 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-reversible Parallel Tempering for Deep Posterior Approximation
Nov 20, 2022



Parallel tempering (PT), also known as replica exchange, is the go-to workhorse for simulations of multi-modal distributions. The key to the success of PT is to adopt efficient swap schemes. The popular deterministic even-odd (DEO) scheme exploits the non-reversibility property and has successfully reduced the communication cost from $O(P^2)$ to $O(P)$ given sufficiently many $P$ chains. However, such an innovation largely disappears in big data due to the limited chains and few bias-corrected swaps. To handle this issue, we generalize the DEO scheme to promote non-reversibility and propose a few solutions to tackle the underlying bias caused by the geometric stopping time. Notably, in big data scenarios, we obtain an appealing communication cost $O(P\log P)$ based on the optimal window size. In addition, we also adopt stochastic gradient descent (SGD) with large and constant learning rates as exploration kernels. Such a user-friendly nature enables us to conduct approximation tasks for complex posteriors without much tuning costs.
SMS: Spiking Marching Scheme for Efficient Long Time Integration of Differential Equations
Nov 17, 2022



We propose a Spiking Neural Network (SNN)-based explicit numerical scheme for long time integration of time-dependent Ordinary and Partial Differential Equations (ODEs, PDEs). The core element of the method is a SNN, trained to use spike-encoded information about the solution at previous timesteps to predict spike-encoded information at the next timestep. After the network has been trained, it operates as an explicit numerical scheme that can be used to compute the solution at future timesteps, given a spike-encoded initial condition. A decoder is used to transform the evolved spiking-encoded solution back to function values. We present results from numerical experiments of using the proposed method for ODEs and PDEs of varying complexity.
Multi-Camera Calibration Free BEV Representation for 3D Object Detection
Oct 31, 2022



In advanced paradigms of autonomous driving, learning Bird's Eye View (BEV) representation from surrounding views is crucial for multi-task framework. However, existing methods based on depth estimation or camera-driven attention are not stable to obtain transformation under noisy camera parameters, mainly with two challenges, accurate depth prediction and calibration. In this work, we present a completely Multi-Camera Calibration Free Transformer (CFT) for robust BEV representation, which focuses on exploring implicit mapping, not relied on camera intrinsics and extrinsics. To guide better feature learning from image views to BEV, CFT mines potential 3D information in BEV via our designed position-aware enhancement (PA). Instead of camera-driven point-wise or global transformation, for interaction within more effective region and lower computation cost, we propose a view-aware attention which also reduces redundant computation and promotes converge. CFT achieves 49.7% NDS on the nuScenes detection task leaderboard, which is the first work removing camera parameters, comparable to other geometry-guided methods. Without temporal input and other modal information, CFT achieves second highest performance with a smaller image input 1600 * 640. Thanks to view-attention variant, CFT reduces memory and transformer FLOPs for vanilla attention by about 12% and 60%, respectively, with improved NDS by 1.0%. Moreover, its natural robustness to noisy camera parameters makes CFT more competitive.
