 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Oct 06, 2022


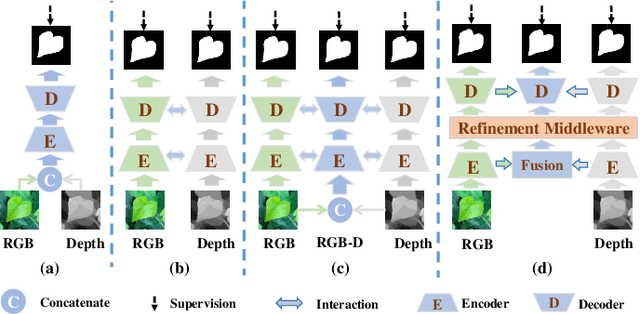
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.
The Minority Matters: A Diversity-Promoting Collaborative Metric Learning Algorithm
Sep 30, 2022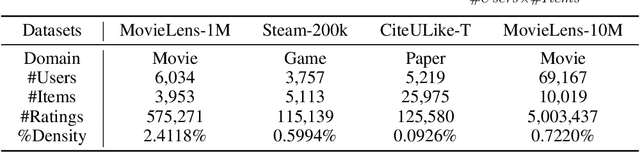
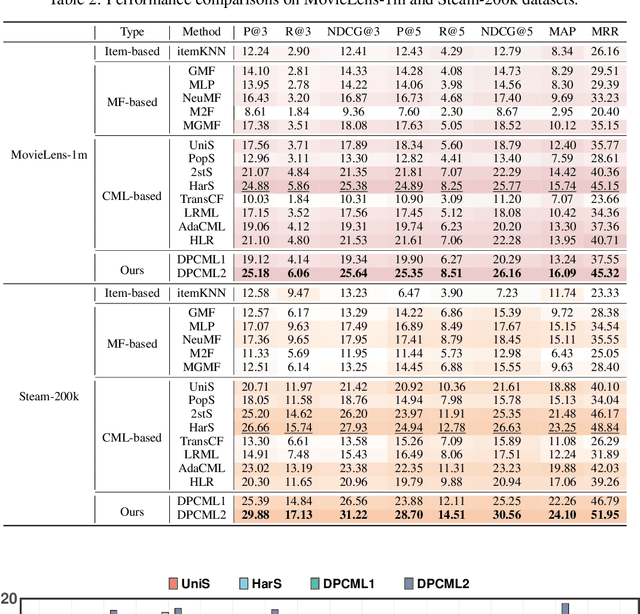
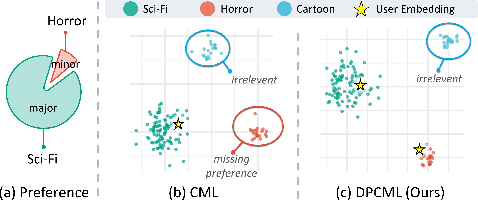
Collaborative Metric Learning (CML) has recently emerged as a popular method in recommendation systems (RS), closing the gap between metric learning and Collaborative Filtering. Following the convention of RS, existing methods exploit unique user representation in their model design. This paper focuses on a challenging scenario where a user has multiple categories of interests. Under this setting, we argue that the unique user representation might induce preference bias, especially when the item category distribution is imbalanced. To address this issue, we propose a novel method called \textit{Diversity-Promoting Collaborative Metric Learning} (DPCML), with the hope of considering the commonly ignored minority interest of the user. The key idea behind DPCML is to include a multiple set of representations for each user in the system. Based on this embedding paradigm, user preference toward an item is aggregated from different embeddings by taking the minimum item-user distance among the user embedding set. Furthermore, we observe that the diversity of the embeddings for the same user also plays an essential role in the model. To this end, we propose a \textit{diversity control regularization} term to accommodate the multi-vector representation strategy better. Theoretically, we show that DPCML could generalize well to unseen test data by tackling the challenge of the annoying operation that comes from the minimum value. Experiments over a range of benchmark datasets speak to the efficacy of DPCML.
