 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Jan 12, 2022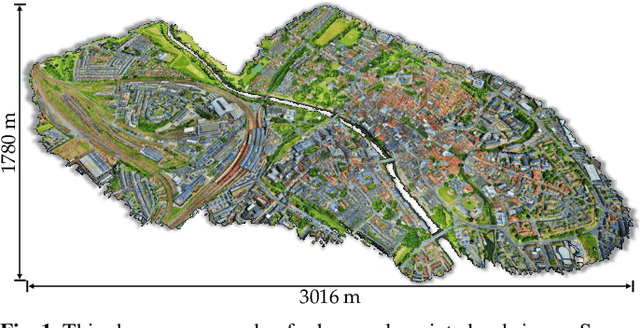
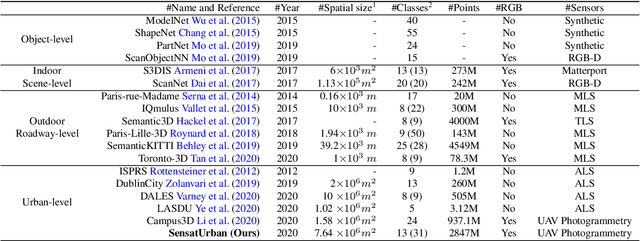

With the recent availability and affordability of commercial depth sensors and 3D scanners, an increasing number of 3D (i.e., RGBD, point cloud) datasets have been publicized to facilitate research in 3D computer vision. However, existing datasets either cover relatively small areas or have limited semantic annotations. Fine-grained understanding of urban-scale 3D scenes is still in its infancy. In this paper, we introduce SensatUrban, an urban-scale UAV photogrammetry point cloud dataset consisting of nearly three billion points collected from three UK cities, covering 7.6 km^2. Each point in the dataset has been labelled with fine-grained semantic annotations, resulting in a dataset that is three times the size of the previous existing largest photogrammetric point cloud dataset. In addition to the more commonly encountered categories such as road and vegetation, urban-level categories including rail, bridge, and river are also included in our dataset. Based on this dataset, we further build a benchmark to evaluate the performance of state-of-the-art segmentation algorithms. In particular, we provide a comprehensive analysis and identify several key challenges limiting urban-scale point cloud understanding. The dataset is available at http://point-cloud-analysis.cs.ox.ac.uk.
Box2Seg: Learning Semantics of 3D Point Clouds with Box-Level Supervision
Jan 09, 2022
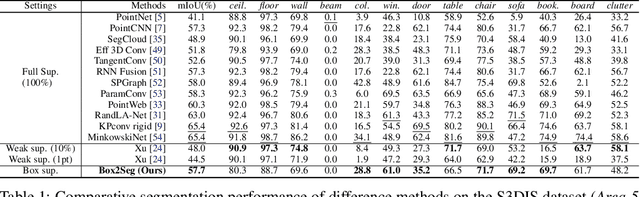
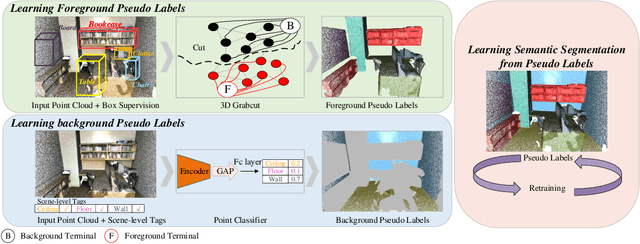
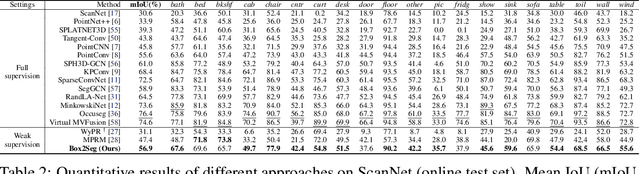
