 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Synergizes with Memory: A Simple Approach for Anomaly Segmentation in Urban Scenes
Nov 24, 2021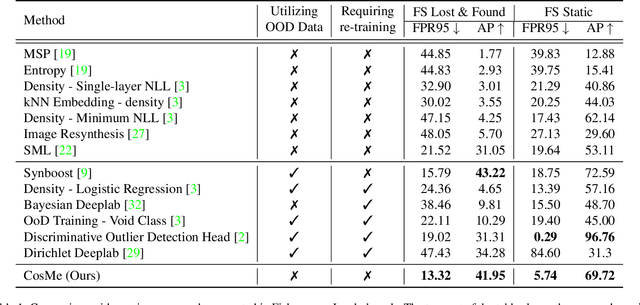
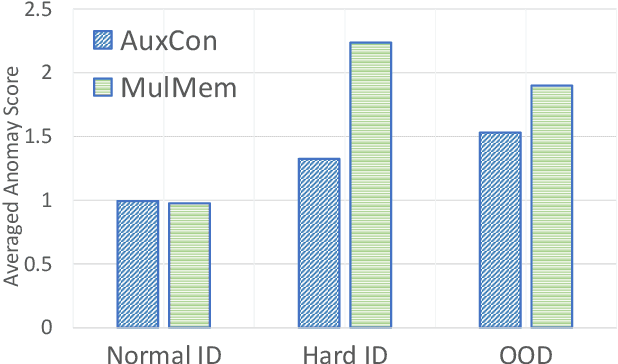
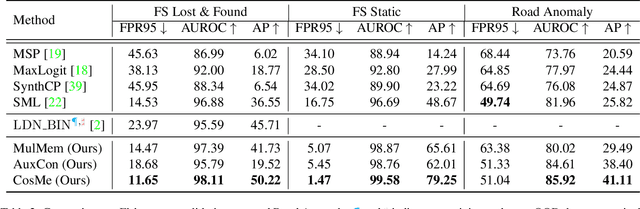
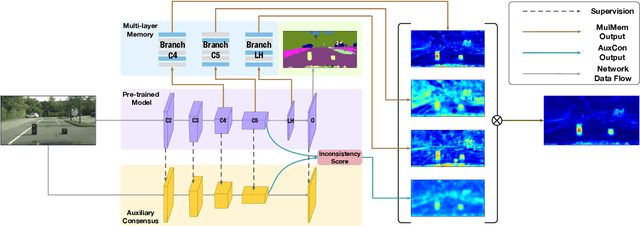
Anomaly segmentation is a crucial task for safety-critical applications, such as autonomous driving in urban scenes, where the goal is to detect out-of-distribution (OOD) objects with categories which are unseen during training. The core challenge of this task is how to distinguish hard in-distribution samples from OOD samples, which has not been explicitly discussed yet. In this paper, we propose a novel and simple approach named Consensus Synergizes with Memory (CosMe) to address this challenge, inspired by the psychology finding that groups perform better than individuals on memory tasks. The main idea is 1) building a memory bank which consists of seen prototypes extracted from multiple layers of the pre-trained segmentation model and 2) training an auxiliary model that mimics the behavior of the pre-trained model, and then measuring the consensus of their mid-level features as complementary cues that synergize with the memory bank. CosMe is good at distinguishing between hard in-distribution examples and OOD samples. Experimental results on several urban scene anomaly segmentation datasets show that CosMe outperforms previous approaches by large margins.