Exploring the Algorithm-Dependent Generalization of AUPRC Optimization with List Stability
Sep 27, 2022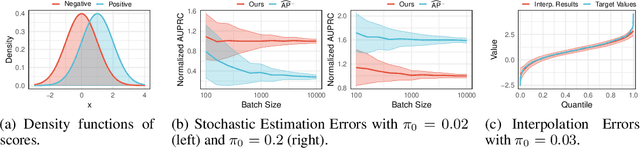
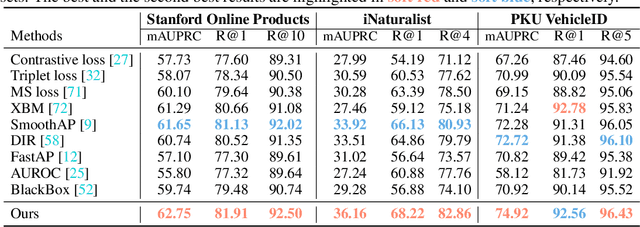
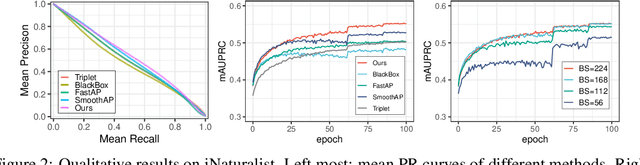
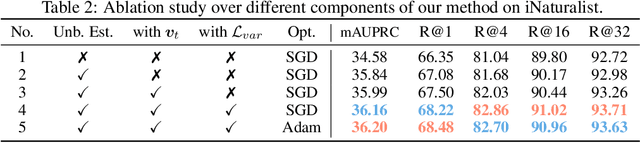
Stochastic optimization of the Area Under the Precision-Recall Curve (AUPRC) is a crucial problem for machine learning. Although various algorithms have been extensively studied for AUPRC optimization, the generalization is only guaranteed in the multi-query case. In this work, we present the first trial in the single-query generalization of stochastic AUPRC optimization. For sharper generalization bounds, we focus on algorithm-dependent generalization. There are both algorithmic and theoretical obstacles to our destination. From an algorithmic perspective, we notice that the majority of existing stochastic estimators are biased only when the sampling strategy is biased, and is leave-one-out unstable due to the non-decomposability. To address these issues, we propose a sampling-rate-invariant unbiased stochastic estimator with superior stability. On top of this, the AUPRC optimization is formulated as a composition optimization problem, and a stochastic algorithm is proposed to solve this problem. From a theoretical perspective, standard techniques of the algorithm-dependent generalization analysis cannot be directly applied to such a listwise compositional optimization problem. To fill this gap, we extend the model stability from instancewise losses to listwise losses and bridge the corresponding generalization and stability. Additionally, we construct state transition matrices to describe the recurrence of the stability, and simplify calculations by matrix spectrum. Practically, experimental results on three image retrieval datasets on speak to the effectiveness and soundness of our framework.
MaxMatch: Semi-Supervised Learning with Worst-Case Consistency
Sep 26, 2022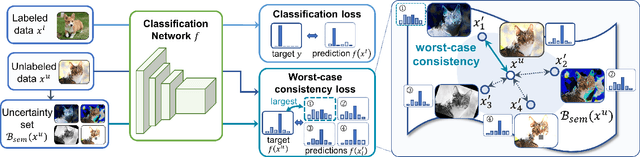
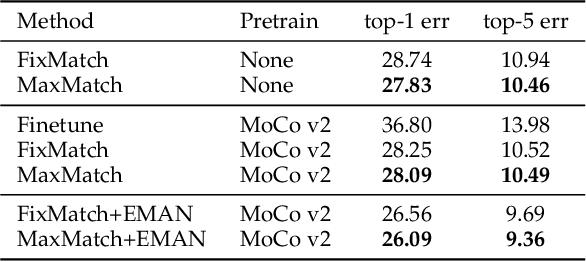

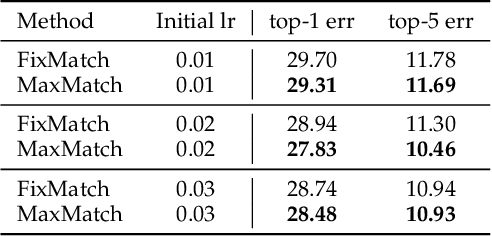
In recent years, great progress has been made to incorporate unlabeled data to overcome the inefficiently supervised problem via semi-supervised learning (SSL). Most state-of-the-art models are based on the idea of pursuing consistent model predictions over unlabeled data toward the input noise, which is called consistency regularization. Nonetheless, there is a lack of theoretical insights into the reason behind its success. To bridge the gap between theoretical and practical results, we propose a worst-case consistency regularization technique for SSL in this paper. Specifically, we first present a generalization bound for SSL consisting of the empirical loss terms observed on labeled and unlabeled training data separately. Motivated by this bound, we derive an SSL objective that minimizes the largest inconsistency between an original unlabeled sample and its multiple augmented variants. We then provide a simple but effective algorithm to solve the proposed minimax problem, and theoretically prove that it converges to a stationary point. Experiments on five popular benchmark datasets validate the effectiveness of our proposed method.