Learning dense point-wise semantics from unstructured 3D point clouds with fewer labels, although a realistic problem, has been under-explored in literature. While existing weakly supervised methods can effectively learn semantics with only a small fraction of point-level annotations, we find that the vanilla bounding box-level annotation is also informative for semantic segmentation of large-scale 3D point clouds. In this paper, we introduce a neural architecture, termed Box2Seg, to learn point-level semantics of 3D point clouds with bounding box-level supervision. The key to our approach is to generate accurate pseudo labels by exploring the geometric and topological structure inside and outside each bounding box. Specifically, an attention-based self-training (AST) technique and Point Class Activation Mapping (PCAM) are utilized to estimate pseudo-labels. The network is further trained and refined with pseudo labels. Experiments on two large-scale benchmarks including S3DIS and ScanNet demonstrate the competitive performance of the proposed method. In particular, the proposed network can be trained with cheap, or even off-the-shelf bounding box-level annotations and subcloud-level tags.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021
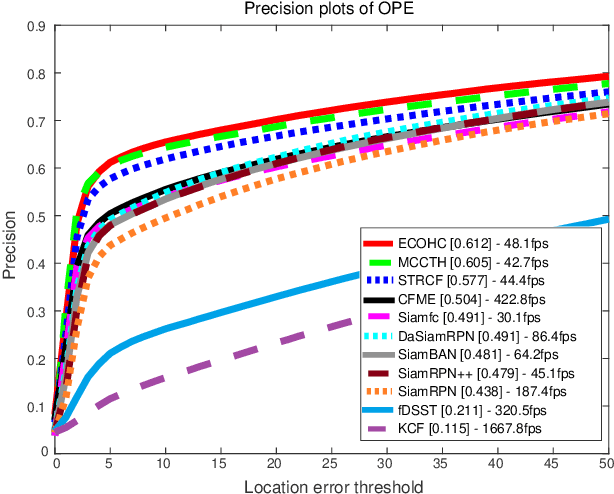
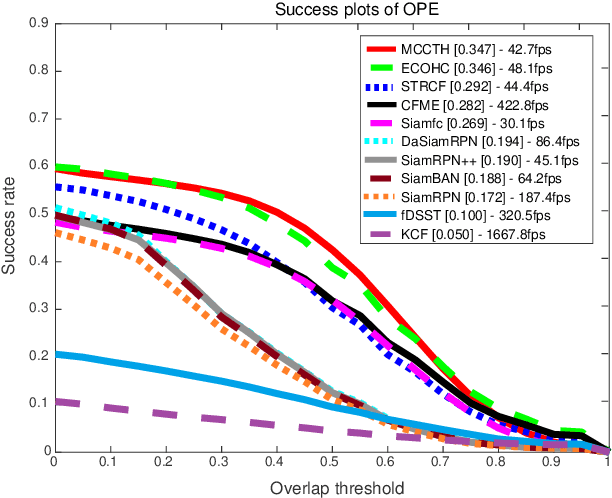

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.
Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Jul 06, 2021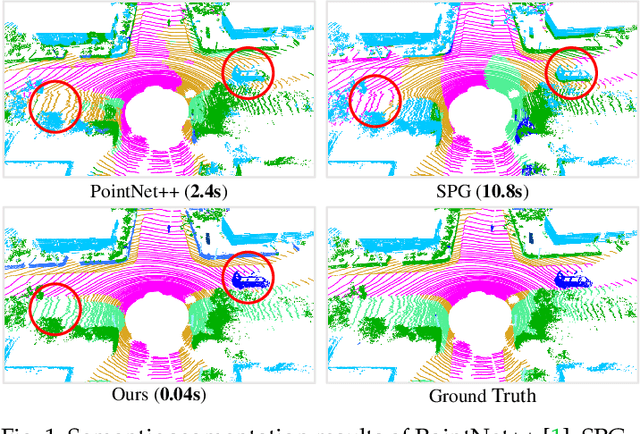
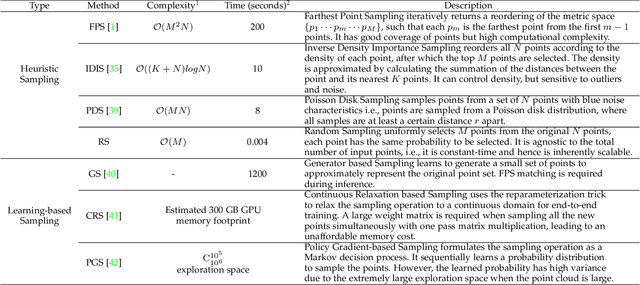
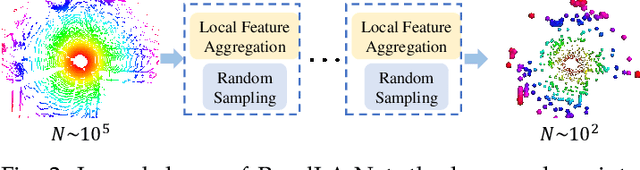
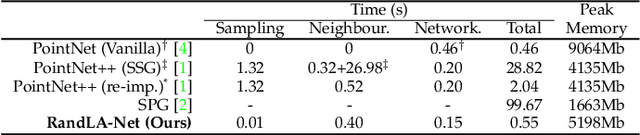