Self-Regulated Learning for Egocentric Video Activity Anticipation
Nov 23, 2021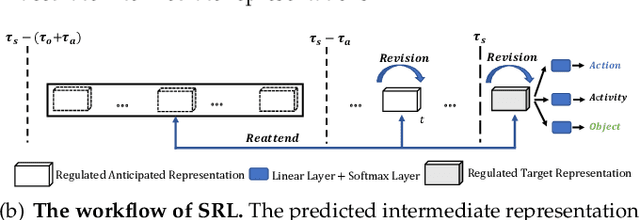
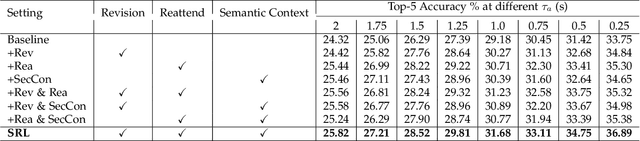
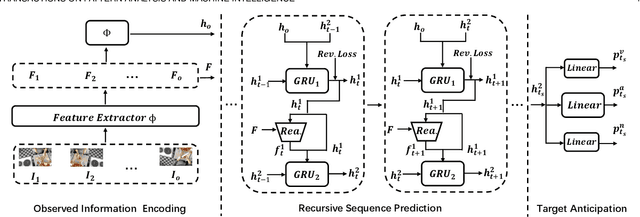
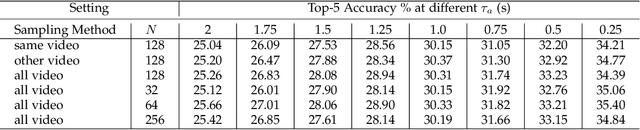
Future activity anticipation is a challenging problem in egocentric vision. As a standard future activity anticipation paradigm, recursive sequence prediction suffers from the accumulation of errors. To address this problem, we propose a simple and effective Self-Regulated Learning framework, which aims to regulate the intermediate representation consecutively to produce representation that (a) emphasizes the novel information in the frame of the current time-stamp in contrast to previously observed content, and (b) reflects its correlation with previously observed frames. The former is achieved by minimizing a contrastive loss, and the latter can be achieved by a dynamic reweighing mechanism to attend to informative frames in the observed content with a similarity comparison between feature of the current frame and observed frames. The learned final video representation can be further enhanced by multi-task learning which performs joint feature learning on the target activity labels and the automatically detected action and object class tokens. SRL sharply outperforms existing state-of-the-art in most cases on two egocentric video datasets and two third-person video datasets. Its effectiveness is also verified by the experimental fact that the action and object concepts that support the activity semantics can be accurately identified.
DVCFlow: Modeling Information Flow Towards Human-like Video Captioning
Nov 19, 2021
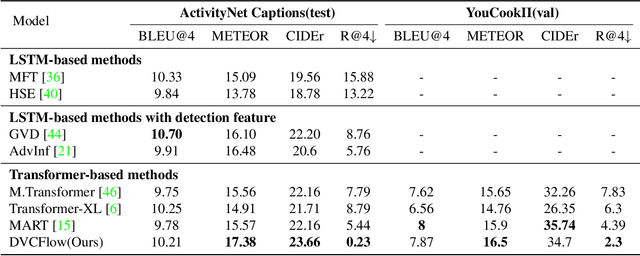
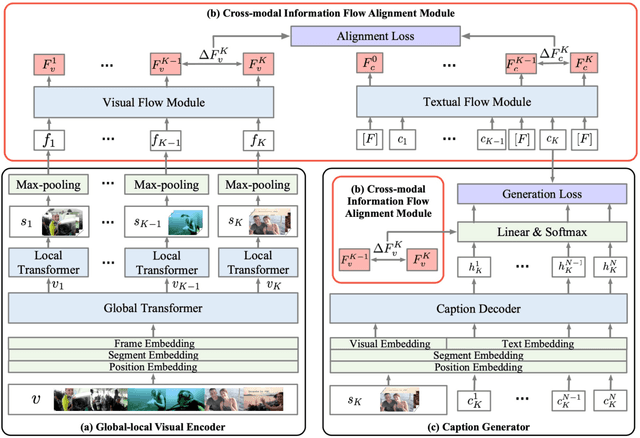
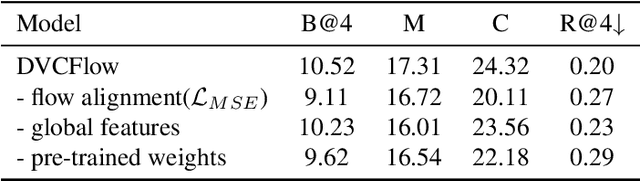
Dense video captioning (DVC) aims to generate multi-sentence descriptions to elucidate the multiple events in the video, which is challenging and demands visual consistency, discoursal coherence, and linguistic diversity. Existing methods mainly generate captions from individual video segments, lacking adaptation to the global visual context and progressive alignment between the fast-evolved visual content and textual descriptions, which results in redundant and spliced descriptions. In this paper, we introduce the concept of information flow to model the progressive information changing across video sequence and captions. By designing a Cross-modal Information Flow Alignment mechanism, the visual and textual information flows are captured and aligned, which endows the captioning process with richer context and dynamics on event/topic evolution. Based on the Cross-modal Information Flow Alignment module, we further put forward DVCFlow framework, which consists of a Global-local Visual Encoder to capture both global features and local features for each video segment, and a pre-trained Caption Generator to produce captions. Extensive experiments on the popular ActivityNet Captions and YouCookII datasets demonstrate that our method significantly outperforms competitive baselines, and generates more human-like text according to subject and objective tests.