A Tale of HodgeRank and Spectral Method: Target Attack Against Rank Aggregation Is the Fixed Point of Adversarial Game
Sep 13, 2022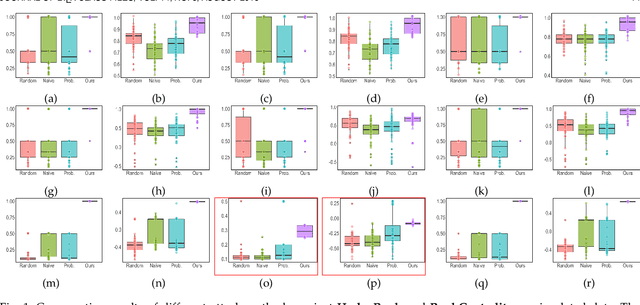

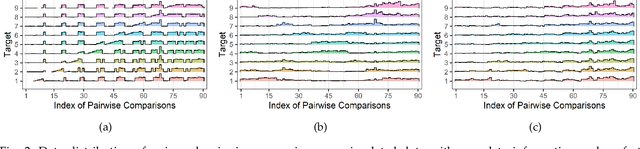

Rank aggregation with pairwise comparisons has shown promising results in elections, sports competitions, recommendations, and information retrieval. However, little attention has been paid to the security issue of such algorithms, in contrast to numerous research work on the computational and statistical characteristics. Driven by huge profits, the potential adversary has strong motivation and incentives to manipulate the ranking list. Meanwhile, the intrinsic vulnerability of the rank aggregation methods is not well studied in the literature. To fully understand the possible risks, we focus on the purposeful adversary who desires to designate the aggregated results by modifying the pairwise data in this paper. From the perspective of the dynamical system, the attack behavior with a target ranking list is a fixed point belonging to the composition of the adversary and the victim. To perform the targeted attack, we formulate the interaction between the adversary and the victim as a game-theoretic framework consisting of two continuous operators while Nash equilibrium is established. Then two procedures against HodgeRank and RankCentrality are constructed to produce the modification of the original data. Furthermore, we prove that the victims will produce the target ranking list once the adversary masters the complete information. It is noteworthy that the proposed methods allow the adversary only to hold incomplete information or imperfect feedback and perform the purposeful attack. The effectiveness of the suggested target attack strategies is demonstrated by a series of toy simulations and several real-world data experiments. These experimental results show that the proposed methods could achieve the attacker's goal in the sense that the leading candidate of the perturbed ranking list is the designated one by the adversary.
* 33 pages, https://github.com/alphaprime/Target_Attack_Rank_Aggregation
Optimizing Partial Area Under the Top-k Curve: Theory and Practice
Sep 03, 2022

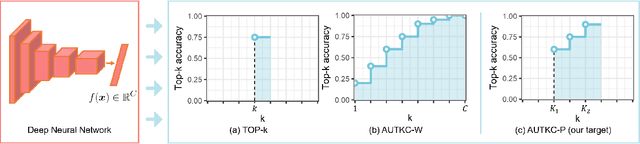

Top-k error has become a popular metric for large-scale classification benchmarks due to the inevitable semantic ambiguity among classes. Existing literature on top-k optimization generally focuses on the optimization method of the top-k objective, while ignoring the limitations of the metric itself. In this paper, we point out that the top-k objective lacks enough discrimination such that the induced predictions may give a totally irrelevant label a top rank. To fix this issue, we develop a novel metric named partial Area Under the top-k Curve (AUTKC). Theoretical analysis shows that AUTKC has a better discrimination ability, and its Bayes optimal score function could give a correct top-K ranking with respect to the conditional probability. This shows that AUTKC does not allow irrelevant labels to appear in the top list. Furthermore, we present an empirical surrogate risk minimization framework to optimize the proposed metric. Theoretically, we present (1) a sufficient condition for Fisher consistency of the Bayes optimal score function; (2) a generalization upper bound which is insensitive to the number of classes under a simple hyperparameter setting. Finally, the experimental results on four benchmark datasets validate the effectiveness of our proposed framework.
