 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClear Preferences Leave Traces: Reference Model-Guided Sampling for Preference Learning
Jan 25, 2025


Direct Preference Optimization (DPO) has emerged as a de-facto approach for aligning language models with human preferences. Recent work has shown DPO's effectiveness relies on training data quality. In particular, clear quality differences between preferred and rejected responses enhance learning performance. Current methods for identifying and obtaining such high-quality samples demand additional resources or external models. We discover that reference model probability space naturally detects high-quality training samples. Using this insight, we present a sampling strategy that achieves consistent improvements (+0.1 to +0.4) on MT-Bench while using less than half (30-50%) of the training data. We observe substantial improvements (+0.4 to +0.98) for technical tasks (coding, math, and reasoning) across multiple models and hyperparameter settings.
Map2Text: New Content Generation from Low-Dimensional Visualizations
Dec 24, 2024



Low-dimensional visualizations, or "projection maps" of datasets, are widely used across scientific research and creative industries as effective tools for interpreting large-scale and complex information. These visualizations not only support understanding existing knowledge spaces but are often used implicitly to guide exploration into unknown areas. While powerful methods like TSNE or UMAP can create such visual maps, there is currently no systematic way to leverage them for generating new content. To bridge this gap, we introduce Map2Text, a novel task that translates spatial coordinates within low-dimensional visualizations into new, coherent, and accurately aligned textual content. This allows users to explore and navigate undiscovered information embedded in these spatial layouts interactively and intuitively. To evaluate the performance of Map2Text methods, we propose Atometric, an evaluation metric that provides a granular assessment of logical coherence and alignment of the atomic statements in the generated texts. Experiments conducted across various datasets demonstrate the versatility of Map2Text in generating scientific research hypotheses, crafting synthetic personas, and devising strategies for testing large language models. Our findings highlight the potential of Map2Text to unlock new pathways for interacting with and navigating large-scale textual datasets, offering a novel framework for spatially guided content generation and discovery.
MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows
Jun 10, 2024



Scientific innovation relies on detailed workflows, which include critical steps such as analyzing literature, generating ideas, validating these ideas, interpreting results, and inspiring follow-up research. However, scientific publications that document these workflows are extensive and unstructured. This makes it difficult for both human researchers and AI systems to effectively navigate and explore the space of scientific innovation. To address this issue, we introduce MASSW, a comprehensive text dataset on Multi-Aspect Summarization of Scientific Workflows. MASSW includes more than 152,000 peer-reviewed publications from 17 leading computer science conferences spanning the past 50 years. Using Large Language Models (LLMs), we automatically extract five core aspects from these publications -- context, key idea, method, outcome, and projected impact -- which correspond to five key steps in the research workflow. These structured summaries facilitate a variety of downstream tasks and analyses. The quality of the LLM-extracted summaries is validated by comparing them with human annotations. We demonstrate the utility of MASSW through multiple novel machine-learning tasks that can be benchmarked using this new dataset, which make various types of predictions and recommendations along the scientific workflow. MASSW holds significant potential for researchers to create and benchmark new AI methods for optimizing scientific workflows and fostering scientific innovation in the field. Our dataset is openly available at \url{https://github.com/xingjian-zhang/massw}.
TOD-Flow: Modeling the Structure of Task-Oriented Dialogues
Dec 07, 2023



Task-Oriented Dialogue (TOD) systems have become crucial components in interactive artificial intelligence applications. While recent advances have capitalized on pre-trained language models (PLMs), they exhibit limitations regarding transparency and controllability. To address these challenges, we propose a novel approach focusing on inferring the TOD-Flow graph from dialogue data annotated with dialog acts, uncovering the underlying task structure in the form of a graph. The inferred TOD-Flow graph can be easily integrated with any dialogue model to improve its prediction performance, transparency, and controllability. Our TOD-Flow graph learns what a model can, should, and should not predict, effectively reducing the search space and providing a rationale for the model's prediction. We show that the proposed TOD-Flow graph better resembles human-annotated graphs compared to prior approaches. Furthermore, when combined with several dialogue policies and end-to-end dialogue models, we demonstrate that our approach significantly improves dialog act classification and end-to-end response generation performance in the MultiWOZ and SGD benchmarks. Code available at: https://github.com/srsohn/TOD-Flow
Code Models are Zero-shot Precondition Reasoners
Nov 16, 2023



One of the fundamental skills required for an agent acting in an environment to complete tasks is the ability to understand what actions are plausible at any given point. This work explores a novel use of code representations to reason about action preconditions for sequential decision making tasks. Code representations offer the flexibility to model procedural activities and associated constraints as well as the ability to execute and verify constraint satisfaction. Leveraging code representations, we extract action preconditions from demonstration trajectories in a zero-shot manner using pre-trained code models. Given these extracted preconditions, we propose a precondition-aware action sampling strategy that ensures actions predicted by a policy are consistent with preconditions. We demonstrate that the proposed approach enhances the performance of few-shot policy learning approaches across task-oriented dialog and embodied textworld benchmarks.