DocScanner: Robust Document Image Rectification with Progressive Learning
Oct 28, 2021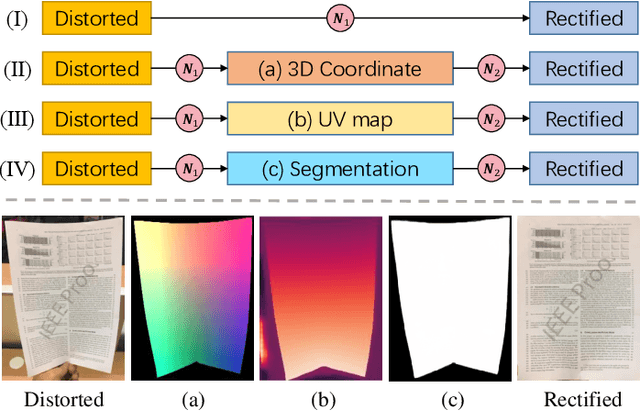

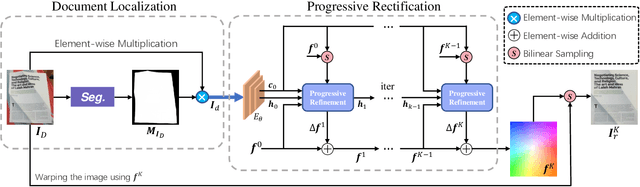
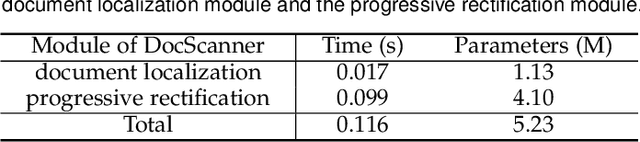
Compared to flatbed scanners, portable smartphones are much more convenient for physical documents digitizing. However, such digitized documents are often distorted due to uncontrolled physical deformations, camera positions, and illumination variations. To this end, this work presents DocScanner, a new deep network architecture for document image rectification. Different from existing methods, DocScanner addresses this issue by introducing a progressive learning mechanism. Specifically, DocScanner maintains a single estimate of the rectified image, which is progressively corrected with a recurrent architecture. The iterative refinements make DocScanner converge to a robust and superior performance, and the lightweight recurrent architecture ensures the running efficiency. In addition, before the above rectification process, observing the corrupted rectified boundaries existing in prior works, DocScanner exploits a document localization module to explicitly segment the foreground document from the cluttered background environments. To further improve the rectification quality, based on the geometric priori between the distorted and the rectified images, a geometric regularization is introduced during training to further facilitate the performance. Extensive experiments are conducted on the Doc3D dataset and the DocUNet benchmark dataset, and the quantitative and qualitative evaluation results verify the effectiveness of DocScanner, which outperforms previous methods on OCR accuracy, image similarity, and our proposed distortion metric by a considerable margin. Furthermore, our DocScanner shows the highest efficiency in inference time and parameter count.