Multi-Attention Network for Compressed Video Referring Object Segmentation
Jul 26, 2022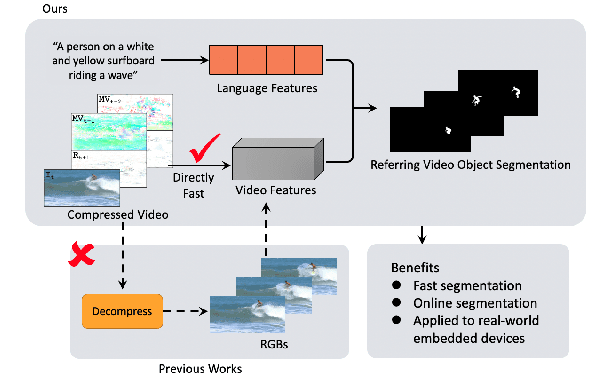
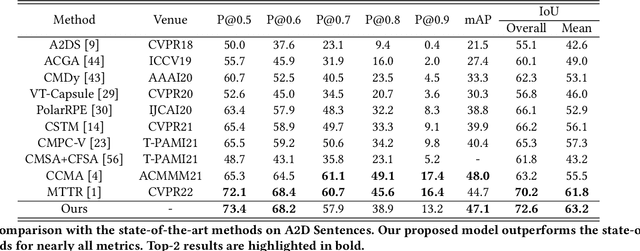
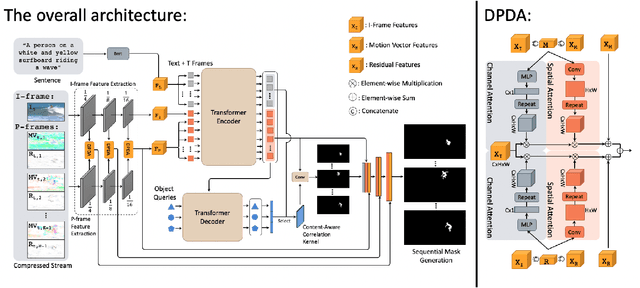
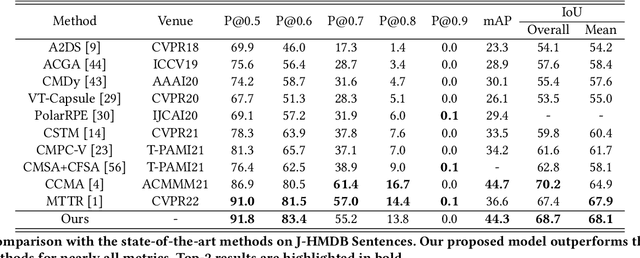
Referring video object segmentation aims to segment the object referred by a given language expression. Existing works typically require compressed video bitstream to be decoded to RGB frames before being segmented, which increases computation and storage requirements and ultimately slows the inference down. This may hamper its application in real-world computing resource limited scenarios, such as autonomous cars and drones. To alleviate this problem, in this paper, we explore the referring object segmentation task on compressed videos, namely on the original video data flow. Besides the inherent difficulty of the video referring object segmentation task itself, obtaining discriminative representation from compressed video is also rather challenging. To address this problem, we propose a multi-attention network which consists of dual-path dual-attention module and a query-based cross-modal Transformer module. Specifically, the dual-path dual-attention module is designed to extract effective representation from compressed data in three modalities, i.e., I-frame, Motion Vector and Residual. The query-based cross-modal Transformer firstly models the correlation between linguistic and visual modalities, and then the fused multi-modality features are used to guide object queries to generate a content-aware dynamic kernel and to predict final segmentation masks. Different from previous works, we propose to learn just one kernel, which thus removes the complicated post mask-matching procedure of existing methods. Extensive promising experimental results on three challenging datasets show the effectiveness of our method compared against several state-of-the-art methods which are proposed for processing RGB data. Source code is available at: https://github.com/DexiangHong/MANet.