Semi-supervised Body Parsing and Pose Estimation for Enhancing Infant General Movement Assessment
Oct 14, 2022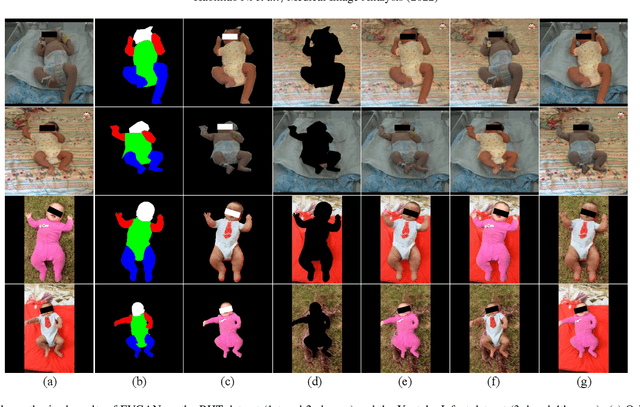
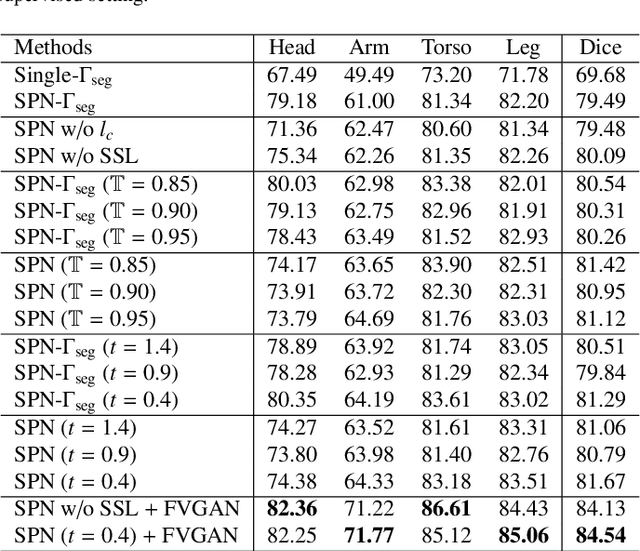
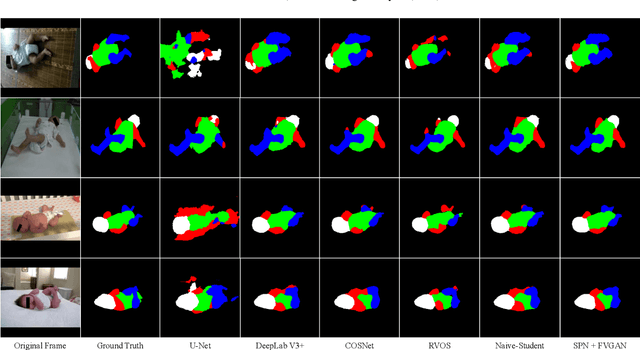
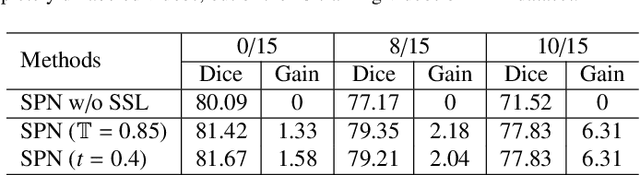
General movement assessment (GMA) of infant movement videos (IMVs) is an effective method for early detection of cerebral palsy (CP) in infants. We demonstrate in this paper that end-to-end trainable neural networks for image sequence recognition can be applied to achieve good results in GMA, and more importantly, augmenting raw video with infant body parsing and pose estimation information can significantly improve performance. To solve the problem of efficiently utilizing partially labeled IMVs for body parsing, we propose a semi-supervised model, termed SiamParseNet (SPN), which consists of two branches, one for intra-frame body parts segmentation and another for inter-frame label propagation. During training, the two branches are jointly trained by alternating between using input pairs of only labeled frames and input of both labeled and unlabeled frames. We also investigate training data augmentation by proposing a factorized video generative adversarial network (FVGAN) to synthesize novel labeled frames for training. When testing, we employ a multi-source inference mechanism, where the final result for a test frame is either obtained via the segmentation branch or via propagation from a nearby key frame. We conduct extensive experiments for body parsing using SPN on two infant movement video datasets, where SPN coupled with FVGAN achieves state-of-the-art performance. We further demonstrate that SPN can be easily adapted to the infant pose estimation task with superior performance. Last but not least, we explore the clinical application of our method for GMA. We collected a new clinical IMV dataset with GMA annotations, and our experiments show that SPN models for body parsing and pose estimation trained on the first two datasets generalize well to the new clinical dataset and their results can significantly boost the CRNN-based GMA prediction performance.
