 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign, Integration, and Field Evaluation of a Robotic Blossom Thinning System for Tree Fruit Crops
Apr 11, 2023The US apple industry relies heavily on semi-skilled manual labor force for essential field operations such as training, pruning, blossom and green fruit thinning, and harvesting. Blossom thinning is one of the crucial crop load management practices to achieve desired crop load, fruit quality, and return bloom. While several techniques such as chemical, and mechanical thinning are available for large-scale blossom thinning such approaches often yield unpredictable thinning results and may cause damage the canopy, spurs, and leaf tissue. Hence, growers still depend on laborious, labor intensive and expensive manual hand blossom thinning for desired thinning outcomes. This research presents a robotic solution for blossom thinning in apple orchards using a computer vision system with artificial intelligence, a six degrees of freedom robotic manipulator, and an electrically actuated miniature end-effector for robotic blossom thinning. The integrated robotic system was evaluated in a commercial apple orchard which showed promising results for targeted and selective blossom thinning. Two thinning approaches, center and boundary thinning, were investigated to evaluate the system ability to remove varying proportion of flowers from apple flower clusters. During boundary thinning the end effector was actuated around the cluster boundary while center thinning involved end-effector actuation only at the cluster centroid for a fixed duration of 2 seconds. The boundary thinning approach thinned 67.2% of flowers from the targeted clusters with a cycle time of 9.0 seconds per cluster, whereas center thinning approach thinned 59.4% of flowers with a cycle time of 7.2 seconds per cluster. When commercially adopted, the proposed system could help address problems faced by apple growers with current hand, chemical, and mechanical blossom thinning approaches.
Auto-HeG: Automated Graph Neural Network on Heterophilic Graphs
Feb 23, 2023



Graph neural architecture search (NAS) has gained popularity in automatically designing powerful graph neural networks (GNNs) with relieving human efforts. However, existing graph NAS methods mainly work under the homophily assumption and overlook another important graph property, i.e., heterophily, which exists widely in various real-world applications. To date, automated heterophilic graph learning with NAS is still a research blank to be filled in. Due to the complexity and variety of heterophilic graphs, the critical challenge of heterophilic graph NAS mainly lies in developing the heterophily-specific search space and strategy. Therefore, in this paper, we propose a novel automated graph neural network on heterophilic graphs, namely Auto-HeG, to automatically build heterophilic GNN models with expressive learning abilities. Specifically, Auto-HeG incorporates heterophily into all stages of automatic heterophilic graph learning, including search space design, supernet training, and architecture selection. Through the diverse message-passing scheme with joint micro-level and macro-level designs, we first build a comprehensive heterophilic GNN search space, enabling Auto-HeG to integrate complex and various heterophily of graphs. With a progressive supernet training strategy, we dynamically shrink the initial search space according to layer-wise variation of heterophily, resulting in a compact and efficient supernet. Taking a heterophily-aware distance criterion as the guidance, we conduct heterophilic architecture selection in the leave-one-out pattern, so that specialized and expressive heterophilic GNN architectures can be derived. Extensive experiments illustrate the superiority of Auto-HeG in developing excellent heterophilic GNNs to human-designed models and graph NAS models.
SaFormer: A Conditional Sequence Modeling Approach to Offline Safe Reinforcement Learning
Jan 28, 2023Offline safe RL is of great practical relevance for deploying agents in real-world applications. However, acquiring constraint-satisfying policies from the fixed dataset is non-trivial for conventional approaches. Even worse, the learned constraints are stationary and may become invalid when the online safety requirement changes. In this paper, we present a novel offline safe RL approach referred to as SaFormer, which tackles the above issues via conditional sequence modeling. In contrast to existing sequence models, we propose cost-related tokens to restrict the action space and a posterior safety verification to enforce the constraint explicitly. Specifically, SaFormer performs a two-stage auto-regression conditioned by the maximum remaining cost to generate feasible candidates. It then filters out unsafe attempts and executes the optimal action with the highest expected return. Extensive experiments demonstrate the efficacy of SaFormer featuring (1) competitive returns with tightened constraint satisfaction; (2) adaptability to the in-range cost values of the offline data without retraining; (3) generalizability for constraints beyond the current dataset.
