 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Reliability of Post-training Quantization: a Particular Focus on Worst-case Performance
Mar 23, 2023Post-training quantization (PTQ) is a popular method for compressing deep neural networks (DNNs) without modifying their original architecture or training procedures. Despite its effectiveness and convenience, the reliability of PTQ methods in the presence of some extrem cases such as distribution shift and data noise remains largely unexplored. This paper first investigates this problem on various commonly-used PTQ methods. We aim to answer several research questions related to the influence of calibration set distribution variations, calibration paradigm selection, and data augmentation or sampling strategies on PTQ reliability. A systematic evaluation process is conducted across a wide range of tasks and commonly-used PTQ paradigms. The results show that most existing PTQ methods are not reliable enough in term of the worst-case group performance, highlighting the need for more robust methods. Our findings provide insights for developing PTQ methods that can effectively handle distribution shift scenarios and enable the deployment of quantized DNNs in real-world applications.
DynamicLight: Dynamically Tuning Traffic Signal Duration with DRL
Nov 02, 2022



Deep reinforcement learning (DRL) is becoming increasingly popular in implementing traffic signal control (TSC). However, most existing DRL methods employ fixed control strategies, making traffic signal phase duration less flexible. Additionally, the trend of using more complex DRL models makes real-life deployment more challenging. To address these two challenges, we firstly propose a two-stage DRL framework, named DynamicLight, which uses Max Queue-Length to select the proper phase and employs a deep Q-learning network to determine the duration of the corresponding phase. Based on the design of DynamicLight, we also introduce two variants: (1) DynamicLight-Lite, which addresses the first challenge by using only 19 parameters to achieve dynamic phase duration settings; and (2) DynamicLight-Cycle, which tackles the second challenge by actuating a set of phases in a fixed cyclical order to implement flexible phase duration in the respective cyclical phase structure. Numerical experiments are conducted using both real-world and synthetic datasets, covering four most commonly adopted traffic signal intersections in real life. Experimental results show that: (1) DynamicLight can learn satisfactorily on determining the phase duration and achieve a new state-of-the-art, with improvement up to 6% compared to the baselines in terms of adjusted average travel time; (2) DynamicLight-Lite matches or outperforms most baseline methods with only 19 parameters; and (3) DynamicLight-Cycle demonstrates high performance for current TSC systems without remarkable modification in an actual deployment. Our code is released at Github.
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Oct 06, 2022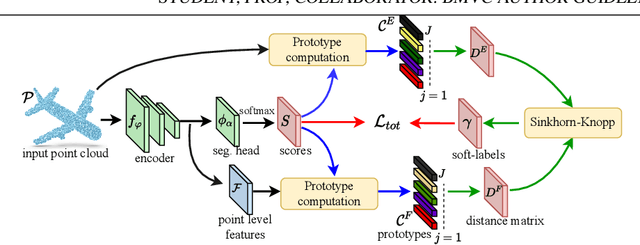