BoxTeacher: Exploring High-Quality Pseudo Labels for Weakly Supervised Instance Segmentation
Oct 11, 2022
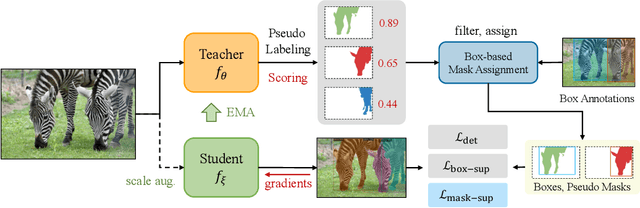
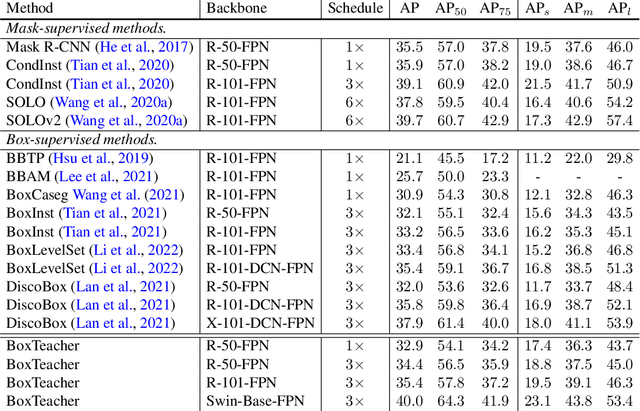
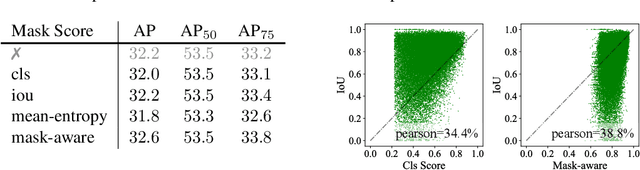
Labeling objects with pixel-wise segmentation requires a huge amount of human labor compared to bounding boxes. Most existing methods for weakly supervised instance segmentation focus on designing heuristic losses with priors from bounding boxes. While, we find that box-supervised methods can produce some fine segmentation masks and we wonder whether the detectors could learn from these fine masks while ignoring low-quality masks. To answer this question, we present BoxTeacher, an efficient and end-to-end training framework for high-performance weakly supervised instance segmentation, which leverages a sophisticated teacher to generate high-quality masks as pseudo labels. Considering the massive noisy masks hurt the training, we present a mask-aware confidence score to estimate the quality of pseudo masks, and propose the noise-aware pixel loss and noise-reduced affinity loss to adaptively optimize the student with pseudo masks. Extensive experiments can demonstrate effectiveness of the proposed BoxTeacher. Without bells and whistles, BoxTeacher remarkably achieves $34.4$ mask AP and $35.4$ mask AP with ResNet-50 and ResNet-101 respectively on the challenging MS-COCO dataset, which outperforms the previous state-of-the-art methods by a significant margin. The code and models are available at \url{https://github.com/hustvl/BoxTeacher}.
