 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Speech Emotion Recognition With Multi-Gating Mechanism and Neural Architecture Search
Nov 16, 2022



Speech emotion recognition (SER) classifies audio into emotion categories such as Happy, Angry, Fear, Disgust and Neutral. While Speech Emotion Recognition (SER) is a common application for popular languages, it continues to be a problem for low-resourced languages, i.e., languages with no pretrained speech-to-text recognition models. This paper firstly proposes a language-specific model that extract emotional information from multiple pre-trained speech models, and then designs a multi-domain model that simultaneously performs SER for various languages. Our multidomain model employs a multi-gating mechanism to generate unique weighted feature combination for each language, and also searches for specific neural network structure for each language through a neural architecture search module. In addition, we introduce a contrastive auxiliary loss to build more separable representations for audio data. Our experiments show that our model raises the state-of-the-art accuracy by 3% for German and 14.3% for French.
Provable Adaptivity in Adam
Aug 21, 2022


Adaptive Moment Estimation (Adam) optimizer is widely used in deep learning tasks because of its fast convergence properties. However, the convergence of Adam is still not well understood. In particular, the existing analysis of Adam cannot clearly demonstrate the advantage of Adam over SGD. We attribute this theoretical embarrassment to $L$-smooth condition (i.e., assuming the gradient is globally Lipschitz continuous with constant $L$) adopted by literature, which has been pointed out to often fail in practical neural networks. To tackle this embarrassment, we analyze the convergence of Adam under a relaxed condition called $(L_0,L_1)$ smoothness condition, which allows the gradient Lipschitz constant to change with the local gradient norm. $(L_0,L_1)$ is strictly weaker than $L$-smooth condition and it has been empirically verified to hold for practical deep neural networks. Under the $(L_0,L_1)$ smoothness condition, we establish the convergence for Adam with practical hyperparameters. Specifically, we argue that Adam can adapt to the local smoothness condition, justifying the \emph{adaptivity} of Adam. In contrast, SGD can be arbitrarily slow under this condition. Our result might shed light on the benefit of adaptive gradient methods over non-adaptive ones.
Deep Random Vortex Method for Simulation and Inference of Navier-Stokes Equations
Jun 20, 2022
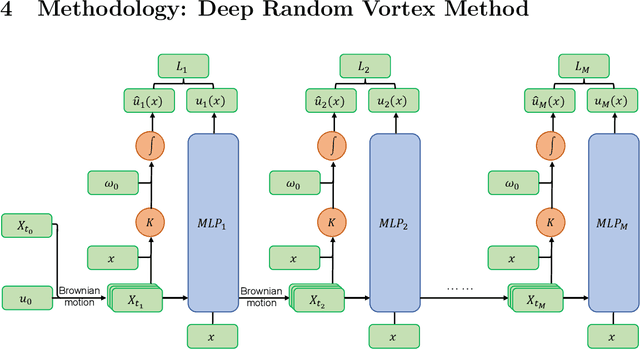
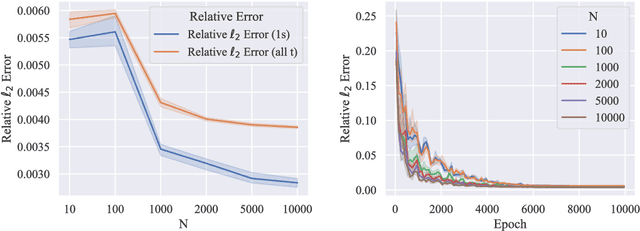
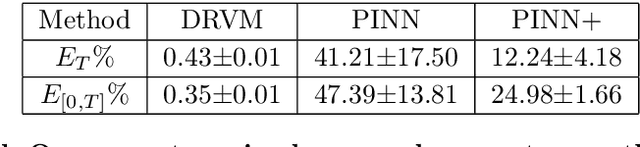
Navier-Stokes equations are significant partial differential equations that describe the motion of fluids such as liquids and air. Due to the importance of Navier-Stokes equations, the development on efficient numerical schemes is important for both science and engineer. Recently, with the development of AI techniques, several approaches have been designed to integrate deep neural networks in simulating and inferring the fluid dynamics governed by incompressible Navier-Stokes equations, which can accelerate the simulation or inferring process in a mesh-free and differentiable way. In this paper, we point out that the capability of existing deep Navier-Stokes informed methods is limited to handle non-smooth or fractional equations, which are two critical situations in reality. To this end, we propose the \emph{Deep Random Vortex Method} (DRVM), which combines the neural network with a random vortex dynamics system equivalent to the Navier-Stokes equation. Specifically, the random vortex dynamics motivates a Monte Carlo based loss function for training the neural network, which avoids the calculation of derivatives through auto-differentiation. Therefore, DRVM not only can efficiently solve Navier-Stokes equations involving rough path, non-differentiable initial conditions and fractional operators, but also inherits the mesh-free and differentiable benefits of the deep-learning-based solver. We conduct experiments on the Cauchy problem, parametric solver learning, and the inverse problem of both 2-d and 3-d incompressible Navier-Stokes equations. The proposed method achieves accurate results for simulation and inference of Navier-Stokes equations. Especially for the cases that include singular initial conditions, DRVM significantly outperforms existing PINN method.
Neural Operator with Regularity Structure for Modeling Dynamics Driven by SPDEs
Apr 14, 2022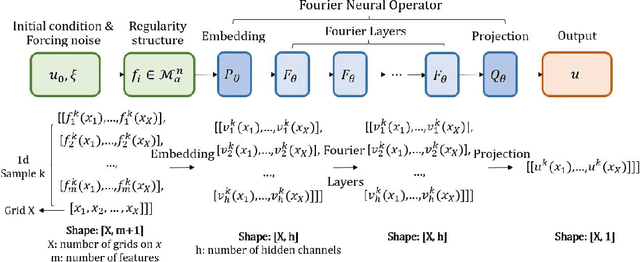