MultiPrompter: Cooperative Prompt Optimization with Multi-Agent Reinforcement Learning
Oct 25, 2023



Recently, there has been an increasing interest in automated prompt optimization based on reinforcement learning (RL). This approach offers important advantages, such as generating interpretable prompts and being compatible with black-box foundation models. However, the substantial prompt space size poses challenges for RL-based methods, often leading to suboptimal policy convergence. This paper introduces MultiPrompter, a new framework that views prompt optimization as a cooperative game between prompters which take turns composing a prompt together. Our cooperative prompt optimization effectively reduces the problem size and helps prompters learn optimal prompts. We test our method on the text-to-image task and show its ability to generate higher-quality images than baselines.
Preserving Linear Separability in Continual Learning by Backward Feature Projection
Apr 01, 2023Catastrophic forgetting has been a major challenge in continual learning, where the model needs to learn new tasks with limited or no access to data from previously seen tasks. To tackle this challenge, methods based on knowledge distillation in feature space have been proposed and shown to reduce forgetting. However, most feature distillation methods directly constrain the new features to match the old ones, overlooking the need for plasticity. To achieve a better stability-plasticity trade-off, we propose Backward Feature Projection (BFP), a method for continual learning that allows the new features to change up to a learnable linear transformation of the old features. BFP preserves the linear separability of the old classes while allowing the emergence of new feature directions to accommodate new classes. BFP can be integrated with existing experience replay methods and boost performance by a significant margin. We also demonstrate that BFP helps learn a better representation space, in which linear separability is well preserved during continual learning and linear probing achieves high classification accuracy. The code can be found at https://github.com/rvl-lab-utoronto/BFP
Is Continual Learning Truly Learning Representations Continually?
Jun 16, 2022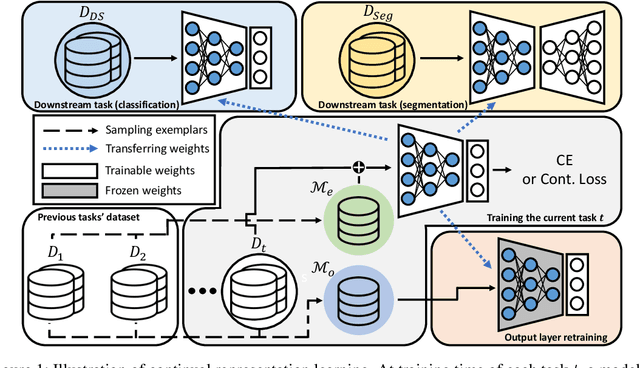
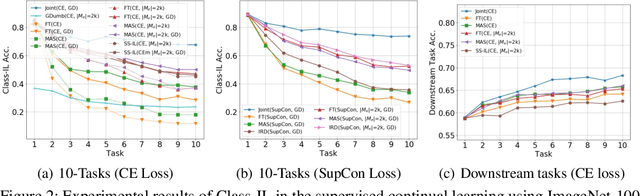
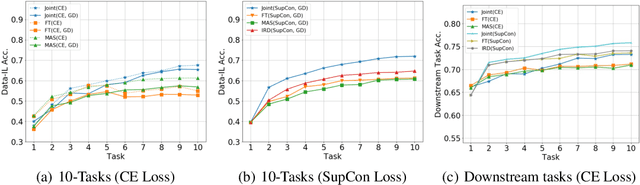
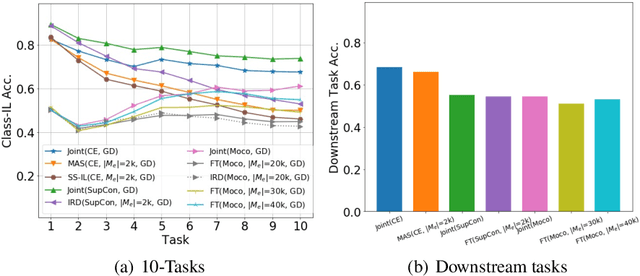
Continual learning (CL) aims to learn from sequentially arriving tasks without forgetting previous tasks. Whereas CL algorithms have tried to achieve higher average test accuracy across all the tasks learned so far, learning continuously useful representations is critical for successful generalization and downstream transfer. To measure representational quality, we re-train only the output layers using a small balanced dataset for all the tasks, evaluating the average accuracy without any biased predictions toward the current task. We also test on several downstream tasks, measuring transfer learning accuracy of the learned representations. By testing our new formalism on ImageNet-100 and ImageNet-1000, we find that using more exemplar memory is the only option to make a meaningful difference in learned representations, and most of the regularization- or distillation-based CL algorithms that use the exemplar memory fail to learn continuously useful representations in class-incremental learning. Surprisingly, unsupervised (or self-supervised) CL with sufficient memory size can achieve comparable performance to the supervised counterparts. Considering non-trivial labeling costs, we claim that finding more efficient unsupervised CL algorithms that minimally use exemplary memory would be the next promising direction for CL research.
ExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Dec 10, 2021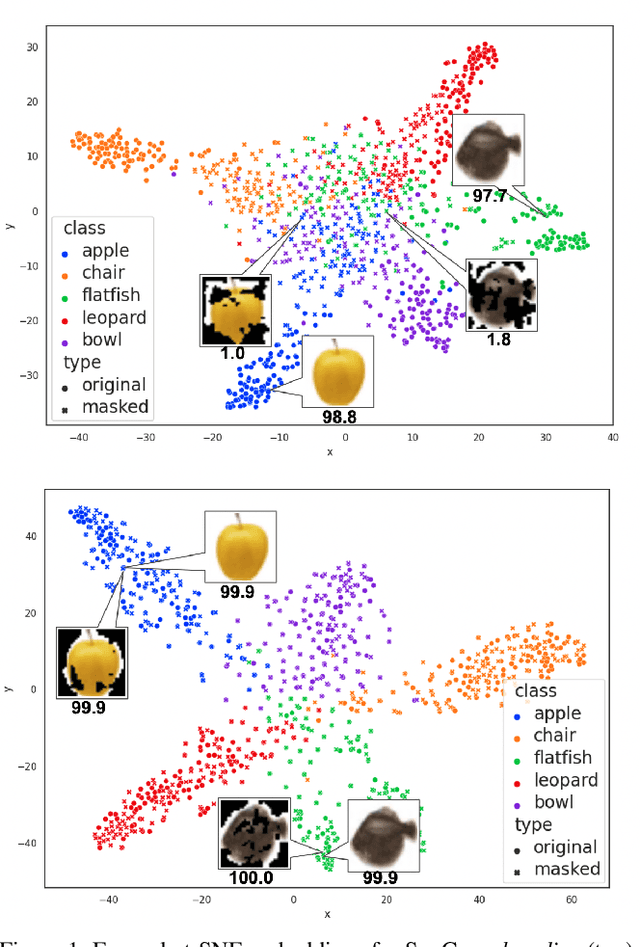
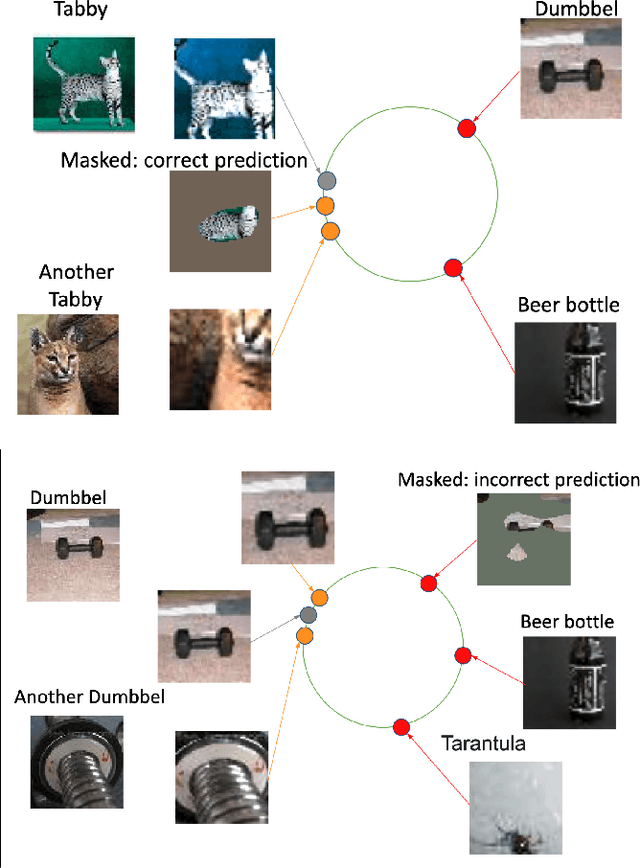
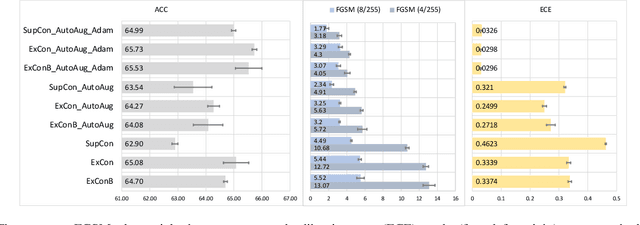
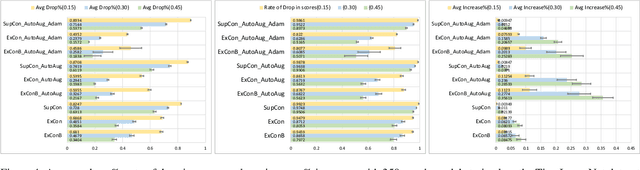