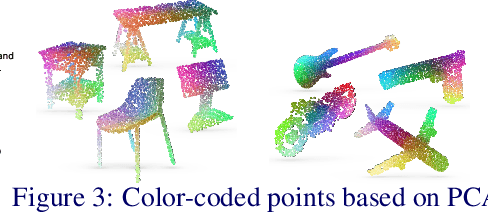
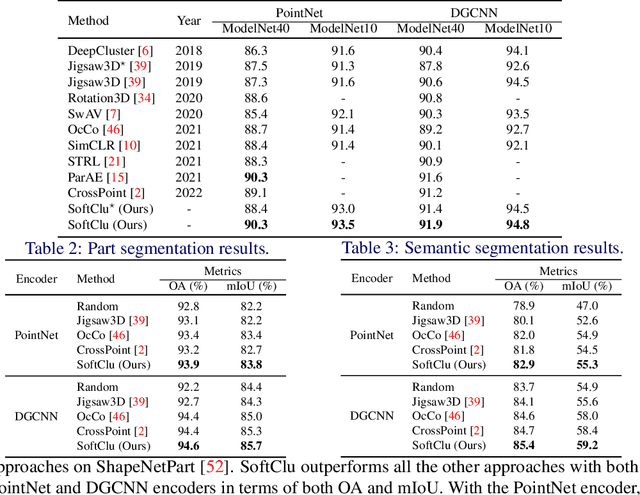
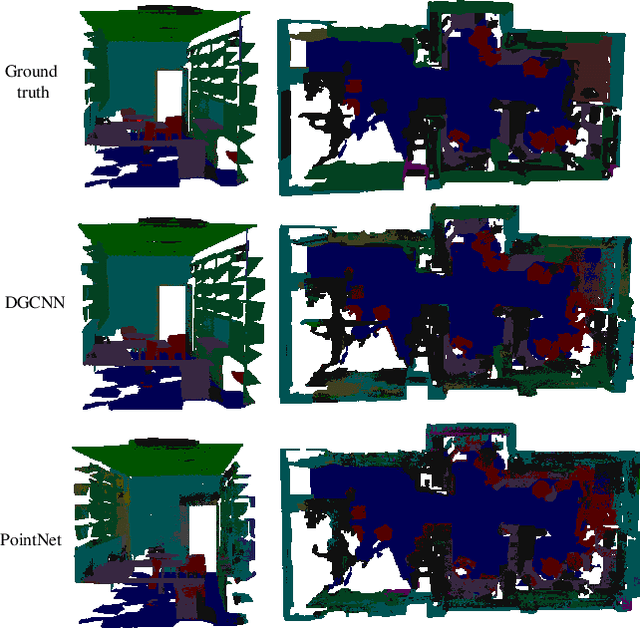
Unsupervised learning on 3D point clouds has undergone a rapid evolution, especially thanks to data augmentation-based contrastive methods. However, data augmentation is not ideal as it requires a careful selection of the type of augmentations to perform, which in turn can affect the geometric and semantic information learned by the network during self-training. To overcome this issue, we propose an augmentation-free unsupervised approach for point clouds to learn transferable point-level features via soft clustering, named SoftClu. SoftClu assumes that the points belonging to a cluster should be close to each other in both geometric and feature spaces. This differs from typical contrastive learning, which builds similar representations for a whole point cloud and its augmented versions. We exploit the affiliation of points to their clusters as a proxy to enable self-training through a pseudo-label prediction task. Under the constraint that these pseudo-labels induce the equipartition of the point cloud, we cast SoftClu as an optimal transport problem. We formulate an unsupervised loss to minimize the standard cross-entropy between pseudo-labels and predicted labels. Experiments on downstream applications, such as 3D object classification, part segmentation, and semantic segmentation, show the effectiveness of our framework in outperforming state-of-the-art techniques.
Lightweight Vision Transformer with Cross Feature Attention
Jul 15, 2022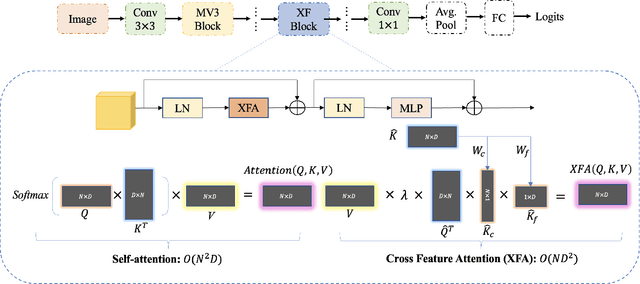
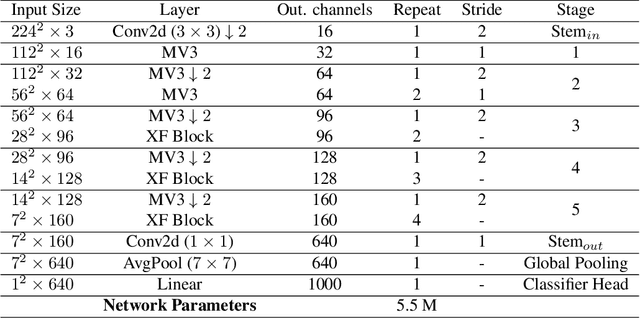


Recent advances in vision transformers (ViTs) have achieved great performance in visual recognition tasks. Convolutional neural networks (CNNs) exploit spatial inductive bias to learn visual representations, but these networks are spatially local. ViTs can learn global representations with their self-attention mechanism, but they are usually heavy-weight and unsuitable for mobile devices. In this paper, we propose cross feature attention (XFA) to bring down computation cost for transformers, and combine efficient mobile CNNs to form a novel efficient light-weight CNN-ViT hybrid model, XFormer, which can serve as a general-purpose backbone to learn both global and local representation. Experimental results show that XFormer outperforms numerous CNN and ViT-based models across different tasks and datasets. On ImageNet1K dataset, XFormer achieves top-1 accuracy of 78.5% with 5.5 million parameters, which is 2.2% and 6.3% more accurate than EfficientNet-B0 (CNN-based) and DeiT (ViT-based) for similar number of parameters. Our model also performs well when transferring to object detection and semantic segmentation tasks. On MS COCO dataset, XFormer exceeds MobileNetV2 by 10.5 AP (22.7 -> 33.2 AP) in YOLOv3 framework with only 6.3M parameters and 3.8G FLOPs. On Cityscapes dataset, with only a simple all-MLP decoder, XFormer achieves mIoU of 78.5 and FPS of 15.3, surpassing state-of-the-art lightweight segmentation networks.
