 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Open Waters to Enclosed Cabins: ProteusVPR for Cross-Scene Visual Place Recognition in Maritime Perception and Cabin Inspection
Jun 23, 2026Autonomous robotic inspection in maritime environments presents unique challenges for Visual Place Recognition (VPR) due to cross-scene perceptual shifts. Robots navigating ship-borne environments must transition between visually distinct domains: open decks with sparse textures and severe illumination changes, and enclosed cabins with repetitive structures and high visual ambiguity. Existing VPR methods, designed primarily for urban or indoor scenes, fail to generalize reliably across these starkly different scenarios. To address this, we propose ProteusVPR, a two-stage retrieval-refinement framework. The first stage employs any standard VPR model for initial image retrieval. The second stage introduces a geometric-visual estimation network that fuses the retrieved image with two temporally preceding frames, incorporating geometric descriptors, a local affine coordinate system, and camera azimuth encoding to achieve precise localization. To support this task, we introduce the XHZ dataset, an 8K-panoramic ship-borne dataset collected from an operational vessel, featuring multi-floor cabin structures, deck transition zones, and strict query-database separation for rigorous evaluation. Extensive experiments on the XHZ dataset demonstrate that ProteusVPR consistently improves the localization accuracy across multiple VPR backbones, reducing mean localization error by over 60\% on average and that ProteusVPR offers an effective and robust solution for precise visual localization in challenging, cross-scene maritime environments.
DreamX-World 1.0: A General-Purpose Interactive World Model
Jun 15, 2026DreamX-World 1.0 is a general-purpose interactive text/image-to-video world model for controllable long-horizon generation. It supports camera navigation, revisits to previously observed regions, and promptable events across photorealistic, game-style, and stylized domains. Our data engine combines camera-accurate Unreal Engine rendering, action-rich gameplay recordings, and real-world videos with recovered camera geometry. For camera control, we introduce E-PRoPE, a lightweight variant of projective positional encoding that retains PRoPE's projective camera geometry while applying camera-aware attention to spatially reduced tokens. We convert a bidirectional video generator into a few-step autoregressive world model using causal forcing, DMD-style distillation, and long-rollout training. Training on self-generated long-horizon contexts exposes the model to its own generated history and reduces the style and color drift that accumulates across autoregressive chunks. Memory-Conditioned Scene Persistence retrieves earlier views through camera-geometry-based retrieval, while residual recycling makes the conditioning path less sensitive to imperfect memory latents. Event Instruction Tuning adds composable event control, and reinforcement learning alignment recovers camera control and visual quality after distillation. With mixed-precision DiT execution, residual reuse, 75\%-pruned VAE decoding, and asynchronous pipeline parallelism, DreamX-World 1.0 reaches up to 16\,FPS on eight RTX\,5090 GPUs. On our 5-second basic evaluation, DreamX-World 1.0 achieves a camera-control score of 73.75 and an overall score of 84.76, outperforming HY-WorldPlay 1.5 and LingBot-World in overall score, which achieve 80.79 and 80.45, respectively.
Learning from Mistakes: Loss-Aware Memory Enhanced Continual Learning for LiDAR Place Recognition
Nov 19, 2025



LiDAR place recognition plays a crucial role in SLAM, robot navigation, and autonomous driving. However, existing LiDAR place recognition methods often struggle to adapt to new environments without forgetting previously learned knowledge, a challenge widely known as catastrophic forgetting. To address this issue, we propose KDF+, a novel continual learning framework for LiDAR place recognition that extends the KDF paradigm with a loss-aware sampling strategy and a rehearsal enhancement mechanism. The proposed sampling strategy estimates the learning difficulty of each sample via its loss value and selects samples for replay according to their estimated difficulty. Harder samples, which tend to encode more discriminative information, are sampled with higher probability while maintaining distributional coverage across the dataset. In addition, the rehearsal enhancement mechanism encourages memory samples to be further refined during new-task training by slightly reducing their loss relative to previous tasks, thereby reinforcing long-term knowledge retention. Extensive experiments across multiple benchmarks demonstrate that KDF+ consistently outperforms existing continual learning methods and can be seamlessly integrated into state-of-the-art continual learning for LiDAR place recognition frameworks to yield significant and stable performance gains. The code will be available at https://github.com/repo/KDF-plus.