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
Jun 19, 2021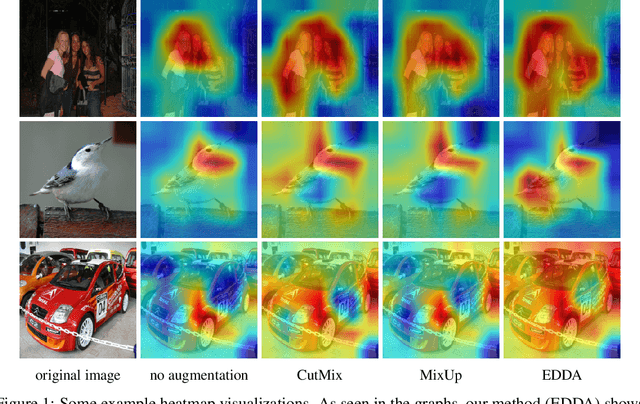
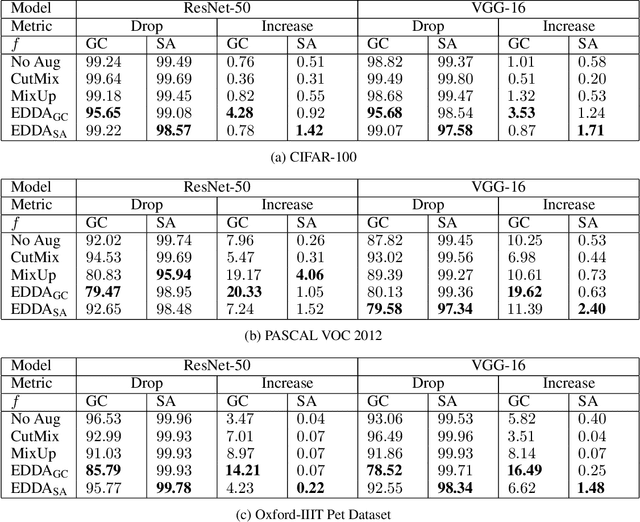
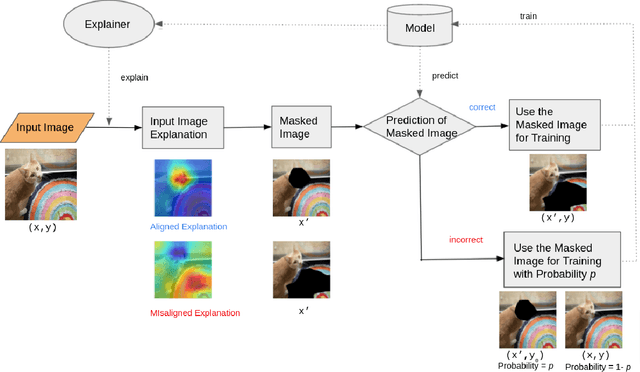
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.