Self-attention on Multi-Shifted Windows for Scene Segmentation
Jul 10, 2022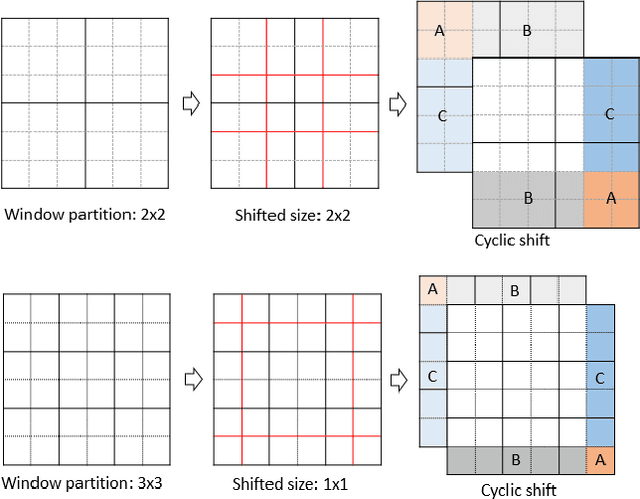
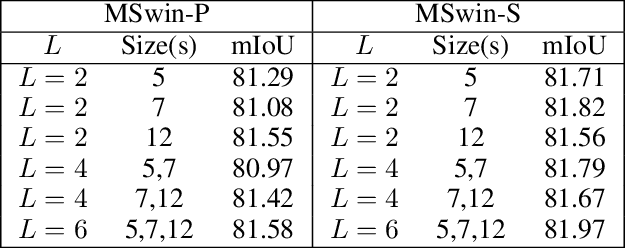
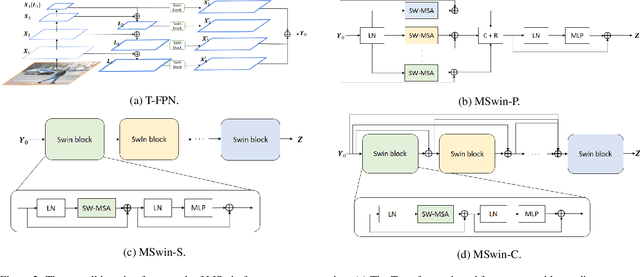
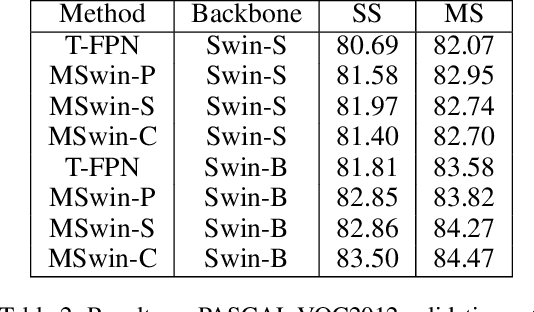
Scene segmentation in images is a fundamental yet challenging problem in visual content understanding, which is to learn a model to assign every image pixel to a categorical label. One of the challenges for this learning task is to consider the spatial and semantic relationships to obtain descriptive feature representations, so learning the feature maps from multiple scales is a common practice in scene segmentation. In this paper, we explore the effective use of self-attention within multi-scale image windows to learn descriptive visual features, then propose three different strategies to aggregate these feature maps to decode the feature representation for dense prediction. Our design is based on the recently proposed Swin Transformer models, which totally discards convolution operations. With the simple yet effective multi-scale feature learning and aggregation, our models achieve very promising performance on four public scene segmentation datasets, PASCAL VOC2012, COCO-Stuff 10K, ADE20K and Cityscapes.
