 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorBench: Benchmarking Foundation Models for Behavioral Science Tasks
Jun 23, 2026Foundation models have been increasingly applied to behavioral science domains such as psychology, sociology, and economics. While these models show promise in individual tasks such as survey response prediction and human-subject experiment simulation, there remains no systematic understanding of how well they perform across diverse behavioral science tasks, contexts, and populations. We introduce BehaviorBench, a comprehensive benchmark that evaluates foundation models along four core capabilities: (1) behavior prediction and simulation, (2) strategic decision-making, (3) subject-trait inference, and (4) behavioral knowledge application. Crucially, BehaviorBench evaluates model outputs at both the individual and distributional levels, capturing not only per-subject accuracy but also population-level alignment, an essential requirement for behavioral validity. Leveraging the tasks in BehaviorBench, we further develop Be.FM-1.5, extending the Be.FM family of behavioral foundation models fine-tuned on behavioral data. Our results reveal a considerable gap: proprietary general-purpose models excel at individual-level prediction and knowledge-intensive tasks, whereas behavioral foundation models, fine-tuned on behavioral data, achieve substantially stronger distributional alignment. Notably, Be.FM-1.5 leads on distributional metrics and remains competitive on individual-level metrics, suggesting that proper behavioral adaptation can close the gap. Our results highlight the importance of distributional evaluation, establish BehaviorBench as a foundation for developing and assessing behaviorally aligned AI systems, and demonstrate Be.FM-1.5's potential for a broad range of behavioral science studies. Our BehaviorBench and Be.FM-1.5 models can be accessed via https://umich-foreseer.github.io/behaviorbench/.
Be.FM: Open Foundation Models for Human Behavior
May 29, 2025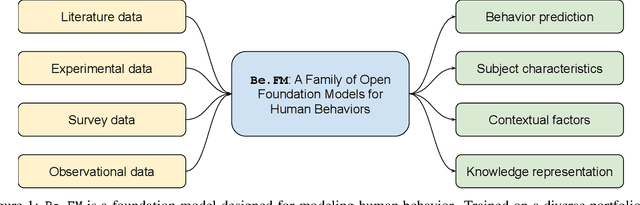

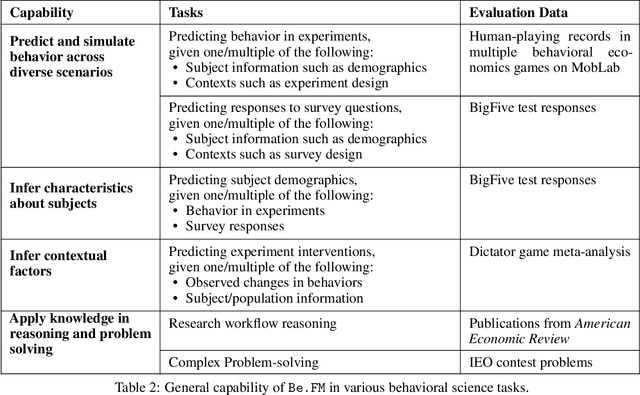
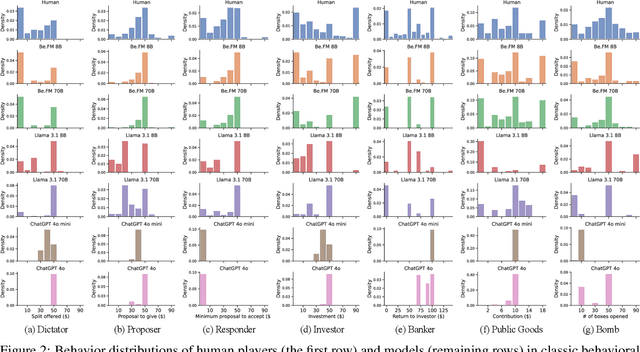
Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
Using Language Models to Decipher the Motivation Behind Human Behaviors
Mar 20, 2025



AI presents a novel tool for deciphering the motivations behind human behaviors. We show that by varying prompts to a large language model, we can elicit a full range of human behaviors in a variety of different scenarios in terms of classic economic games. Then by analyzing which prompts are needed to elicit which behaviors, we can infer (decipher) the motivations behind the human behaviors. We also show how one can analyze the prompts to reveal relationships between the classic economic games, providing new insight into what different economic scenarios induce people to think about. We also show how this deciphering process can be used to understand differences in the behavioral tendencies of different populations.
How Different AI Chatbots Behave? Benchmarking Large Language Models in Behavioral Economics Games
Dec 16, 2024The deployment of large language models (LLMs) in diverse applications requires a thorough understanding of their decision-making strategies and behavioral patterns. As a supplement to a recent study on the behavioral Turing test, this paper presents a comprehensive analysis of five leading LLM-based chatbot families as they navigate a series of behavioral economics games. By benchmarking these AI chatbots, we aim to uncover and document both common and distinct behavioral patterns across a range of scenarios. The findings provide valuable insights into the strategic preferences of each LLM, highlighting potential implications for their deployment in critical decision-making roles.
A Turing Test: Are AI Chatbots Behaviorally Similar to Humans?
Nov 19, 2023



We administer a Turing Test to AI Chatbots. We examine how Chatbots behave in a suite of classic behavioral games that are designed to elicit characteristics such as trust, fairness, risk-aversion, cooperation, \textit{etc.}; as well as a traditional Big-5 psychological survey that measures personality traits. ChatGPT-4 passes the Turing Test in that it consistently exhibits human-like behavioral and personality traits based on a comparison to the behavior of hundreds of thousands of humans from more than 50 countries. Chatbots also modify their behavior based on previous experience and contexts ``as if'' they were learning from the interactions, and change their behavior in response to different framings of the same strategic situation. Their behaviors are often distinct from average and modal human behaviors, in which case they tend to behave on the more altruistic and cooperative end of the distribution. We estimate that they act as if they are maximizing an average of their own and partner's payoff.