Entity-enhanced Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Jul 18, 2022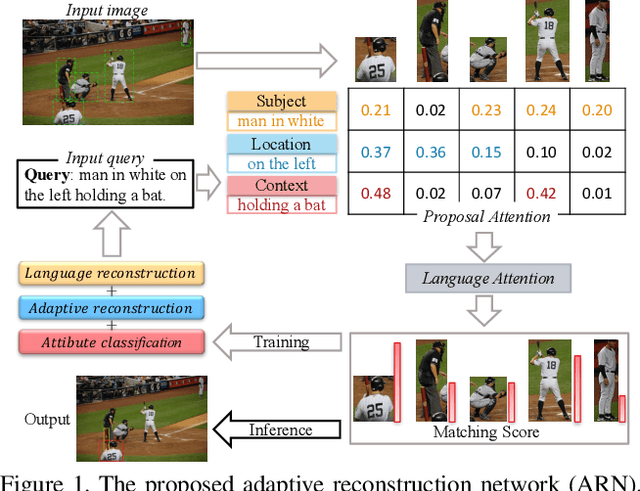
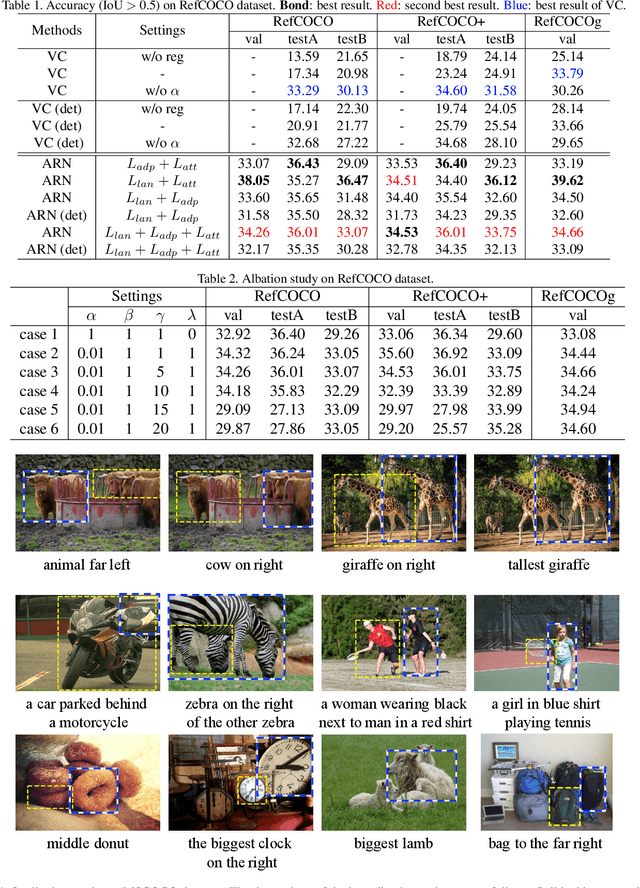
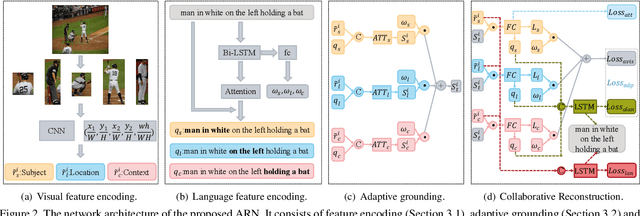
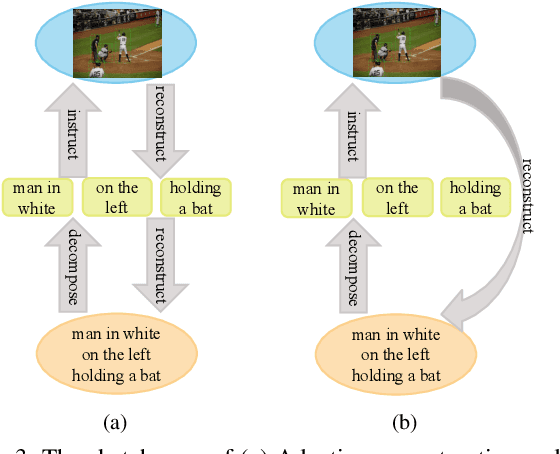
Weakly supervised Referring Expression Grounding (REG) aims to ground a particular target in an image described by a language expression while lacking the correspondence between target and expression. Two main problems exist in weakly supervised REG. First, the lack of region-level annotations introduces ambiguities between proposals and queries. Second, most previous weakly supervised REG methods ignore the discriminative location and context of the referent, causing difficulties in distinguishing the target from other same-category objects. To address the above challenges, we design an entity-enhanced adaptive reconstruction network (EARN). Specifically, EARN includes three modules: entity enhancement, adaptive grounding, and collaborative reconstruction. In entity enhancement, we calculate semantic similarity as supervision to select the candidate proposals. Adaptive grounding calculates the ranking score of candidate proposals upon subject, location and context with hierarchical attention. Collaborative reconstruction measures the ranking result from three perspectives: adaptive reconstruction, language reconstruction and attribute classification. The adaptive mechanism helps to alleviate the variance of different referring expressions. Experiments on five datasets show EARN outperforms existing state-of-the-art methods. Qualitative results demonstrate that the proposed EARN can better handle the situation where multiple objects of a particular category are situated together.