Unsupervised Learning on 3D Point Clouds by Clustering and Contrasting
Feb 14, 2022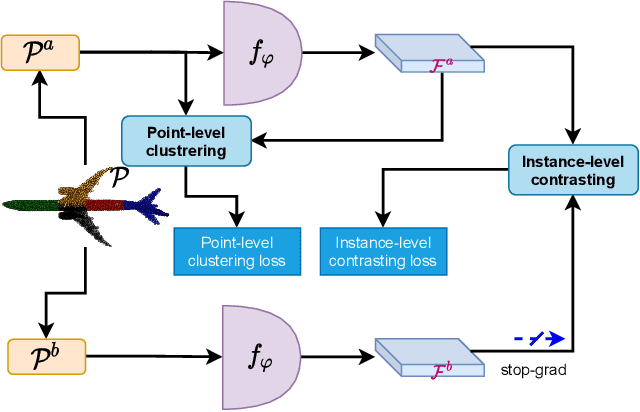
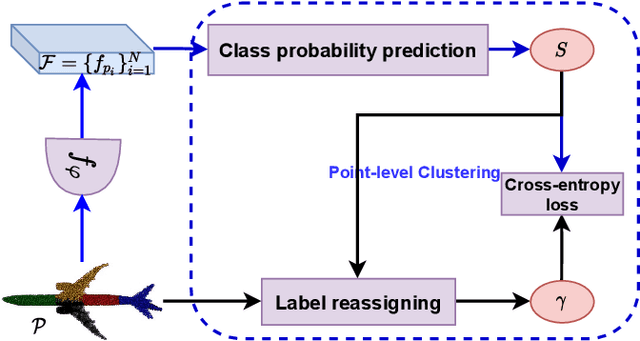
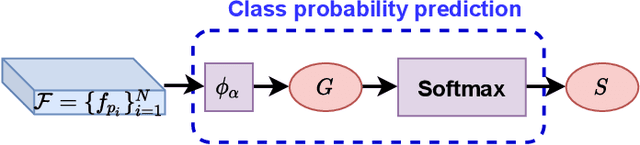
Learning from unlabeled or partially labeled data to alleviate human labeling remains a challenging research topic in 3D modeling. Along this line, unsupervised representation learning is a promising direction to auto-extract features without human intervention. This paper proposes a general unsupervised approach, named \textbf{ConClu}, to perform the learning of point-wise and global features by jointly leveraging point-level clustering and instance-level contrasting. Specifically, for one thing, we design an Expectation-Maximization (EM) like soft clustering algorithm that provides local supervision to extract discriminating local features based on optimal transport. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently using a fast variant of the Sinkhorn-Knopp algorithm. For another, we provide an instance-level contrasting method to learn the global geometry, which is formulated by maximizing the similarity between two augmentations of one point cloud. Experimental evaluations on downstream applications such as 3D object classification and semantic segmentation demonstrate the effectiveness of our framework and show that it can outperform state-of-the-art techniques.
