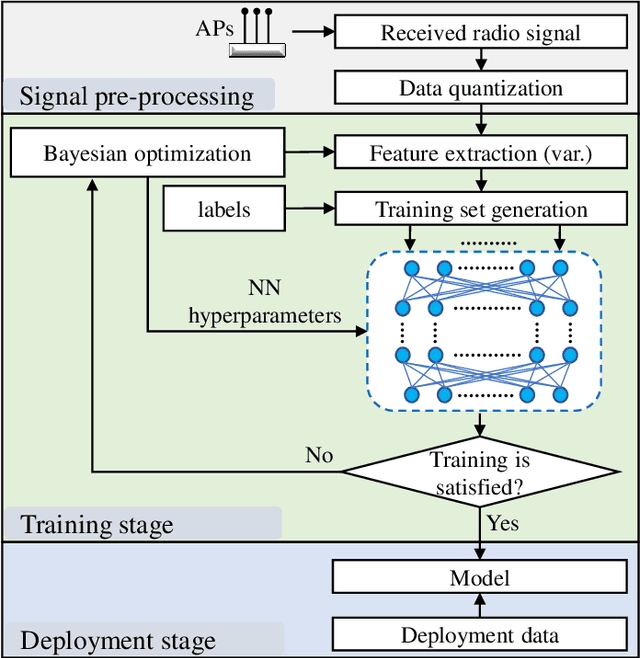
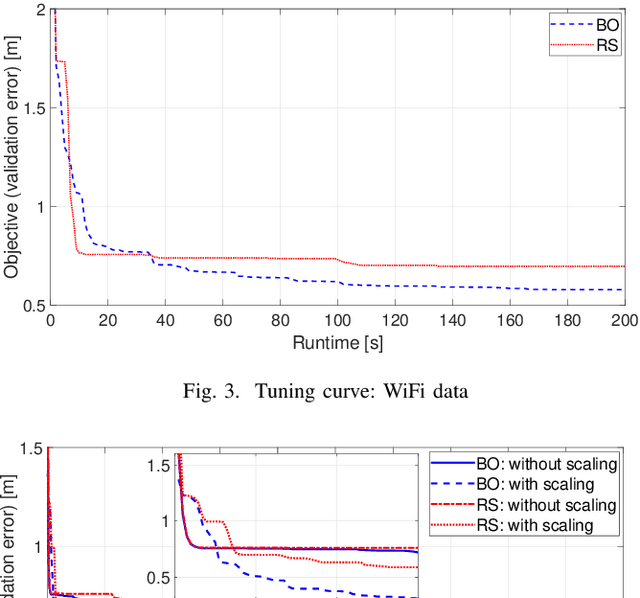
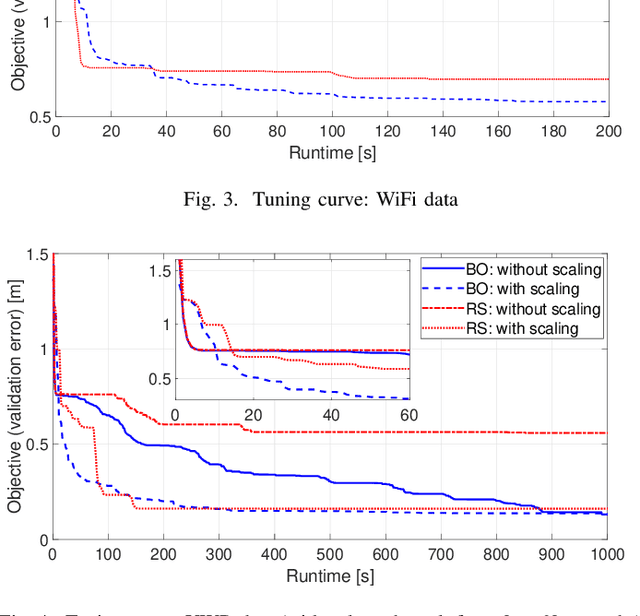
Radio signal-based (indoor) localisation technique is important for IoT applications such as smart factory and warehouse. Through machine learning, especially neural networks methods, more accurate mapping from signal features to target positions can be achieved. However, different radio protocols, such as WiFi, Bluetooth, etc., have different features in the transmitted signals that can be exploited for localisation purposes. Also, neural networks methods often rely on carefully configured models and extensive training processes to obtain satisfactory performance in individual localisation scenarios. The above poses a major challenge in the process of determining neural network model structure, or hyperparameters, as well as the selection of training features from the available data. This paper proposes a neural network model hyperparameter tuning and training method based on Bayesian optimisation. Adaptive selection of model hyperparameters and training features can be realised with minimal need for manual model training design. With the proposed technique, the training process is optimised in a more automatic and efficient way, enhancing the applicability of neural networks in localisation.