Meta-Wrapper: Differentiable Wrapping Operator for User Interest Selection in CTR Prediction
Jun 28, 2022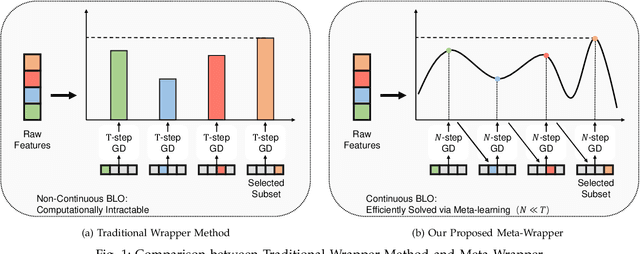
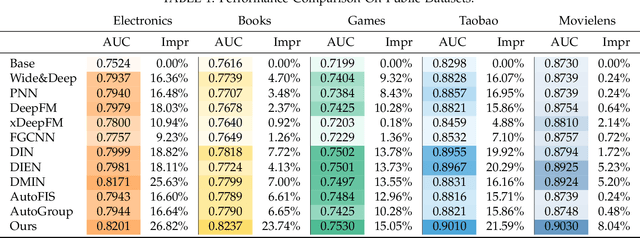
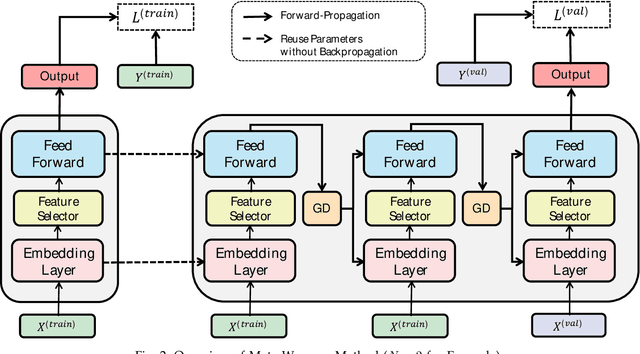
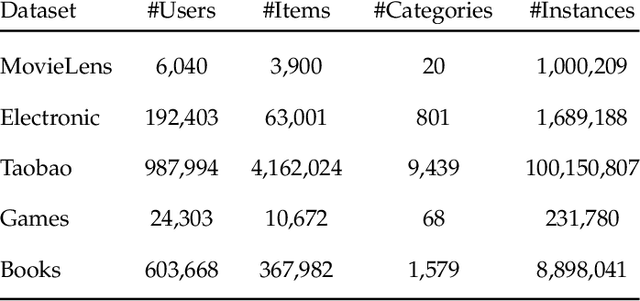
Click-through rate (CTR) prediction, whose goal is to predict the probability of the user to click on an item, has become increasingly significant in the recommender systems. Recently, some deep learning models with the ability to automatically extract the user interest from his/her behaviors have achieved great success. In these work, the attention mechanism is used to select the user interested items in historical behaviors, improving the performance of the CTR predictor. Normally, these attentive modules can be jointly trained with the base predictor by using gradient descents. In this paper, we regard user interest modeling as a feature selection problem, which we call user interest selection. For such a problem, we propose a novel approach under the framework of the wrapper method, which is named Meta-Wrapper. More specifically, we use a differentiable module as our wrapping operator and then recast its learning problem as a continuous bilevel optimization. Moreover, we use a meta-learning algorithm to solve the optimization and theoretically prove its convergence. Meanwhile, we also provide theoretical analysis to show that our proposed method 1) efficiencies the wrapper-based feature selection, and 2) achieves better resistance to overfitting. Finally, extensive experiments on three public datasets manifest the superiority of our method in boosting the performance of CTR prediction.