Knowledge intensive state design for traffic signal control
Dec 30, 2021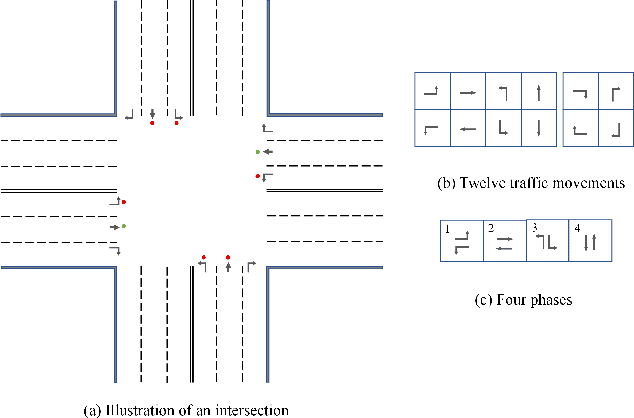

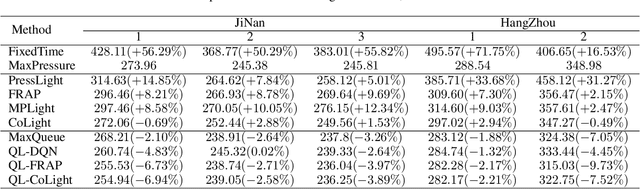
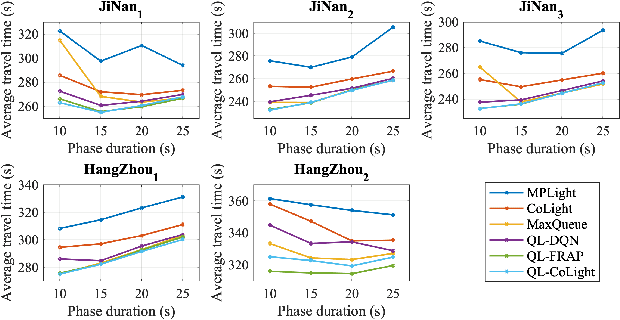
There is a general trend of applying reinforcement learning (RL) techniques for traffic signal control (TSC). Recently, most studies pay attention to the neural network design and rarely concentrate on the state representation. Does the design of state representation has a good impact on TSC? In this paper, we (1) propose an effective state representation as queue length of vehicles with intensive knowledge; (2) present a TSC method called MaxQueue based on our state representation approach; (3) develop a general RL-based TSC template called QL-XLight with queue length as state and reward and generate QL-FRAP, QL-CoLight, and QL-DQN by our QL-XLight template based on traditional and latest RL models.Through comprehensive experiments on multiple real-world datasets, we demonstrate that: (1) our MaxQueue method outperforms the latest RL based methods; (2) QL-FRAP and QL-CoLight achieves a new state-of-the-art (SOTA). In general, state representation with intensive knowledge is also essential for TSC methods. Our code is released on Github.
Expression is enough: Improving traffic signal control with advanced traffic state representation
Dec 19, 2021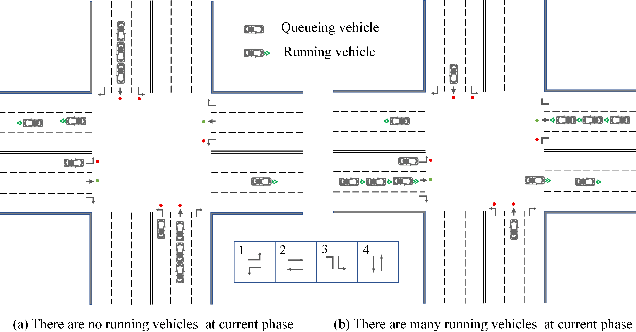


Recently, finding fundamental properties for traffic state representation is more critical than complex algorithms for traffic signal control (TSC).In this paper, we (1) present a novel, flexible and straightforward method advanced max pressure (Advanced-MP), taking both running and queueing vehicles into consideration to decide whether to change current phase; (2) novelty design the traffic movement representation with the efficient pressure and effective running vehicles from Advanced-MP, namely advanced traffic state (ATS); (3) develop an RL-based algorithm template Advanced-XLight, by combining ATS with current RL approaches and generate two RL algorithms, "Advanced-MPLight" and "Advanced-CoLight". Comprehensive experiments on multiple real-world datasets show that: (1) the Advanced-MP outperforms baseline methods, which is efficient and reliable for deployment; (2) Advanced-MPLight and Advanced-CoLight could achieve new state-of-the-art. Our code is released on Github.