CIPS-3D: A 3D-Aware Generator of GANs Based on Conditionally-Independent Pixel Synthesis
Oct 19, 2021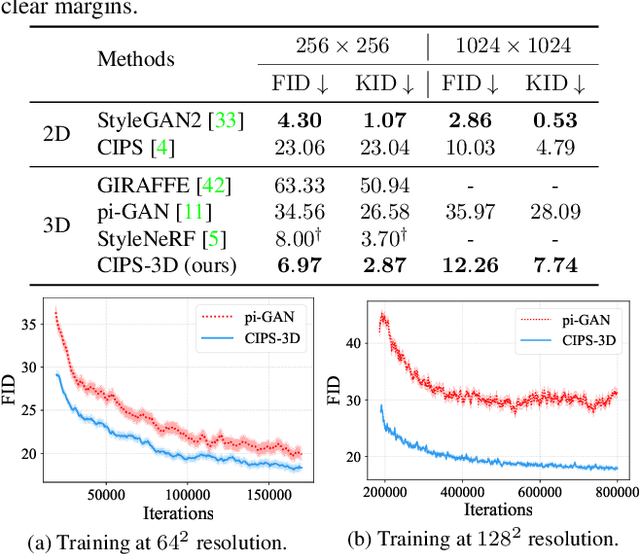
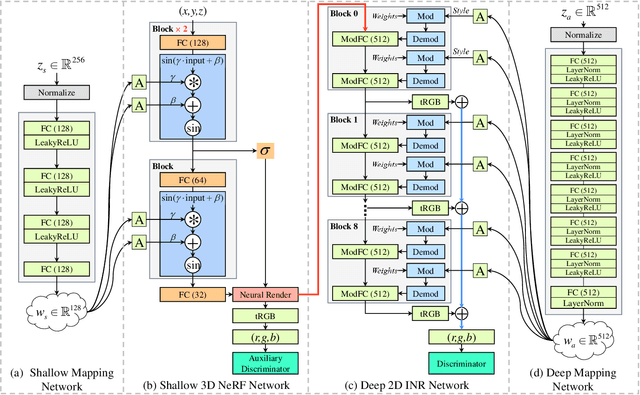

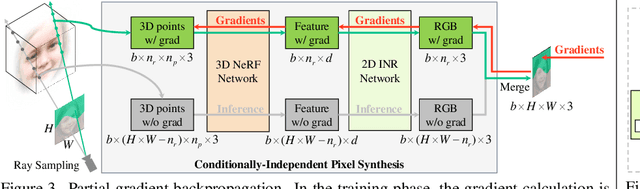
The style-based GAN (StyleGAN) architecture achieved state-of-the-art results for generating high-quality images, but it lacks explicit and precise control over camera poses. The recently proposed NeRF-based GANs made great progress towards 3D-aware generators, but they are unable to generate high-quality images yet. This paper presents CIPS-3D, a style-based, 3D-aware generator that is composed of a shallow NeRF network and a deep implicit neural representation (INR) network. The generator synthesizes each pixel value independently without any spatial convolution or upsampling operation. In addition, we diagnose the problem of mirror symmetry that implies a suboptimal solution and solve it by introducing an auxiliary discriminator. Trained on raw, single-view images, CIPS-3D sets new records for 3D-aware image synthesis with an impressive FID of 6.97 for images at the $256\times256$ resolution on FFHQ. We also demonstrate several interesting directions for CIPS-3D such as transfer learning and 3D-aware face stylization. The synthesis results are best viewed as videos, so we recommend the readers to check our github project at https://github.com/PeterouZh/CIPS-3D
Semi-Autoregressive Image Captioning
Oct 13, 2021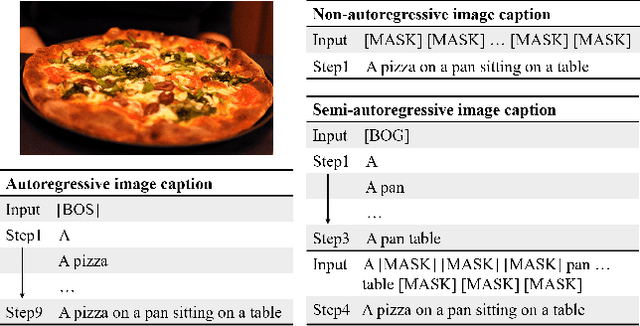
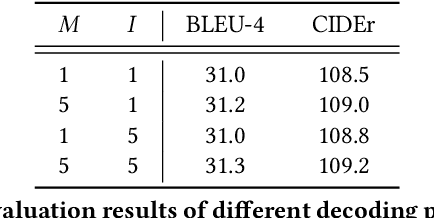
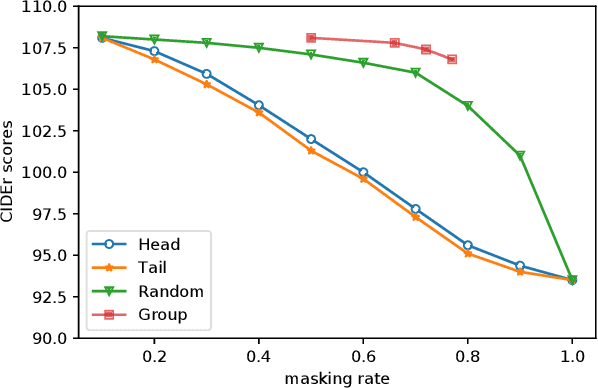
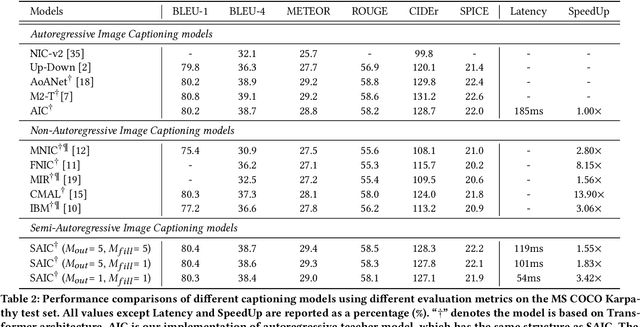