We study the problem of efficient semantic segmentation of large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Comparative experiments show that our RandLA-Net can process 1 million points in a single pass up to 200x faster than existing approaches. Moreover, extensive experiments on five large-scale point cloud datasets, including Semantic3D, SemanticKITTI, Toronto3D, NPM3D and S3DIS, demonstrate the state-of-the-art semantic segmentation performance of our RandLA-Net.
SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds with 1000x Fewer Labels
Apr 11, 2021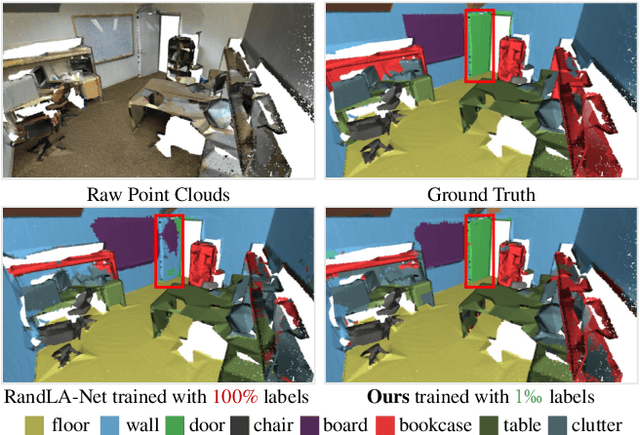
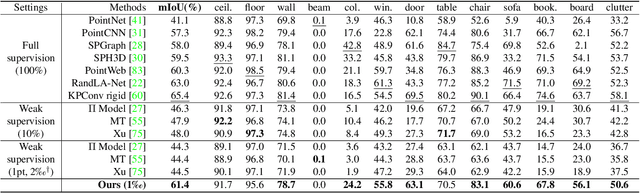
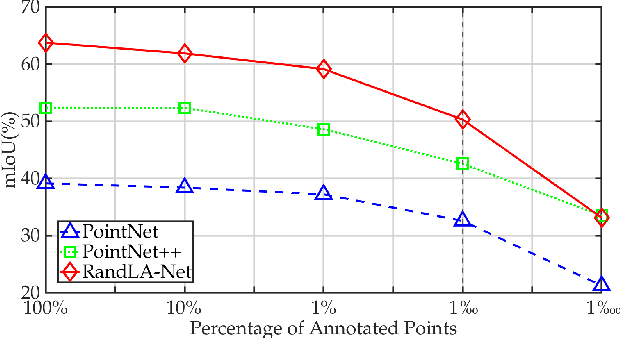
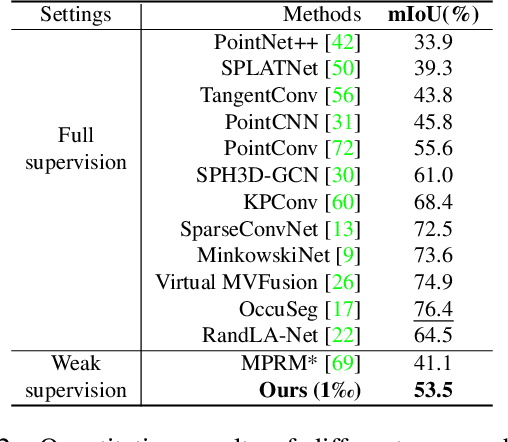
We study the problem of labelling effort for semantic segmentation of large-scale 3D point clouds. Existing works usually rely on densely annotated point-level semantic labels to provide supervision for network training. However, in real-world scenarios that contain billions of points, it is impractical and extremely costly to manually annotate every single point. In this paper, we first investigate whether dense 3D labels are truly required for learning meaningful semantic representations. Interestingly, we find that the segmentation performance of existing works only drops slightly given as few as 1% of the annotations. However, beyond this point (e.g. 1 per thousand and below) existing techniques fail catastrophically. To this end, we propose a new weak supervision method to implicitly augment the total amount of available supervision signals, by leveraging the semantic similarity between neighboring points. Extensive experiments demonstrate that the proposed Semantic Query Network (SQN) achieves state-of-the-art performance on six large-scale open datasets under weak supervision schemes, while requiring only 1000x fewer labeled points for training. The code is available at https://github.com/QingyongHu/SQN.
SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration
Nov 24, 2020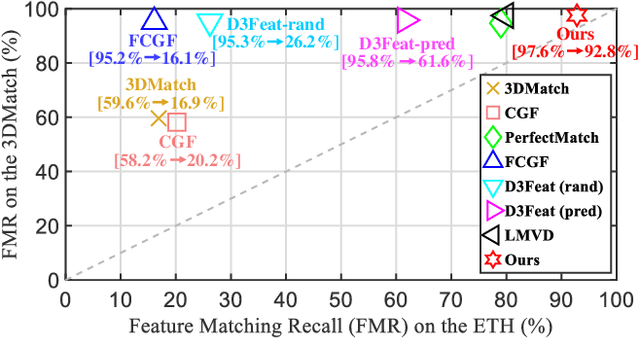
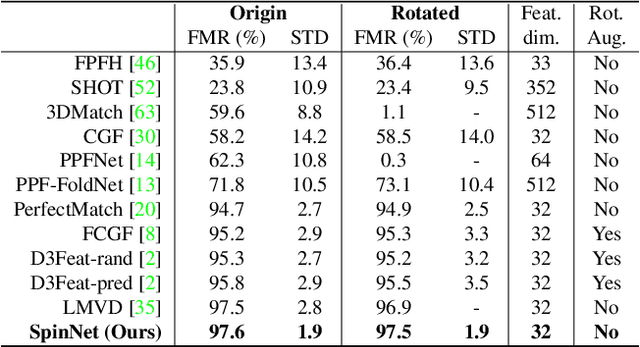
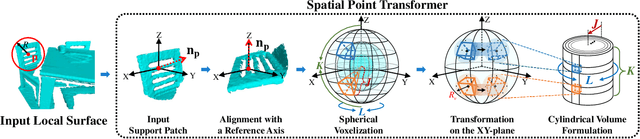
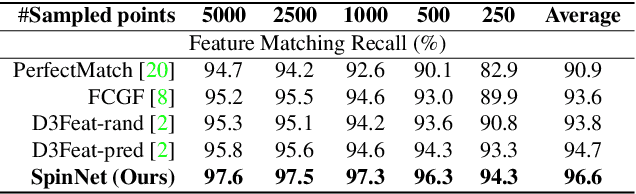
Extracting robust and general 3D local features is key to downstream tasks such as point cloud registration and reconstruction. Existing learning-based local descriptors are either sensitive to rotation transformations, or rely on classical handcrafted features which are neither general nor representative. In this paper, we introduce a new, yet conceptually simple, neural architecture, termed SpinNet, to extract local features which are rotationally invariant whilst sufficiently informative to enable accurate registration. A Spatial Point Transformer is first introduced to map the input local surface into a carefully designed cylindrical space, enabling end-to-end optimization with SO(2) equivariant representation. A Neural Feature Extractor which leverages the powerful point-based and 3D cylindrical convolutional neural layers is then utilized to derive a compact and representative descriptor for matching. Extensive experiments on both indoor and outdoor datasets demonstrate that SpinNet outperforms existing state-of-the-art techniques by a large margin. More critically, it has the best generalization ability across unseen scenarios with different sensor modalities. The code is available at https://github.com/QingyongHu/SpinNet.
Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
Sep 07, 2020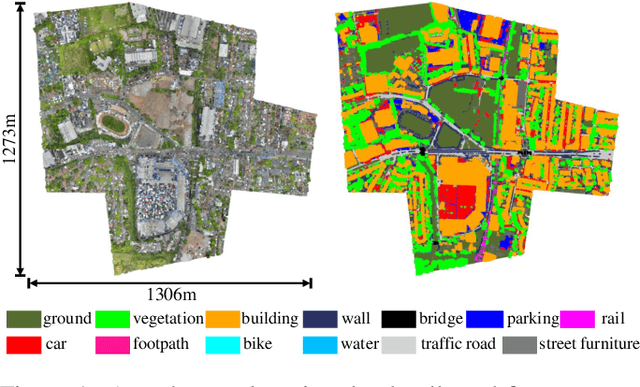
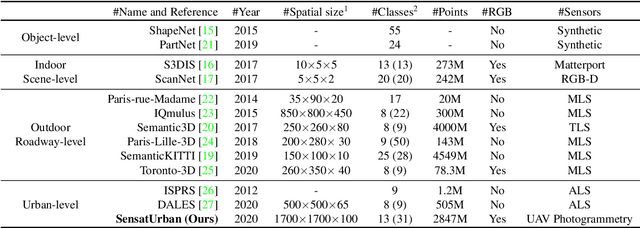
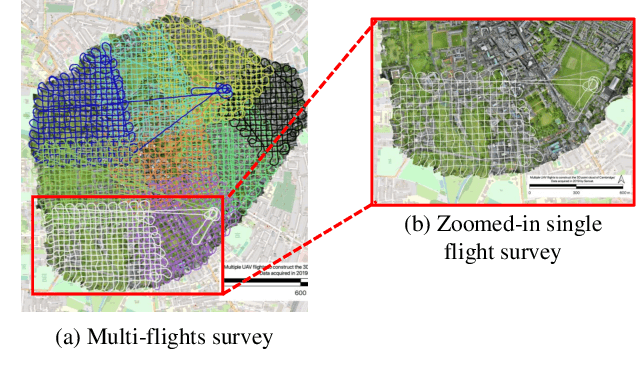
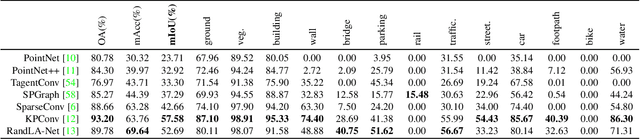
An essential prerequisite for unleashing the potential of supervised deep learning algorithms in the area of 3D scene understanding is the availability of large-scale and richly annotated datasets. However, publicly available datasets are either in relative small spatial scales or have limited semantic annotations due to the expensive cost of data acquisition and data annotation, which severely limits the development of fine-grained semantic understanding in the context of 3D point clouds. In this paper, we present an urban-scale photogrammetric point cloud dataset with nearly three billion richly annotated points, which is five times the number of labeled points than the existing largest point cloud dataset. Our dataset consists of large areas from two UK cities, covering about 6 $km^2$ of the city landscape. In the dataset, each 3D point is labeled as one of 13 semantic classes. We extensively evaluate the performance of state-of-the-art algorithms on our dataset and provide a comprehensive analysis of the results. In particular, we identify several key challenges towards urban-scale point cloud understanding. The dataset is available at https://github.com/QingyongHu/SensatUrban.