Efficient Pressure: Improving efficiency for signalized intersections
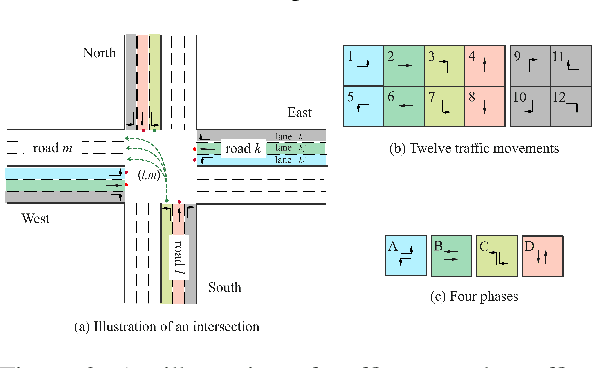
Dec 04, 2021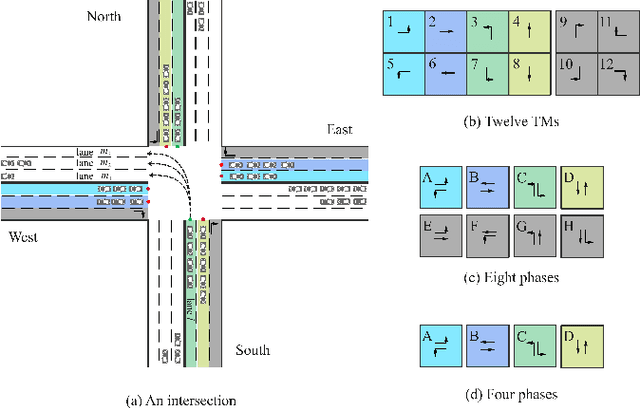

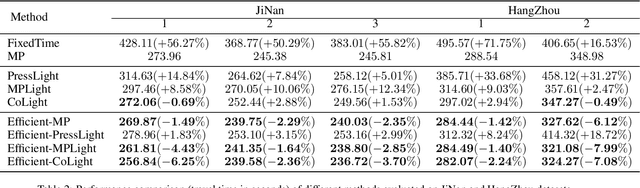
Since conventional approaches could not adapt to dynamic traffic conditions, reinforcement learning (RL) has attracted more attention to help solve the traffic signal control (TSC) problem. However, existing RL-based methods are rarely deployed considering that they are neither cost-effective in terms of computing resources nor more robust than traditional approaches, which raises a critical research question: how to construct an adaptive controller for TSC with less training and reduced complexity based on RL-based approach? To address this question, in this paper, we (1) innovatively specify the traffic movement representation as a simple but efficient pressure of vehicle queues in a traffic network, namely efficient pressure (EP); (2) build a traffic signal settings