Collaborative Regret Minimization in Multi-Armed Bandits
Jan 26, 2023In this paper, we study the collaborative learning model, which concerns the tradeoff between parallelism and communication overhead in multi-agent reinforcement learning. For a fundamental problem in bandit theory, regret minimization in multi-armed bandits, we present the first and almost tight tradeoffs between the number of rounds of communication between the agents and the regret of the collaborative learning process.
Lightweight Monocular Depth Estimation
Dec 21, 2022Monocular depth estimation can play an important role in addressing the issue of deriving scene geometry from 2D images. It has been used in a variety of industries, including robots, self-driving cars, scene comprehension, 3D reconstructions, and others. The goal of our method is to create a lightweight machine-learning model in order to predict the depth value of each pixel given only a single RGB image as input with the Unet structure of the image segmentation network. We use the NYU Depth V2 dataset to test the structure and compare the result with other methods. The proposed method achieves relatively high accuracy and low rootmean-square error.
Evaluating Model-free Reinforcement Learning toward Safety-critical Tasks
Dec 12, 2022Safety comes first in many real-world applications involving autonomous agents. Despite a large number of reinforcement learning (RL) methods focusing on safety-critical tasks, there is still a lack of high-quality evaluation of those algorithms that adheres to safety constraints at each decision step under complex and unknown dynamics. In this paper, we revisit prior work in this scope from the perspective of state-wise safe RL and categorize them as projection-based, recovery-based, and optimization-based approaches, respectively. Furthermore, we propose Unrolling Safety Layer (USL), a joint method that combines safety optimization and safety projection. This novel technique explicitly enforces hard constraints via the deep unrolling architecture and enjoys structural advantages in navigating the trade-off between reward improvement and constraint satisfaction. To facilitate further research in this area, we reproduce related algorithms in a unified pipeline and incorporate them into SafeRL-Kit, a toolkit that provides off-the-shelf interfaces and evaluation utilities for safety-critical tasks. We then perform a comparative study of the involved algorithms on six benchmarks ranging from robotic control to autonomous driving. The empirical results provide an insight into their applicability and robustness in learning zero-cost-return policies without task-dependent handcrafting. The project page is available at https://sites.google.com/view/saferlkit.
A Survey for Efficient Open Domain Question Answering
Nov 15, 2022Open domain question answering (ODQA) is a longstanding task aimed at answering factual questions from a large knowledge corpus without any explicit evidence in natural language processing (NLP). Recent works have predominantly focused on improving the answering accuracy and achieved promising progress. However, higher accuracy often comes with more memory consumption and inference latency, which might not necessarily be efficient enough for direct deployment in the real world. Thus, a trade-off between accuracy, memory consumption and processing speed is pursued. In this paper, we provide a survey of recent advances in the efficiency of ODQA models. We walk through the ODQA models and conclude the core techniques on efficiency. Quantitative analysis on memory cost, processing speed, accuracy and overall comparison are given. We hope that this work would keep interested scholars informed of the advances and open challenges in ODQA efficiency research, and thus contribute to the further development of ODQA efficiency.
Joint Optimization of STAR-RIS Assisted UAV Communication Systems
Sep 08, 2022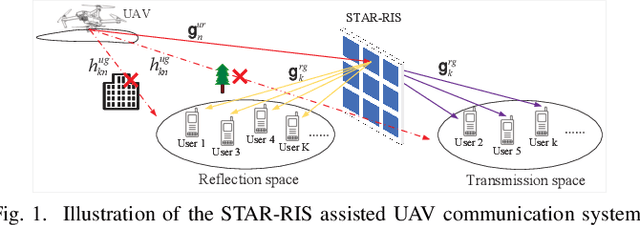
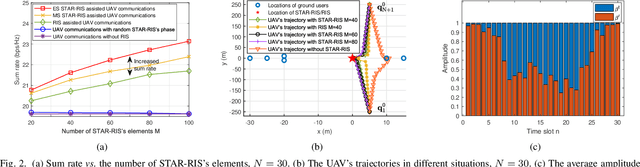
In this letter, we study the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted unmanned aerial vehicle (UAV) communications. Our goal is to maximize the sum rate of all users by jointly optimizing the STAR-RIS's beamforming vectors, the UAV's trajectory and power allocation. We decompose the formulated non-convex problem into three subproblems and solve them alternately to obtain the solution. Simulations show that: 1) the STAR-RIS achieves a higher sum rate than traditional RIS; 2) to exploit the benefits of STAR-RIS, the UAV's trajectory is closer to STAR-RIS than that of RIS; 3) the energy splitting for reflection and transmission highly depends on the real-time trajectory of UAV.