AdAUC: End-to-end Adversarial AUC Optimization Against Long-tail Problems
Jun 24, 2022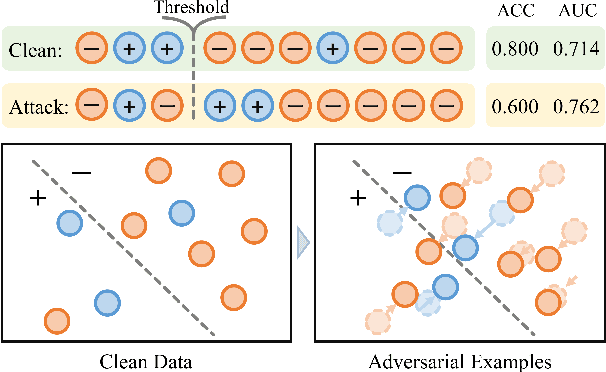

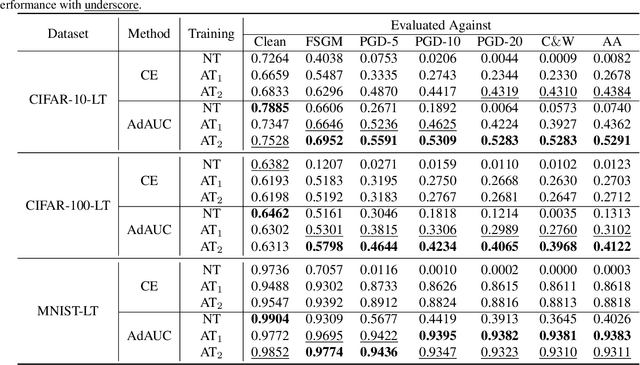
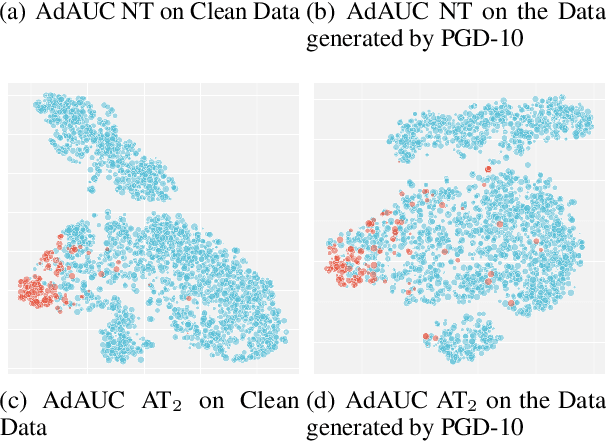
It is well-known that deep learning models are vulnerable to adversarial examples. Existing studies of adversarial training have made great progress against this challenge. As a typical trait, they often assume that the class distribution is overall balanced. However, long-tail datasets are ubiquitous in a wide spectrum of applications, where the amount of head class instances is larger than the tail classes. Under such a scenario, AUC is a much more reasonable metric than accuracy since it is insensitive toward class distribution. Motivated by this, we present an early trial to explore adversarial training methods to optimize AUC. The main challenge lies in that the positive and negative examples are tightly coupled in the objective function. As a direct result, one cannot generate adversarial examples without a full scan of the dataset. To address this issue, based on a concavity regularization scheme, we reformulate the AUC optimization problem as a saddle point problem, where the objective becomes an instance-wise function. This leads to an end-to-end training protocol. Furthermore, we provide a convergence guarantee of the proposed algorithm. Our analysis differs from the existing studies since the algorithm is asked to generate adversarial examples by calculating the gradient of a min-max problem. Finally, the extensive experimental results show the performance and robustness of our algorithm in three long-tail datasets.