 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Image Editing via Effects-Sensitive In-Context Inpainting with Diffusion Transformers
Feb 09, 2026Recent advances in diffusion models have significantly improved image editing. However, challenges persist in handling geometric transformations, such as translation, rotation, and scaling, particularly in complex scenes. Existing approaches suffer from two main limitations: (1) difficulty in achieving accurate geometric editing of object translation, rotation, and scaling; (2) inadequate modeling of intricate lighting and shadow effects, leading to unrealistic results. To address these issues, we propose GeoEdit, a framework that leverages in-context generation through a diffusion transformer module, which integrates geometric transformations for precise object edits. Moreover, we introduce Effects-Sensitive Attention, which enhances the modeling of intricate lighting and shadow effects for improved realism. To further support training, we construct RS-Objects, a large-scale geometric editing dataset containing over 120,000 high-quality image pairs, enabling the model to learn precise geometric editing while generating realistic lighting and shadows. Extensive experiments on public benchmarks demonstrate that GeoEdit consistently outperforms state-of-the-art methods in terms of visual quality, geometric accuracy, and realism.
FairHuman: Boosting Hand and Face Quality in Human Image Generation with Minimum Potential Delay Fairness in Diffusion Models
Jul 03, 2025Image generation has achieved remarkable progress with the development of large-scale text-to-image models, especially diffusion-based models. However, generating human images with plausible details, such as faces or hands, remains challenging due to insufficient supervision of local regions during training. To address this issue, we propose FairHuman, a multi-objective fine-tuning approach designed to enhance both global and local generation quality fairly. Specifically, we first construct three learning objectives: a global objective derived from the default diffusion objective function and two local objectives for hands and faces based on pre-annotated positional priors. Subsequently, we derive the optimal parameter updating strategy under the guidance of the Minimum Potential Delay (MPD) criterion, thereby attaining fairness-ware optimization for this multi-objective problem. Based on this, our proposed method can achieve significant improvements in generating challenging local details while maintaining overall quality. Extensive experiments showcase the effectiveness of our method in improving the performance of human image generation under different scenarios.
Meta-Wrapper: Differentiable Wrapping Operator for User Interest Selection in CTR Prediction
Jun 28, 2022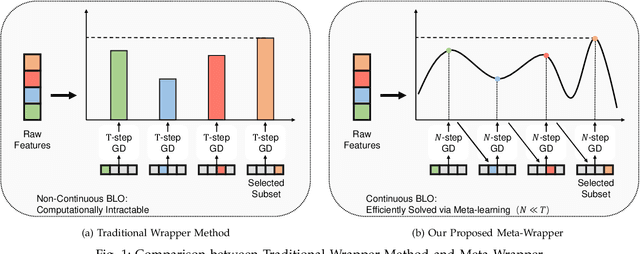
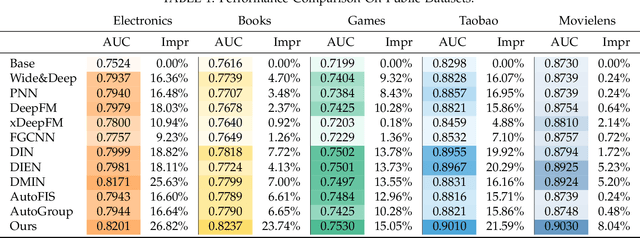
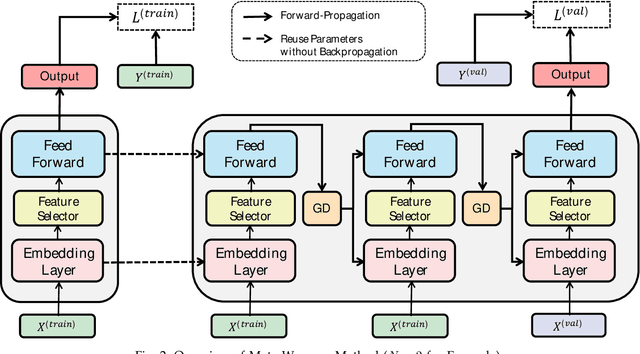
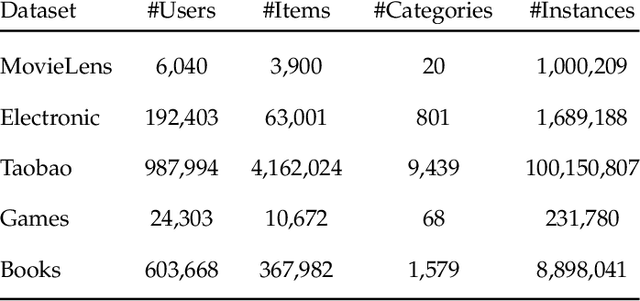
Click-through rate (CTR) prediction, whose goal is to predict the probability of the user to click on an item, has become increasingly significant in the recommender systems. Recently, some deep learning models with the ability to automatically extract the user interest from his/her behaviors have achieved great success. In these work, the attention mechanism is used to select the user interested items in historical behaviors, improving the performance of the CTR predictor. Normally, these attentive modules can be jointly trained with the base predictor by using gradient descents. In this paper, we regard user interest modeling as a feature selection problem, which we call user interest selection. For such a problem, we propose a novel approach under the framework of the wrapper method, which is named Meta-Wrapper. More specifically, we use a differentiable module as our wrapping operator and then recast its learning problem as a continuous bilevel optimization. Moreover, we use a meta-learning algorithm to solve the optimization and theoretically prove its convergence. Meanwhile, we also provide theoretical analysis to show that our proposed method 1) efficiencies the wrapper-based feature selection, and 2) achieves better resistance to overfitting. Finally, extensive experiments on three public datasets manifest the superiority of our method in boosting the performance of CTR prediction.