* 5 pages, 4 figures
Semantic-enhanced Image Clustering
Aug 21, 2022
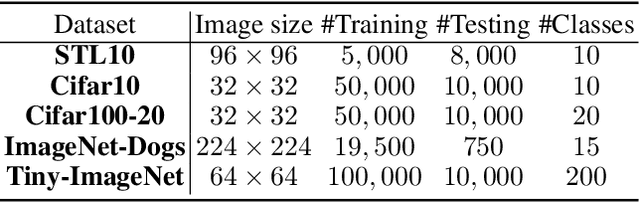
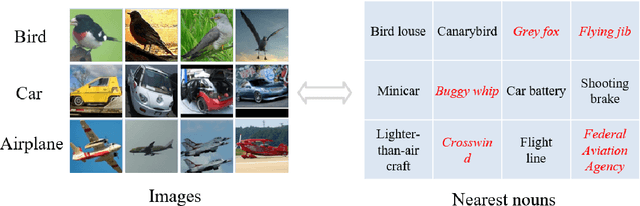
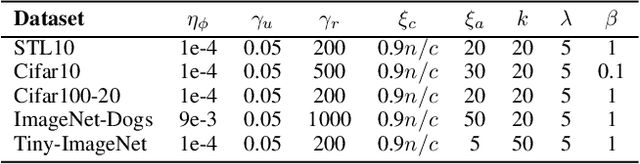
Image clustering is an important, and open challenge task in computer vision. Although many methods have been proposed to solve the image clustering task, they only explore images and uncover clusters according to the image features, thus are unable to distinguish visually similar but semantically different images. In this paper, we propose to investigate the task of image clustering with the help of visual-language pre-training model. Different from the zero-shot setting in which the class names are known, we only know the number of clusters in this setting. Therefore, how to map images to a proper semantic space and how to cluster images from both image and semantic spaces are two key problems. To solve the above problems, we propose a novel image clustering method guided by the visual-language pre-training model CLIP, named as \textbf{Semantic-enhanced Image Clustering (SIC)}. In this new method, we propose a method to map the given images to a proper semantic space first and efficient methods to generate pseudo-labels according to the relationships between images and semantics. Finally, we propose to perform clustering with the consistency learning in both image space and semantic space, in a self-supervised learning fashion. Theoretical result on convergence analysis shows that our proposed method can converge in sublinear speed. Theoretical analysis on expectation risk also shows that we can reduce the expectation risk by improving the neighborhood consistency or prediction confidence or reducing neighborhood imbalance. Experimental results on five benchmark datasets clearly show the superiority of our new method.
Communication-Efficient Collaborative Best Arm Identification
Aug 18, 2022

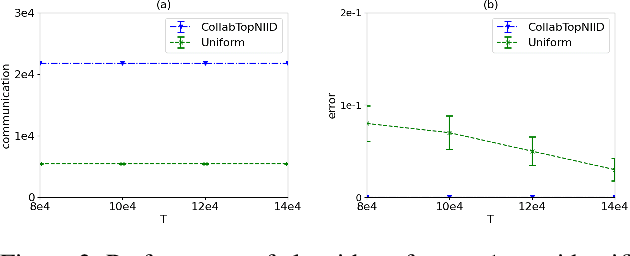
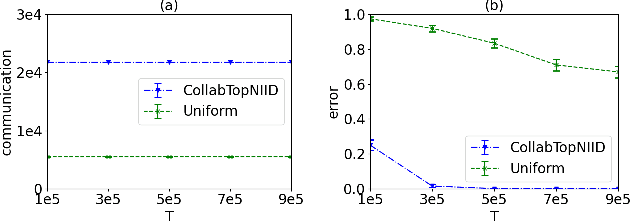
We investigate top-$m$ arm identification, a basic problem in bandit theory, in a multi-agent learning model in which agents collaborate to learn an objective function. We are interested in designing collaborative learning algorithms that achieve maximum speedup (compared to single-agent learning algorithms) using minimum communication cost, as communication is frequently the bottleneck in multi-agent learning. We give both algorithmic and impossibility results, and conduct a set of experiments to demonstrate the effectiveness of our algorithms.