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e., generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup. Code is available at https://github.com/feizc/SAIC.
Differentiable Convolution Search for Point Cloud Processing
Aug 29, 2021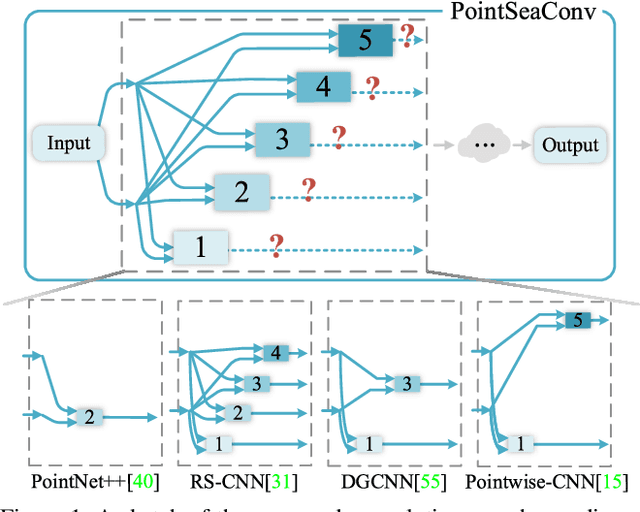

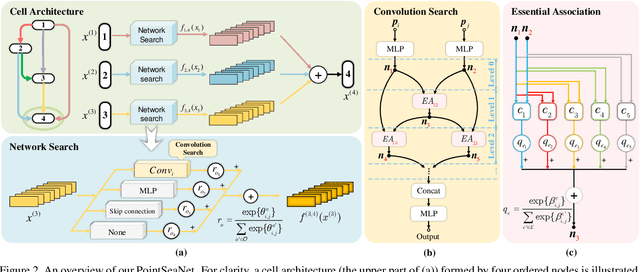

Exploiting convolutional neural networks for point cloud processing is quite challenging, due to the inherent irregular distribution and discrete shape representation of point clouds. To address these problems, many handcrafted convolution variants have sprung up in recent years. Though with elaborate design, these variants could be far from optimal in sufficiently capturing diverse shapes formed by discrete points. In this paper, we propose PointSeaConv, i.e., a novel differential convolution search paradigm on point clouds. It can work in a purely data-driven manner and thus is capable of auto-creating a group of suitable convolutions for geometric shape modeling. We also propose a joint optimization framework for simultaneous search of internal convolution and external architecture, and introduce epsilon-greedy algorithm to alleviate the effect of discretization error. As a result, PointSeaNet, a deep network that is sufficient to capture geometric shapes at both convolution level and architecture level, can be searched out for point cloud processing. Extensive experiments strongly evidence that our proposed PointSeaNet surpasses current handcrafted deep models on challenging benchmarks across multiple tasks with remarkable margins.