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 19, 2020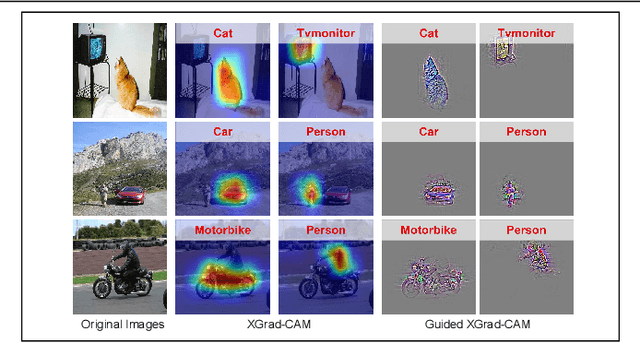
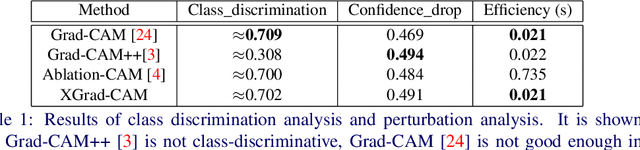
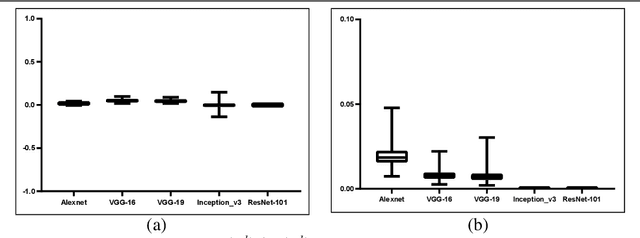
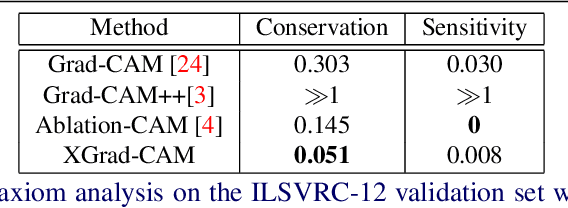
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.
Deep Learning for 3D Point Clouds: A Survey
Dec 27, 2019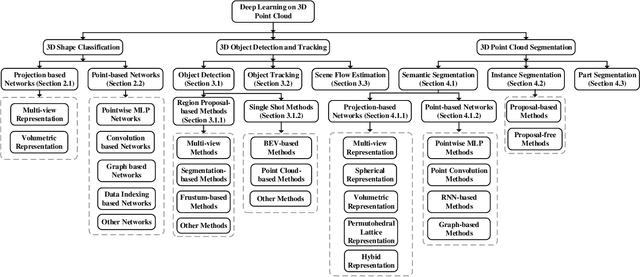
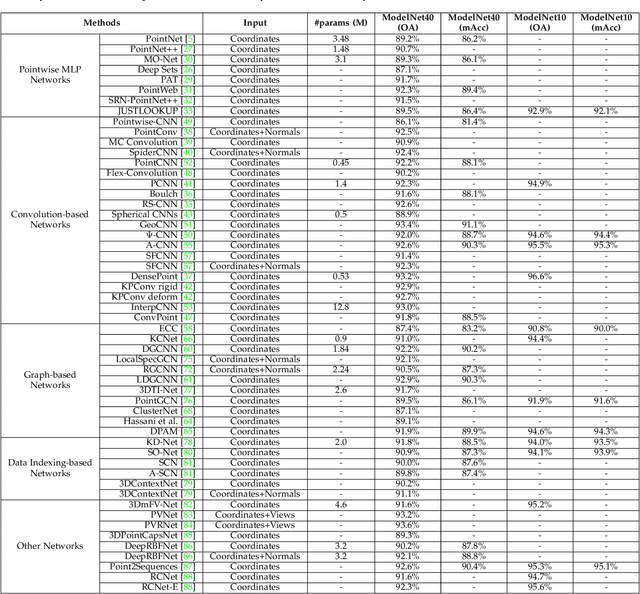
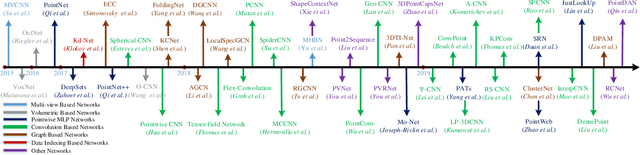
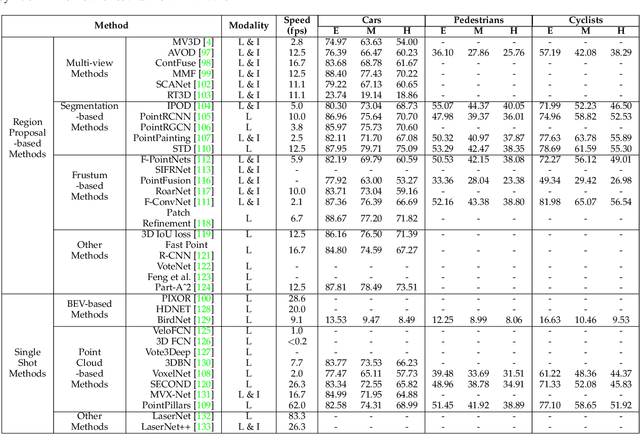
Point cloud learning has lately attracted increasing attention due to its wide applications in many areas, such as computer vision, autonomous driving, and robotics. As a dominating technique in AI, deep learning has been successfully used to solve various 2D vision problems. However, deep learning on point clouds is still in its infancy due to the unique challenges faced by the processing of point clouds with deep neural networks. Recently, deep learning on point clouds has become even thriving, with numerous methods being proposed to address different problems in this