Ranking-aware Continual Learning for LiDAR Place Recognition
May 12, 2025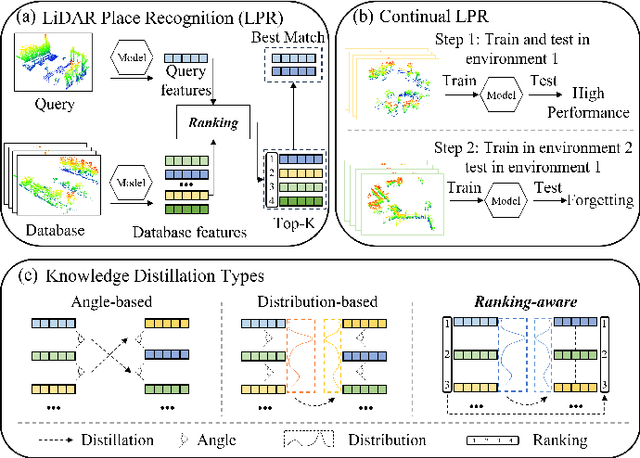
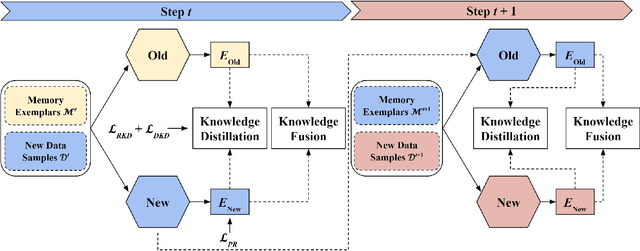
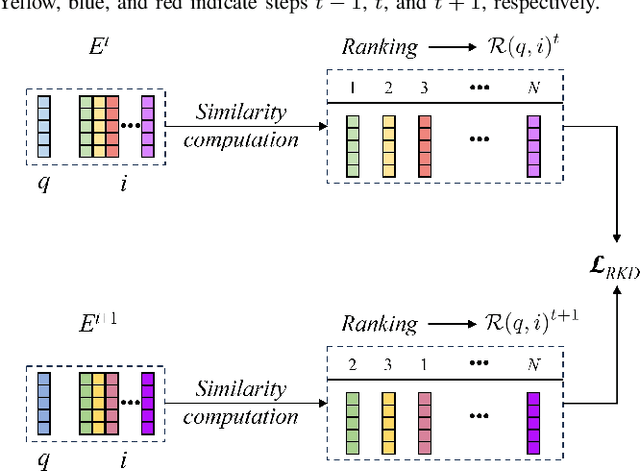
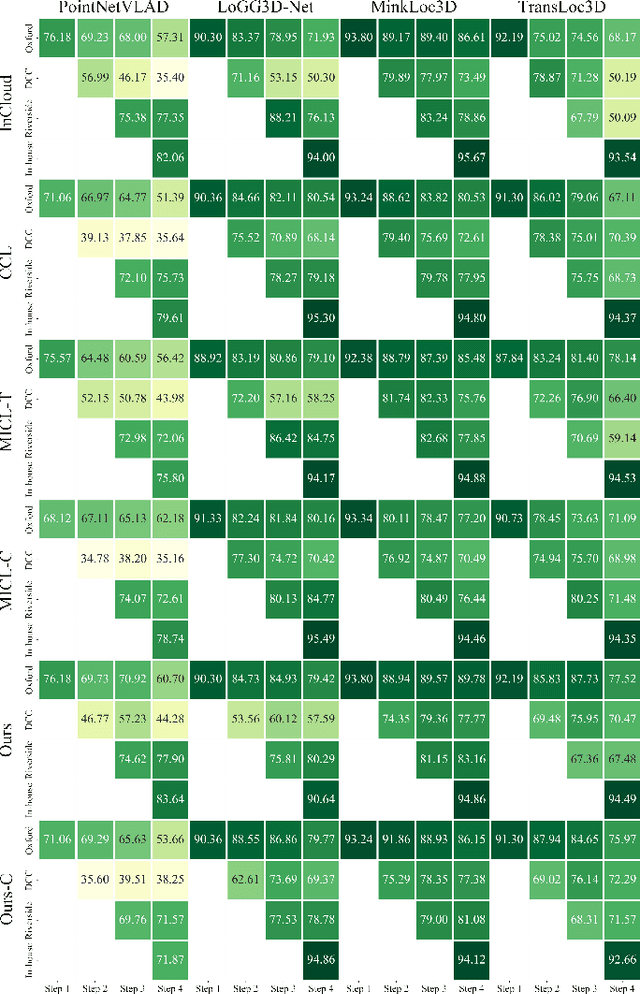
Place recognition plays a significant role in SLAM, robot navigation, and autonomous driving applications. Benefiting from deep learning, the performance of LiDAR place recognition (LPR) has been greatly improved. However, many existing learning-based LPR methods suffer from catastrophic forgetting, which severely harms the performance of LPR on previously trained places after training on a new environment. In this paper, we introduce a continual learning framework for LPR via Knowledge Distillation and Fusion (KDF) to alleviate forgetting. Inspired by the ranking process of place recognition retrieval, we present a ranking-aware knowledge distillation loss that encourages the network to preserve the high-level place recognition knowledge. We also introduce a knowledge fusion module to integrate the knowledge of old and new models for LiDAR place recognition. Our extensive experiments demonstrate that KDF can be applied to different networks to overcome catastrophic forgetting, surpassing the state-of-the-art methods in terms of mean Recall@1 and forgetting score.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024



Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.