 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamX-World 1.0: A General-Purpose Interactive World Model
Jun 15, 2026DreamX-World 1.0 is a general-purpose interactive text/image-to-video world model for controllable long-horizon generation. It supports camera navigation, revisits to previously observed regions, and promptable events across photorealistic, game-style, and stylized domains. Our data engine combines camera-accurate Unreal Engine rendering, action-rich gameplay recordings, and real-world videos with recovered camera geometry. For camera control, we introduce E-PRoPE, a lightweight variant of projective positional encoding that retains PRoPE's projective camera geometry while applying camera-aware attention to spatially reduced tokens. We convert a bidirectional video generator into a few-step autoregressive world model using causal forcing, DMD-style distillation, and long-rollout training. Training on self-generated long-horizon contexts exposes the model to its own generated history and reduces the style and color drift that accumulates across autoregressive chunks. Memory-Conditioned Scene Persistence retrieves earlier views through camera-geometry-based retrieval, while residual recycling makes the conditioning path less sensitive to imperfect memory latents. Event Instruction Tuning adds composable event control, and reinforcement learning alignment recovers camera control and visual quality after distillation. With mixed-precision DiT execution, residual reuse, 75\%-pruned VAE decoding, and asynchronous pipeline parallelism, DreamX-World 1.0 reaches up to 16\,FPS on eight RTX\,5090 GPUs. On our 5-second basic evaluation, DreamX-World 1.0 achieves a camera-control score of 73.75 and an overall score of 84.76, outperforming HY-WorldPlay 1.5 and LingBot-World in overall score, which achieve 80.79 and 80.45, respectively.
Learning Local Features with Context Aggregation for Visual Localization
May 30, 2020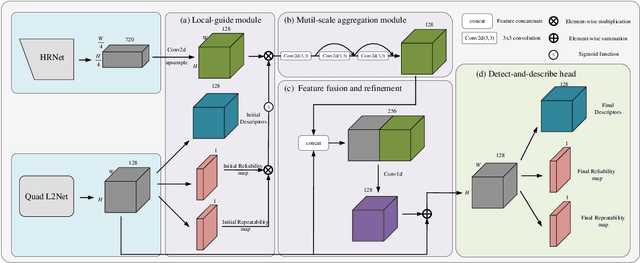
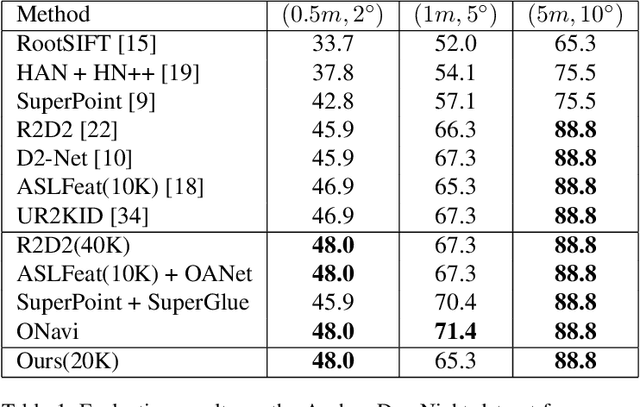
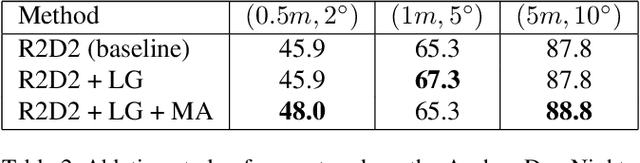

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.