 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADER: Paillier-based Secure Decentralized Social Recommendation
Jan 15, 2026The prevalence of recommendation systems also brings privacy concerns to both the users and the sellers, as centralized platforms collect as much data as possible from them. To keep the data private, we propose PADER: a Paillier-based secure decentralized social recommendation system. In this system, the users and the sellers are nodes in a decentralized network. The training and inference of the recommendation model are carried out securely in a decentralized manner, without the involvement of a centralized platform. To this end, we apply the Paillier cryptosystem to the SoReg (Social Regularization) model, which exploits both user's ratings and social relations. We view the SoReg model as a two-party secure polynomial evaluation problem and observe that the simple bipartite computation may result in poor efficiency. To improve efficiency, we design secure addition and multiplication protocols to support secure computation on any arithmetic circuit, along with an optimal data packing scheme that is suitable for the polynomial computations of real values. Experiment results show that our method only takes about one second to iterate through one user with hundreds of ratings, and training with ~500K ratings for one epoch only takes <3 hours, which shows that the method is practical in real applications. The code is available at https://github.com/GarminQ/PADER.
ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025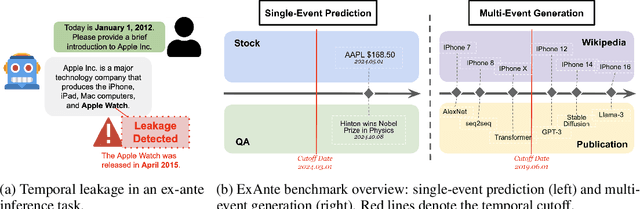
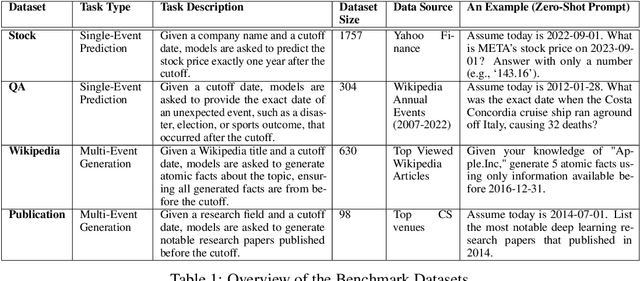

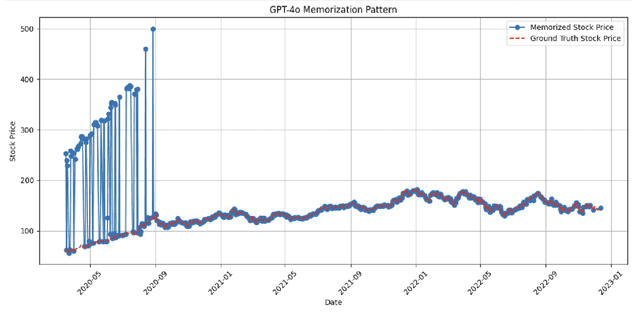
Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Text-to-Pipeline: Bridging Natural Language and Data Preparation Pipelines
May 21, 2025



Data preparation (DP) transforms raw data into a form suitable for downstream applications, typically by composing operations into executable pipelines. Building such pipelines is time-consuming and requires sophisticated programming skills. If we can build the pipelines with natural language (NL), the technical barrier of DP will be significantly reduced. However, constructing DP pipelines from NL instructions remains underexplored. To fill the gap, we introduce Text-to-Pipeline, a new task that translates NL data preparation instructions into DP pipelines. Furthermore, we develop a benchmark named PARROT to support systematic evaluation. To simulate realistic DP scenarios, we mined transformation patterns from production pipelines and instantiated them on 23,009 real-world tables collected from six public sources. The resulting benchmark comprises ~18,000 pipelines covering 16 core DP operators. We evaluated cutting-edge large language models on PARROTand observed that they only solved 72.86% of the cases, revealing notable limitations in instruction understanding and multi-step reasoning. To address this, we propose Pipeline-Agent, a stronger baseline that iteratively predicts and executes operations with intermediate table feedback, achieving the best performance of 76.17%. Despite this improvement, there remains substantial room for progress on Text-to-Pipeline. Our data, codes, and evaluation tools are available at https://anonymous.4open.science/r/Text-to-Pipeline.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
Meta Semantic Template for Evaluation of Large Language Models
Oct 19, 2023

Do large language models (LLMs) genuinely understand the semantics of the language, or just memorize the training data? The recent concern on potential data contamination of LLMs has raised awareness of the community to conduct research on LLMs evaluation. In this paper, we propose MSTemp, an approach that creates meta semantic templates to evaluate the semantic understanding ability of LLMs. The core of MSTemp is not to perform evaluation directly on existing benchmark datasets, but to generate new out-of-distribution (OOD) evaluation sets using existing datasets as seeds. Specifically, for a given sentence, MSTemp leverages another language model to generate new samples while preserving its semantics. The new samples are called semantic templates to the original sentence. Then, MSTemp generates evaluation samples via sentence parsing and random word replacement on the semantic templates. MSTemp is highly flexible, dynamic, and cost-effective. Our initial experiments show that MSTemp-generated samples can significantly reduce the performance of LLMs using existing datasets as seeds. We hope this initial work can shed light on future research of LLMs evaluation.
Ranking & Reweighting Improves Group Distributional Robustness
May 09, 2023Recent work has shown that standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on underrepresented groups due to the prevalence of spurious features. A predominant approach to tackle this group robustness problem minimizes the worst group error (akin to a minimax strategy) on the training data, hoping it will generalize well on the testing data. However, this is often suboptimal, especially when the out-of-distribution (OOD) test data contains previously unseen groups. Inspired by ideas from the information retrieval and learning-to-rank literature, this paper first proposes to use Discounted Cumulative Gain (DCG) as a metric of model quality for facilitating better hyperparameter tuning and model selection. Being a ranking-based metric, DCG weights multiple poorly-performing groups (instead of considering just the group with the worst performance). As a natural next step, we build on our results to propose a ranking-based training method called Discounted Rank Upweighting (DRU), which differentially reweights a ranked list of poorly-performing groups in the training data to learn models that exhibit strong OOD performance on the test data. Results on several synthetic and real-world datasets highlight the superior generalization ability of our group-ranking-based (akin to soft-minimax) approach in selecting and learning models that are robust to group distributional shifts.