A Systematical Evaluation for Next-Basket Recommendation Algorithms
Sep 07, 2022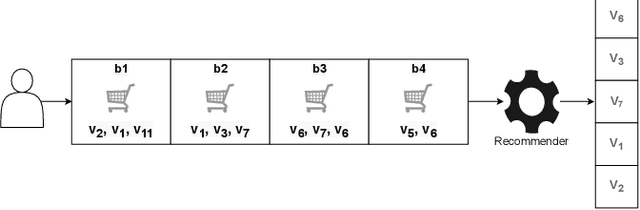
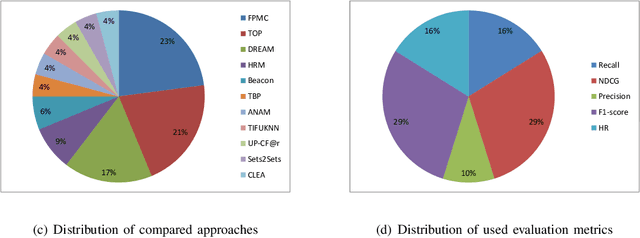
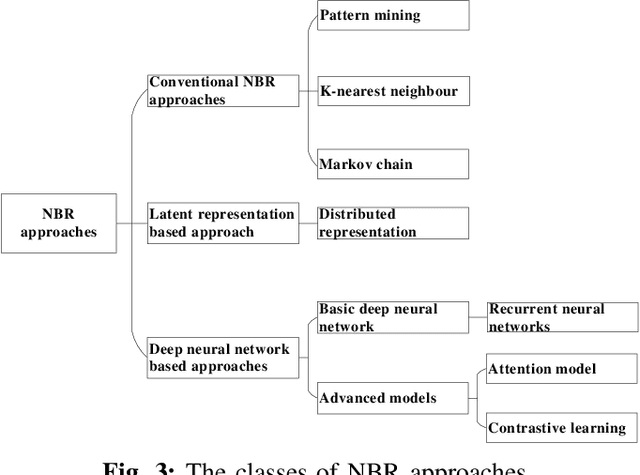
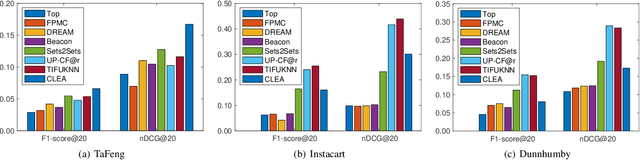
Next basket recommender systems (NBRs) aim to recommend a user's next (shopping) basket of items via modeling the user's preferences towards items based on the user's purchase history, usually a sequence of historical baskets. Due to its wide applicability in the real-world E-commerce industry, the studies NBR have attracted increasing attention in recent years. NBRs have been widely studied and much progress has been achieved in this area with a variety of NBR approaches having been proposed. However, an important issue is that there is a lack of a systematic and unified evaluation over the various NBR approaches. Different studies often evaluate NBR approaches on different datasets, under different experimental settings, making it hard to fairly and effectively compare the performance of different NBR approaches. To bridge this gap, in this work, we conduct a systematical empirical study in NBR area. Specifically, we review the representative work in NBR and analyze their cons and pros. Then, we run the selected NBR algorithms on the same datasets, under the same experimental setting and evaluate their performances using the same measurements. This provides a unified framework to fairly compare different NBR approaches. We hope this study can provide a valuable reference for the future research in this vibrant area.