protocol, including phase duration, signal phase number and EP for TSC; (3) design a TSC approach based on the traditional max pressure (MP) approach, namely efficient max pressure (Efficient-MP) using the EP to capture the traffic state; and (4) develop a general RL-based TSC algorithm template: efficient Xlight (Efficient-XLight) under EP. Through comprehensive experiments on multiple real-world datasets in our traffic signal settings' protocol for TSC, we demonstrate that efficient pressure is complementary to traditional and RL-based modeling to design better TSC methods. Our code is released on Github.
PTQ4ViT: Post-Training Quantization Framework for Vision Transformers
Nov 24, 2021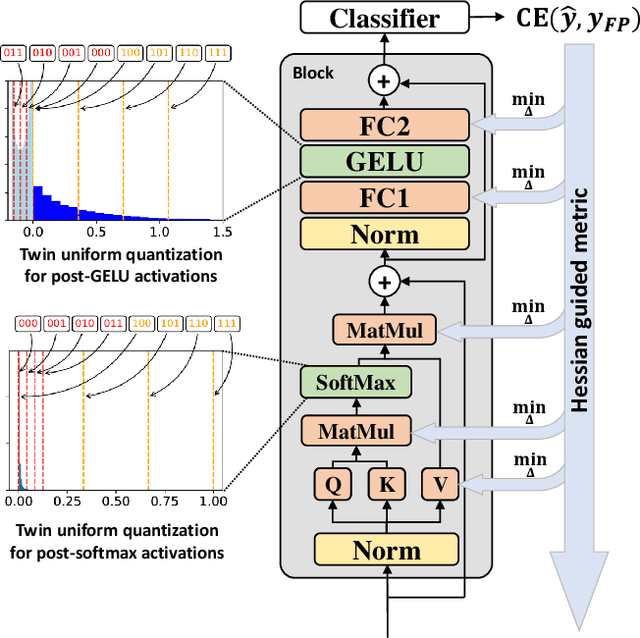
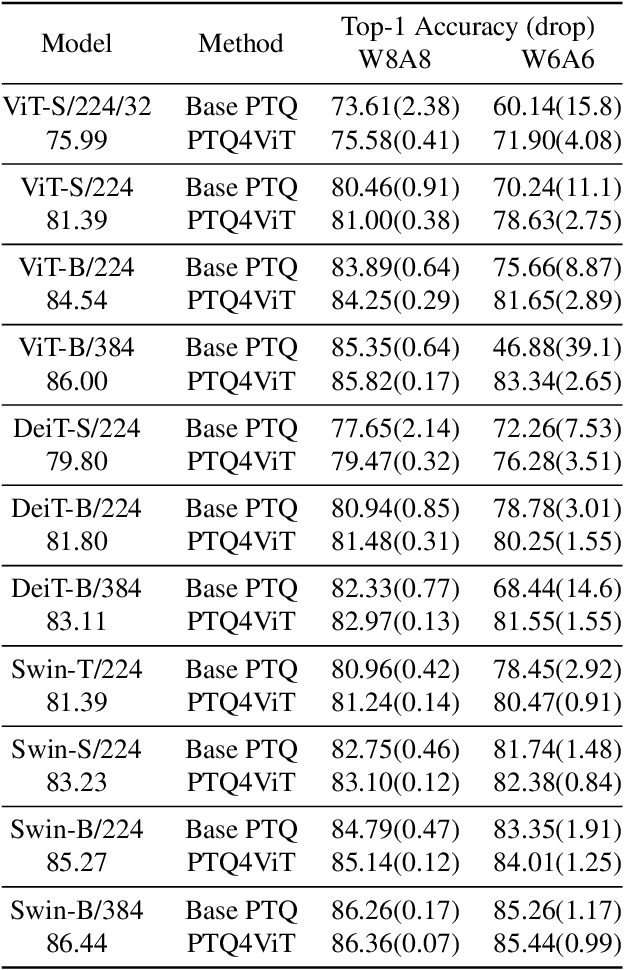
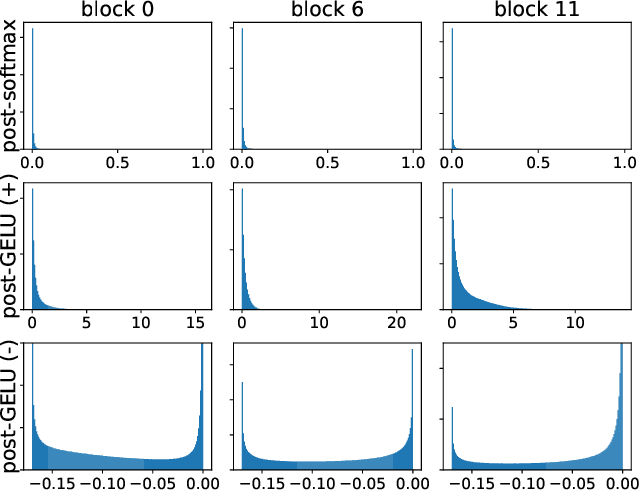
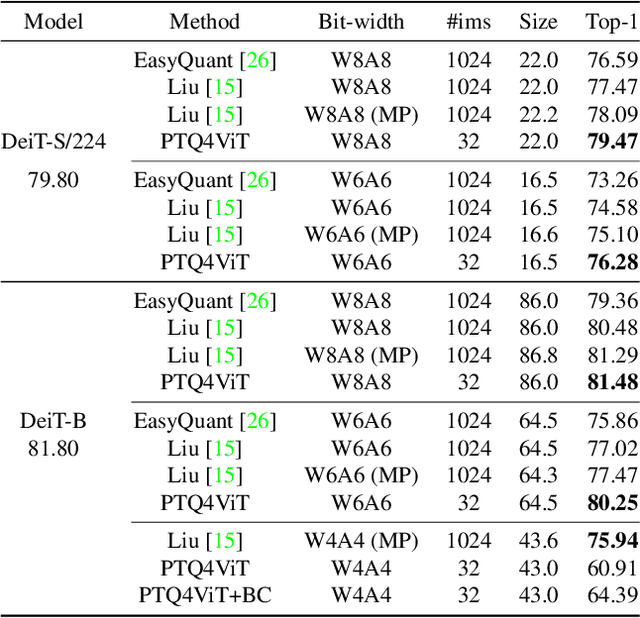
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration with a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.