Multiscale Spatio-Temporal Graph Neural Networks for 3D Skeleton-Based Motion Prediction
Aug 25, 2021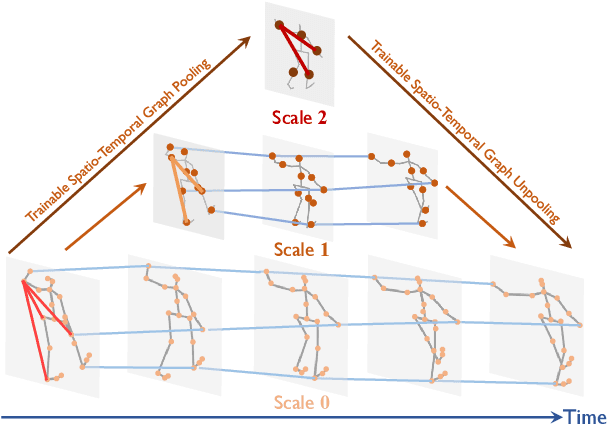
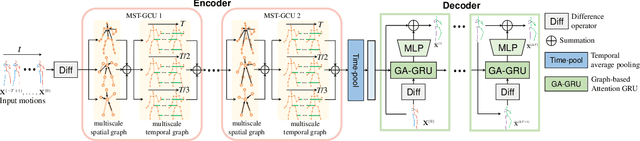
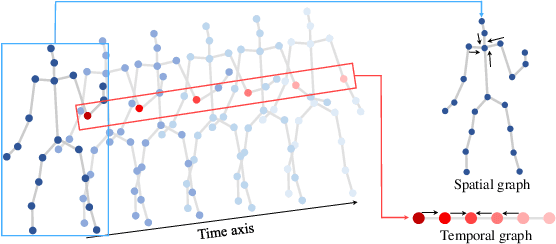
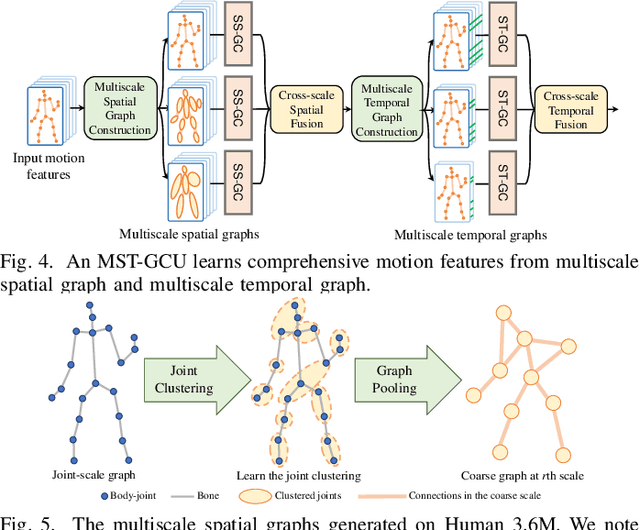
We propose a multiscale spatio-temporal graph neural network (MST-GNN) to predict the future 3D skeleton-based human poses in an action-category-agnostic manner. The core of MST-GNN is a multiscale spatio-temporal graph that explicitly models the relations in motions at various spatial and temporal scales. Different from many previous hierarchical structures, our multiscale spatio-temporal graph is built in a data-adaptive fashion, which captures nonphysical, yet motion-based relations. The key module of MST-GNN is a multiscale spatio-temporal graph computational unit (MST-GCU) based on the trainable graph structure. MST-GCU embeds underlying features at individual scales and then fuses features across scales to obtain a comprehensive representation. The overall architecture of MST-GNN follows an encoder-decoder framework, where the encoder consists of a sequence of MST-GCUs to learn the spatial and temporal features of motions, and the decoder uses a graph-based attention gate recurrent unit (GA-GRU) to generate future poses. Extensive experiments are conducted to show that the proposed MST-GNN outperforms state-of-the-art methods in both short and long-term motion prediction on the datasets of Human 3.6M, CMU Mocap and 3DPW, where MST-GNN outperforms previous works by 5.33% and 3.67% of mean angle errors in average for short-term and long-term prediction on Human 3.6M, and by 11.84% and 4.71% of mean angle errors for short-term and long-term prediction on CMU Mocap, and by 1.13% of mean angle errors on 3DPW in average, respectively. We further investigate the learned multiscale graphs for interpretability.