area. To stimulate future research, this paper presents a comprehensive review of recent progress in deep learning methods for point clouds. It covers three major tasks, including 3D shape classification, 3D object detection and tracking, and 3D point cloud segmentation. It also presents comparative results on several publicly available datasets, together with insightful observations and inspiring future research directions.
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Nov 25, 2019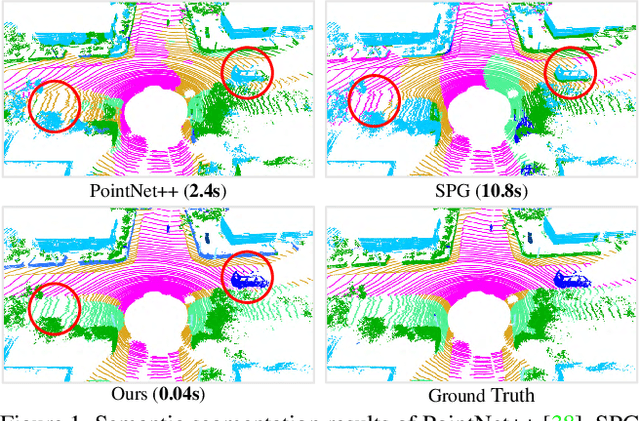
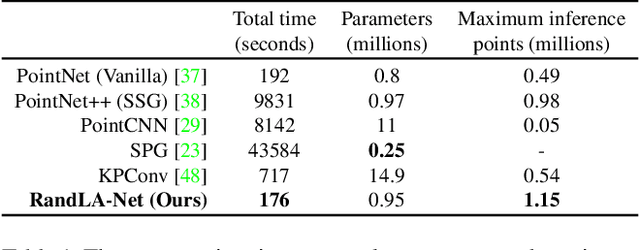
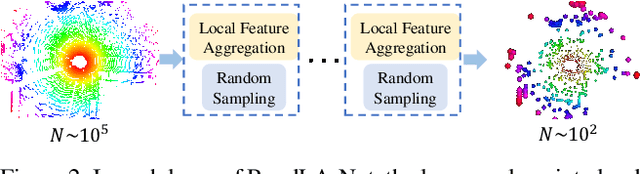
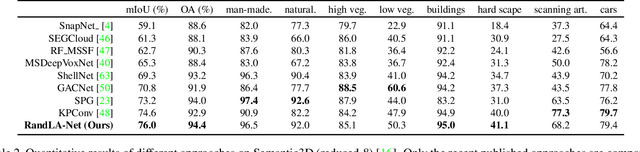
We study the problem of efficient semantic segmentation for large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Extensive experiments show that our RandLA-Net can process 1 million points in a single pass with up to 200X faster than existing approaches. Moreover, our RandLA-Net clearly surpasses state-of-the-art approaches for semantic segmentation on two large-scale benchmarks Semantic3D and SemanticKITTI.