ELMformer: Efficient Raw Image Restoration with a Locally Multiplicative Transformer
Aug 31, 2022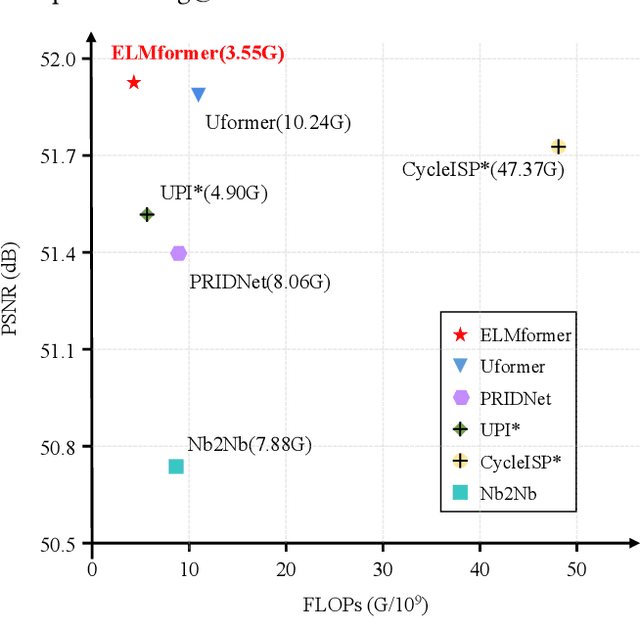
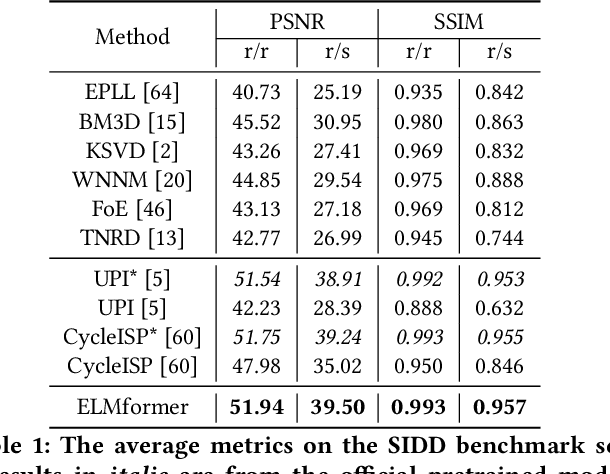
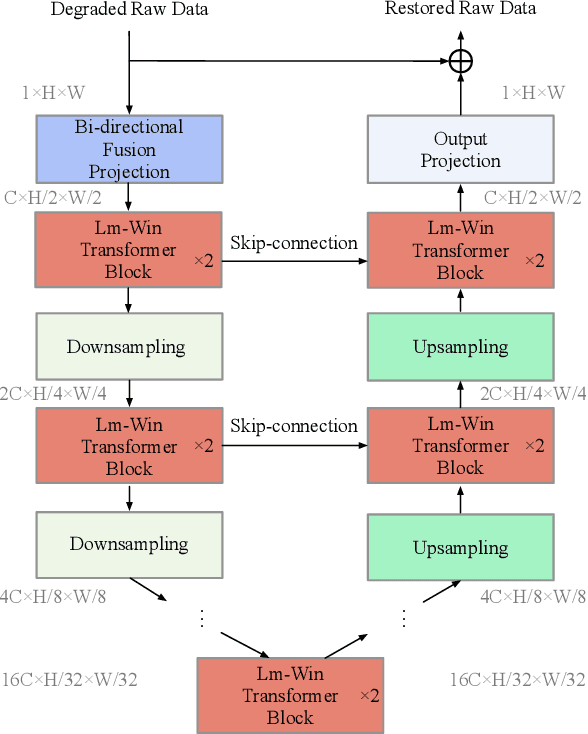
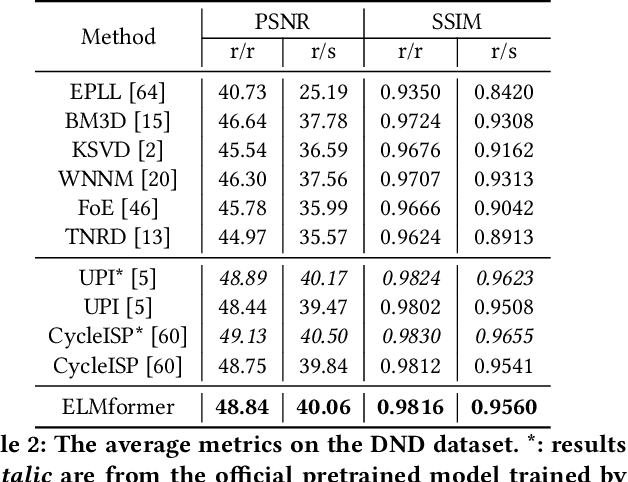
In order to get raw images of high quality for downstream Image Signal Process (ISP), in this paper we present an Efficient Locally Multiplicative Transformer called ELMformer for raw image restoration. ELMformer contains two core designs especially for raw images whose primitive attribute is single-channel. The first design is a Bi-directional Fusion Projection (BFP) module, where we consider both the color characteristics of raw images and spatial structure of single-channel. The second one is that we propose a Locally Multiplicative Self-Attention (L-MSA) scheme to effectively deliver information from the local space to relevant parts. ELMformer can efficiently reduce the computational consumption and perform well on raw image restoration tasks. Enhanced by these two core designs, ELMformer achieves the highest performance and keeps the lowest FLOPs on raw denoising and raw deblurring benchmarks compared with state-of-the-arts. Extensive experiments demonstrate the superiority and generalization ability of ELMformer. On SIDD benchmark, our method has even better denoising performance than ISP-based methods which need huge amount of additional sRGB training images. The codes are release at https://github.com/leonmakise/ELMformer.
MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
Aug 30, 2022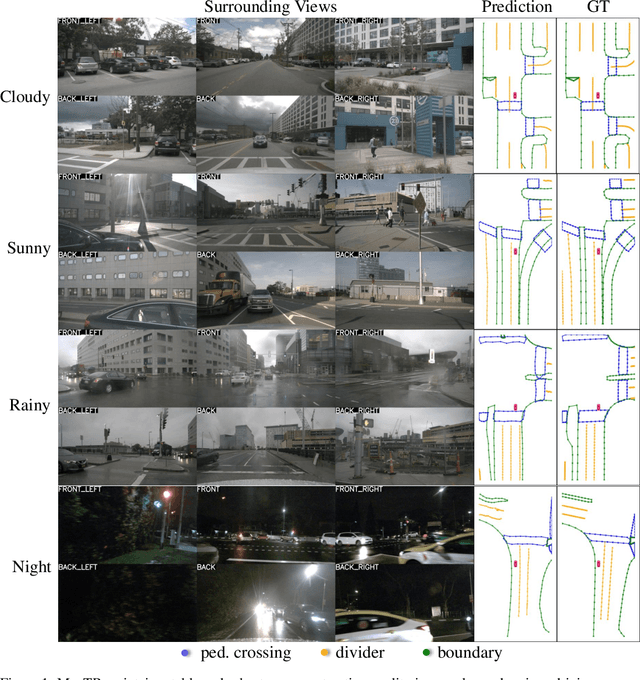
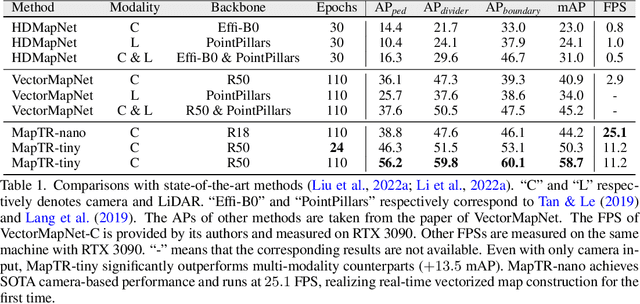
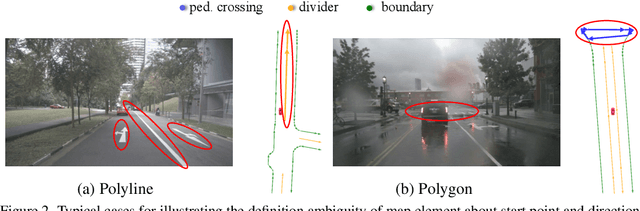

We present MapTR, a structured end-to-end framework for efficient online vectorized HD map construction. We propose a unified permutation-based modeling approach, i.e., modeling map element as a point set with a group of equivalent permutations, which avoids the definition ambiguity of map element and eases learning. We adopt a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. MapTR achieves the best performance and efficiency among existing vectorized map construction approaches on nuScenes dataset. In particular, MapTR-nano runs at real-time inference speed ($25.1$ FPS) on RTX 3090, $8\times$ faster than the existing state-of-the-art camera-based method while achieving $3.3$ higher mAP. MapTR-tiny significantly outperforms the existing state-of-the-art multi-modality method by $13.5$ mAP while being faster. Qualitative results show that MapTR maintains stable and robust map construction quality in complex and various driving scenes. Abundant demos are available at \url{https://github.com/hustvl/MapTR} to prove the effectiveness in real-world scenarios. MapTR is of great application value in autonomous driving. Code will be released for facilitating further research and application.
MixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022
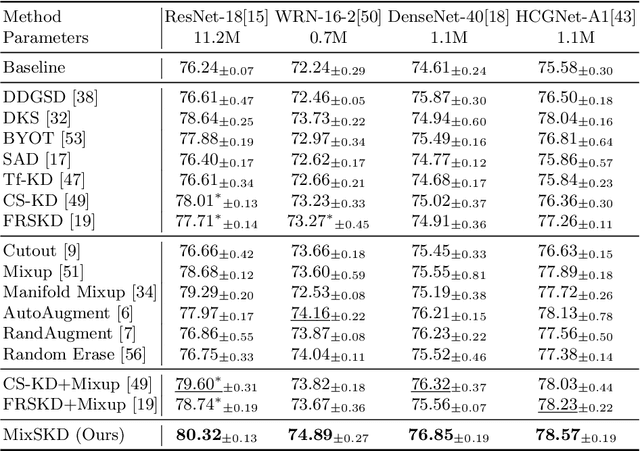
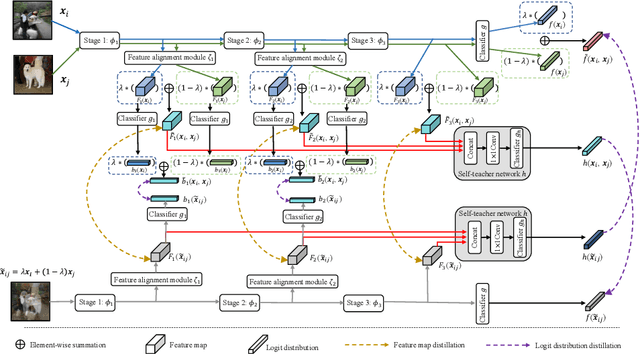
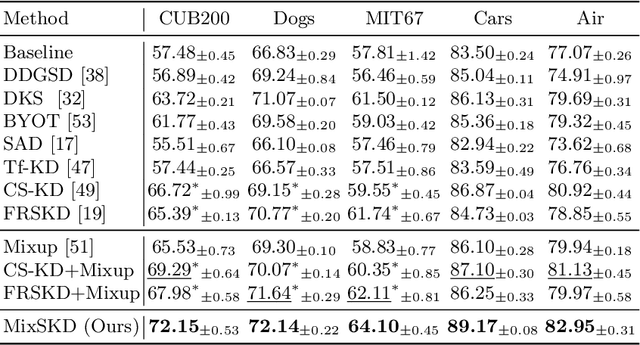
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation
Jul 18, 2022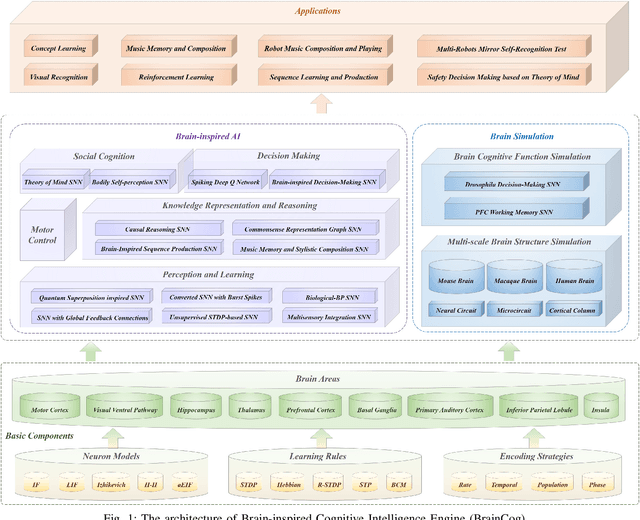
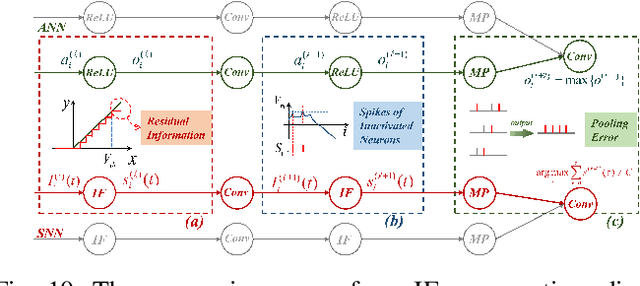
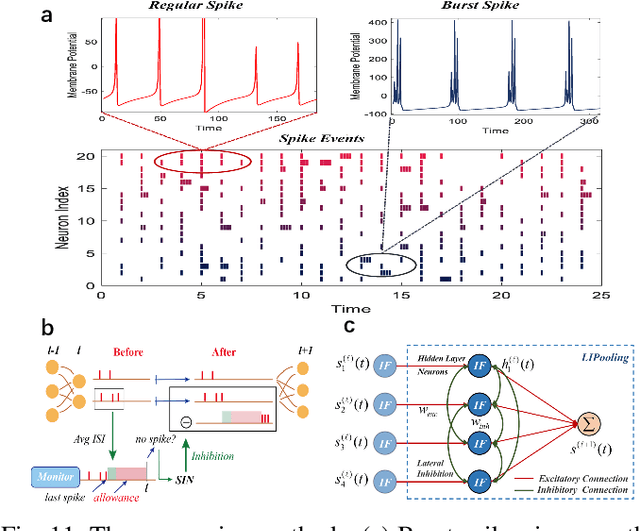
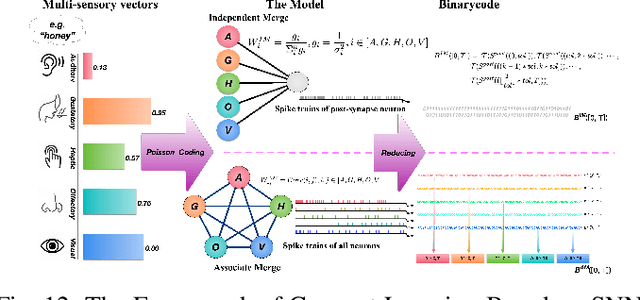
Spiking neural networks (SNNs) have attracted extensive attentions in Brain-inspired Artificial Intelligence and computational neuroscience. They can be used to simulate biological information processing in the brain at multiple scales. More importantly, SNNs serve as an appropriate level of abstraction to bring inspirations from brain and cognition to Artificial Intelligence. In this paper, we present the Brain-inspired Cognitive Intelligence Engine (BrainCog) for creating brain-inspired AI and brain simulation models. BrainCog incorporates different types of spiking neuron models, learning rules, brain areas, etc., as essential modules provided by the platform. Based on these easy-to-use modules, BrainCog supports various brain-inspired cognitive functions, including Perception and Learning, Decision Making, Knowledge Representation and Reasoning, Motor Control, and Social Cognition. These brain-inspired AI models have been effectively validated on various supervised, unsupervised, and reinforcement learning tasks, and they can be used to enable AI models to be with multiple brain-inspired cognitive functions. For brain simulation, BrainCog realizes the function simulation of decision-making, working memory, the structure simulation of the Neural Circuit, and whole brain structure simulation of Mouse brain, Macaque brain, and Human brain. An AI engine named BORN is developed based on BrainCog, and it demonstrates how the components of BrainCog can be integrated and used to build AI models and applications. To enable the scientific quest to decode the nature of biological intelligence and create AI, BrainCog aims to provide essential and easy-to-use building blocks, and infrastructural support to develop brain-inspired spiking neural network based AI, and to simulate the cognitive brains at multiple scales. The online repository of BrainCog can be found at https://github.com/braincog-x.