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021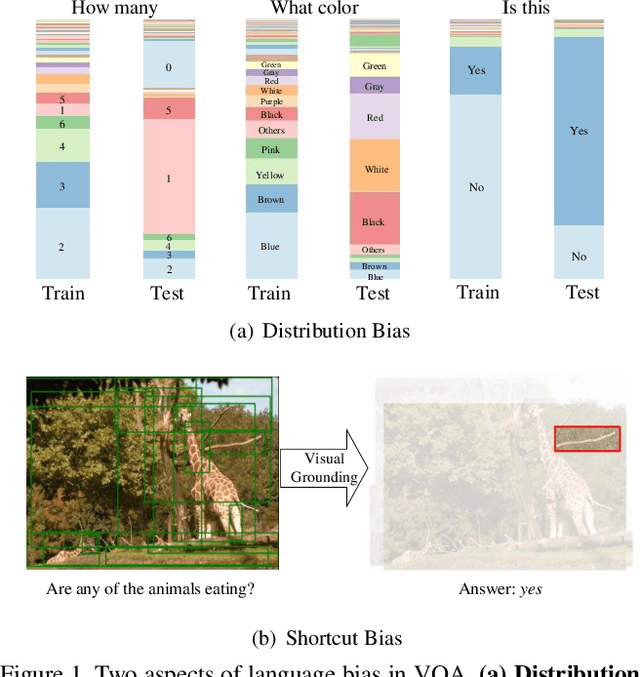
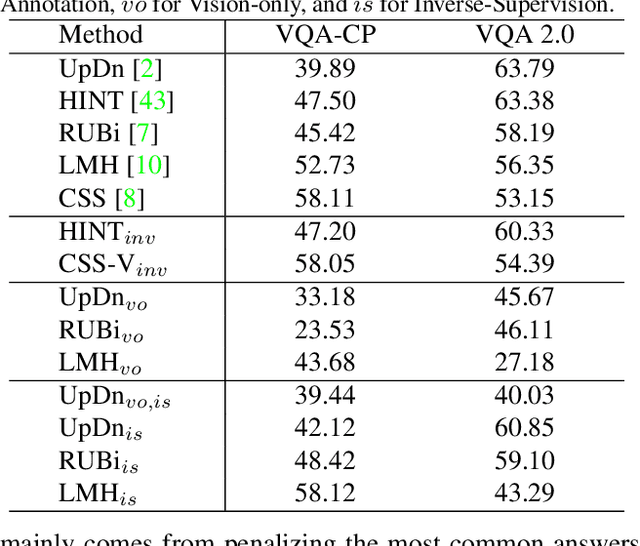
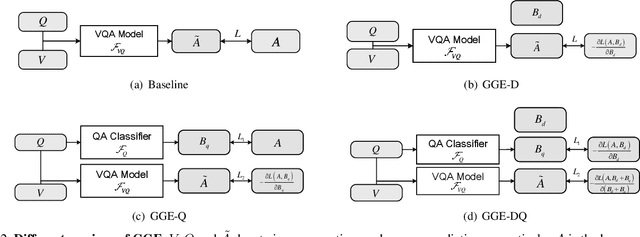
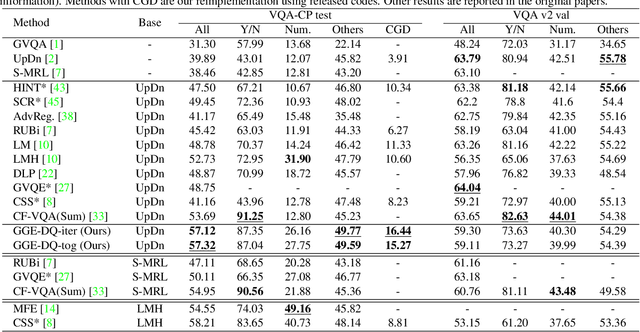
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
Pixel Difference Networks for Efficient Edge Detection
Aug 16, 2021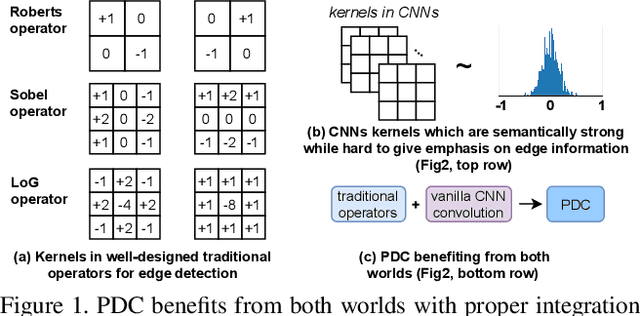
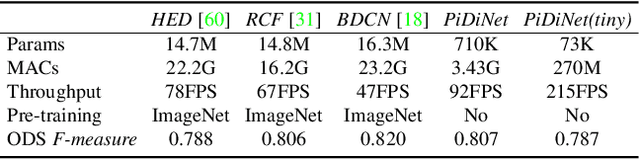
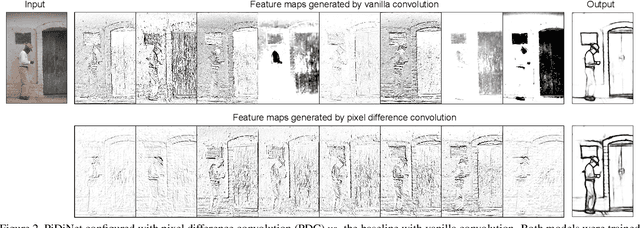
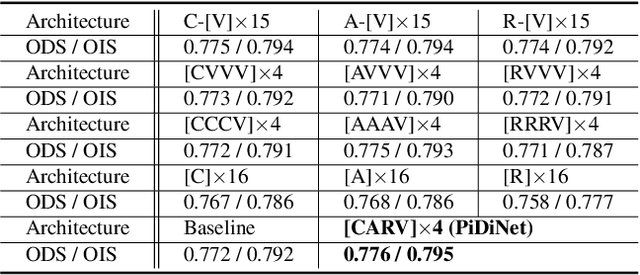
Recently, deep Convolutional Neural Networks (CNNs) can achieve human-level performance in edge detection with the rich and abstract edge representation capacities. However, the high performance of CNN based edge detection is achieved with a large pretrained CNN backbone, which is memory and energy consuming. In addition, it is surprising that the previous wisdom from the traditional edge detectors, such as Canny, Sobel, and LBP are rarely investigated in the rapid-developing deep learning era. To address these issues, we propose a simple, lightweight yet effective architecture named Pixel Difference Network (PiDiNet) for efficient edge detection. Extensive experiments on BSDS500, NYUD, and Multicue are provided to demonstrate its effectiveness, and its high training and inference efficiency. Surprisingly, when training from scratch with only the BSDS500 and VOC datasets, PiDiNet can surpass the recorded result of human perception (0.807 vs. 0.803 in ODS F-measure) on the BSDS500 dataset with 100 FPS and less than 1M parameters. A faster version of PiDiNet with less than 0.1M parameters can still achieve comparable performance among state of the arts with 200 FPS. Results on the NYUD and Multicue datasets show similar observations. The codes are available at https://github.com/zhuoinoulu/pidinet.