 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTDP: Modulated Transformer Diffusion Policy Model
Feb 13, 2025



Recent research on robot manipulation based on Behavior Cloning (BC) has made significant progress. By combining diffusion models with BC, diffusion policiy has been proposed, enabling robots to quickly learn manipulation tasks with high success rates. However, integrating diffusion policy with high-capacity Transformer presents challenges, traditional Transformer architectures struggle to effectively integrate guiding conditions, resulting in poor performance in manipulation tasks when using Transformer-based models. In this paper, we investigate key architectural designs of Transformers and improve the traditional Transformer architecture by proposing the Modulated Transformer Diffusion Policy (MTDP) model for diffusion policy. The core of this model is the Modulated Attention module we proposed, which more effectively integrates the guiding conditions with the main input, improving the generative model's output quality and, consequently, increasing the robot's task success rate. In six experimental tasks, MTDP outperformed existing Transformer model architectures, particularly in the Toolhang experiment, where the success rate increased by 12\%. To verify the generality of Modulated Attention, we applied it to the UNet architecture to construct Modulated UNet Diffusion Policy model (MUDP), which also achieved higher success rates than existing UNet architectures across all six experiments. The Diffusion Policy uses Denoising Diffusion Probabilistic Models (DDPM) as the diffusion model. Building on this, we also explored Denoising Diffusion Implicit Models (DDIM) as the diffusion model, constructing the MTDP-I and MUDP-I model, which nearly doubled the generation speed while maintaining performance.
MPG-SAM 2: Adapting SAM 2 with Mask Priors and Global Context for Referring Video Object Segmentation
Jan 23, 2025



Referring video object segmentation (RVOS) aims to segment objects in a video according to textual descriptions, which requires the integration of multimodal information and temporal dynamics perception. The Segment Anything Model 2 (SAM 2) has shown great effectiveness across various video segmentation tasks. However, its application to offline RVOS is challenged by the translation of the text into effective prompts and a lack of global context awareness. In this paper, we propose a novel RVOS framework, termed MPG-SAM 2, to address these challenges. Specifically, MPG-SAM 2 employs a unified multimodal encoder to jointly encode video and textual features, generating semantically aligned video and text embeddings, along with multimodal class tokens. A mask prior generator utilizes the video embeddings and class tokens to create pseudo masks of target objects and global context. These masks are fed into the prompt encoder as dense prompts along with multimodal class tokens as sparse prompts to generate accurate prompts for SAM 2. To provide the online SAM 2 with a global view, we introduce a hierarchical global-historical aggregator, which allows SAM 2 to aggregate global and historical information of target objects at both pixel and object levels, enhancing the target representation and temporal consistency. Extensive experiments on several RVOS benchmarks demonstrate the superiority of MPG-SAM 2 and the effectiveness of our proposed modules.
DrivingWorld: Constructing World Model for Autonomous Driving via Video GPT
Dec 30, 2024



Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
DrivingWorld: ConstructingWorld Model for Autonomous Driving via Video GPT
Dec 27, 2024Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
3D Registration in 30 Years: A Survey
Dec 19, 2024



3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey.
ShiftedBronzes: Benchmarking and Analysis of Domain Fine-Grained Classification in Open-World Settings
Dec 17, 2024In real-world applications across specialized domains, addressing complex out-of-distribution (OOD) challenges is a common and significant concern. In this study, we concentrate on the task of fine-grained bronze ware dating, a critical aspect in the study of ancient Chinese history, and developed a benchmark dataset named ShiftedBronzes. By extensively expanding the bronze Ding dataset, ShiftedBronzes incorporates two types of bronze ware data and seven types of OOD data, which exhibit distribution shifts commonly encountered in bronze ware dating scenarios. We conduct benchmarking experiments on ShiftedBronzes and five commonly used general OOD datasets, employing a variety of widely adopted post-hoc, pre-trained Vision Large Model (VLM)-based and generation-based OOD detection methods. Through analysis of the experimental results, we validate previous conclusions regarding post-hoc, VLM-based, and generation-based methods, while also highlighting their distinct behaviors on specialized datasets. These findings underscore the unique challenges of applying general OOD detection methods to domain-specific tasks such as bronze ware dating. We hope that the ShiftedBronzes benchmark provides valuable insights into both the field of bronze ware dating and the and the development of OOD detection methods. The dataset and associated code will be available later.
PediaBench: A Comprehensive Chinese Pediatric Dataset for Benchmarking Large Language Models
Dec 09, 2024



The emergence of Large Language Models (LLMs) in the medical domain has stressed a compelling need for standard datasets to evaluate their question-answering (QA) performance. Although there have been several benchmark datasets for medical QA, they either cover common knowledge across different departments or are specific to another department rather than pediatrics. Moreover, some of them are limited to objective questions and do not measure the generation capacity of LLMs. Therefore, they cannot comprehensively assess the QA ability of LLMs in pediatrics. To fill this gap, we construct PediaBench, the first Chinese pediatric dataset for LLM evaluation. Specifically, it contains 4,565 objective questions and 1,632 subjective questions spanning 12 pediatric disease groups. It adopts an integrated scoring criterion based on different difficulty levels to thoroughly assess the proficiency of an LLM in instruction following, knowledge understanding, clinical case analysis, etc. Finally, we validate the effectiveness of PediaBench with extensive experiments on 20 open-source and commercial LLMs. Through an in-depth analysis of experimental results, we offer insights into the ability of LLMs to answer pediatric questions in the Chinese context, highlighting their limitations for further improvements. Our code and data are published at https://github.com/ACMISLab/PediaBench.
Boost 3D Reconstruction using Diffusion-based Monocular Camera Calibration
Nov 26, 2024



