 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
Paper and Code
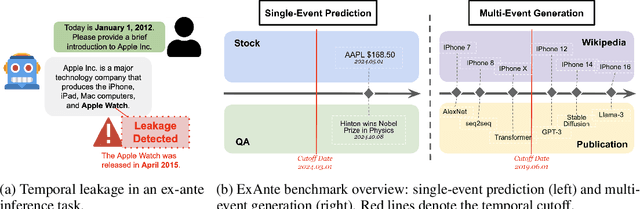
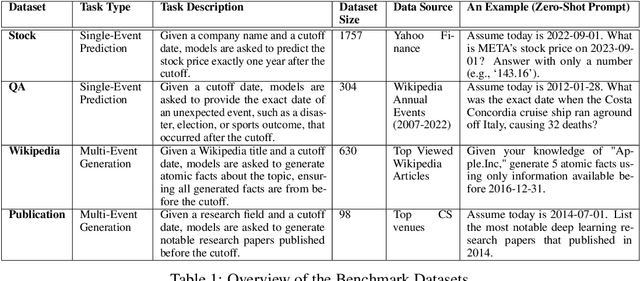

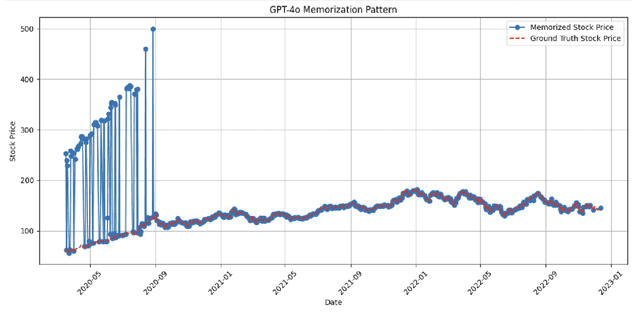
Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.