In this paper, we present DM-Calib, a diffusion-based approach for estimating pinhole camera intrinsic parameters from a single input image. Monocular camera calibration is essential for many 3D vision tasks. However, most existing methods depend on handcrafted assumptions or are constrained by limited training data, resulting in poor generalization across diverse real-world images. Recent advancements in stable diffusion models, trained on massive data, have shown the ability to generate high-quality images with varied characteristics. Emerging evidence indicates that these models implicitly capture the relationship between camera focal length and image content. Building on this insight, we explore how to leverage the powerful priors of diffusion models for monocular pinhole camera calibration. Specifically, we introduce a new image-based representation, termed Camera Image, which losslessly encodes the numerical camera intrinsics and integrates seamlessly with the diffusion framework. Using this representation, we reformulate the problem of estimating camera intrinsics as the generation of a dense Camera Image conditioned on an input image. By fine-tuning a stable diffusion model to generate a Camera Image from a single RGB input, we can extract camera intrinsics via a RANSAC operation. We further demonstrate that our monocular calibration method enhances performance across various 3D tasks, including zero-shot metric depth estimation, 3D metrology, pose estimation and sparse-view reconstruction. Extensive experiments on multiple public datasets show that our approach significantly outperforms baselines and provides broad benefits to 3D vision tasks. Code is available at https://github.com/JunyuanDeng/DM-Calib.
DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
Nov 22, 2024



Recently, the diffusion model has emerged as a powerful generative technique for robotic policy learning, capable of modeling multi-mode action distributions. Leveraging its capability for end-to-end autonomous driving is a promising direction. However, the numerous denoising steps in the robotic diffusion policy and the more dynamic, open-world nature of traffic scenes pose substantial challenges for generating diverse driving actions at a real-time speed. To address these challenges, we propose a novel truncated diffusion policy that incorporates prior multi-mode anchors and truncates the diffusion schedule, enabling the model to learn denoising from anchored Gaussian distribution to the multi-mode driving action distribution. Additionally, we design an efficient cascade diffusion decoder for enhanced interaction with conditional scene context. The proposed model, DiffusionDrive, demonstrates 10$\times$ reduction in denoising steps compared to vanilla diffusion policy, delivering superior diversity and quality in just 2 steps. On the planning-oriented NAVSIM dataset, with the aligned ResNet-34 backbone, DiffusionDrive achieves 88.1 PDMS without bells and whistles, setting a new record, while running at a real-time speed of 45 FPS on an NVIDIA 4090. Qualitative results on challenging scenarios further confirm that DiffusionDrive can robustly generate diverse plausible driving actions. Code and model will be available at https://github.com/hustvl/DiffusionDrive.
Brain-inspired Action Generation with Spiking Transformer Diffusion Policy Model
Nov 15, 2024

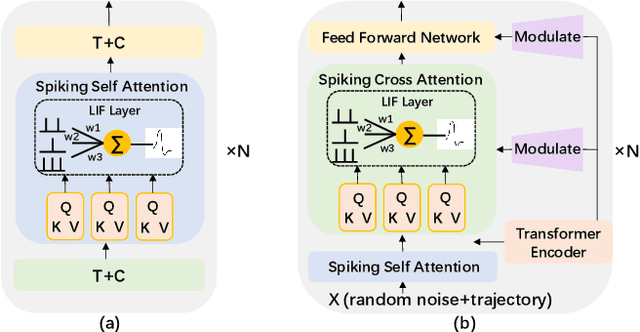

Spiking Neural Networks (SNNs) has the ability to extract spatio-temporal features due to their spiking sequence. While previous research has primarily foucus on the classification of image and reinforcement learning. In our paper, we put forward novel diffusion policy model based on Spiking Transformer Neural Networks and Denoising Diffusion Probabilistic Model (DDPM): Spiking Transformer Modulate Diffusion Policy Model (STMDP), a new brain-inspired model for generating robot action trajectories. In order to improve the performance of this model, we develop a novel decoder module: Spiking Modulate De coder (SMD), which replaces the traditional Decoder module within the Transformer architecture. Additionally, we explored the substitution of DDPM with Denoising Diffusion Implicit Models (DDIM) in our frame work. We conducted experiments across four robotic manipulation tasks and performed ablation studies on the modulate block. Our model consistently outperforms existing Transformer-based diffusion policy method. Especially in Can task, we achieved an improvement of 8%. The proposed STMDP method integrates SNNs, dffusion model and Transformer architecture, which offers new perspectives and promising directions for exploration in brain-inspired robotics.