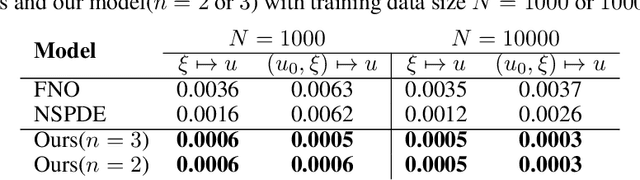
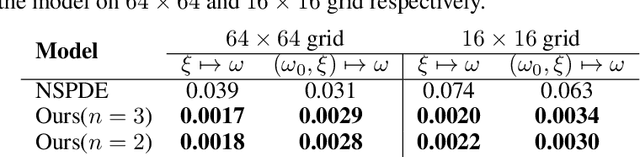
Stochastic partial differential equations (SPDEs) are significant tools for modeling dynamics in many areas including atmospheric sciences and physics. Neural Operators, generations of neural networks with capability of learning maps between infinite-dimensional spaces, are strong tools for solving parametric PDEs. However, they lack the ability to modeling SPDEs which usually have poor regularity due to the driving noise. As the theory of regularity structure has achieved great successes in analyzing SPDEs and provides the concept model feature vectors that well-approximate SPDEs' solutions, we propose the Neural Operator with Regularity Structure (NORS) which incorporates the feature vectors for modeling dynamics driven by SPDEs. We conduct experiments on various of SPDEs including the dynamic Phi41 model and the 2d stochastic Navier-Stokes equation, and the results demonstrate that the NORS is resolution-invariant, efficient, and achieves one order of magnitude lower error with a modest amount of data.
Optimizing Information-theoretical Generalization Bounds via Anisotropic Noise in SGLD
Nov 03, 2021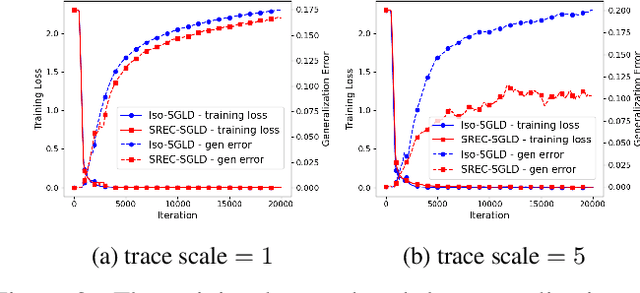
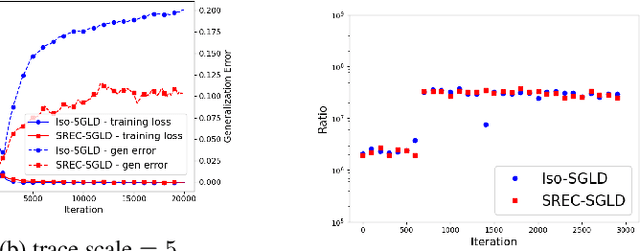
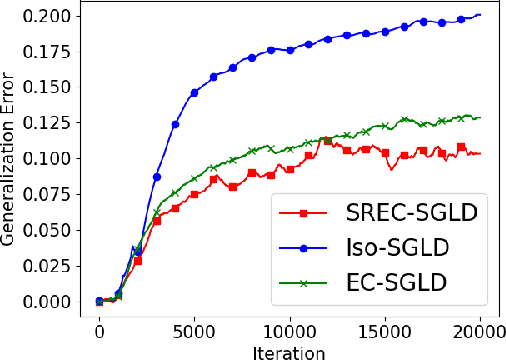
Recently, the information-theoretical framework has been proven to be able to obtain non-vacuous generalization bounds for large models trained by Stochastic Gradient Langevin Dynamics (SGLD) with isotropic noise. In this paper, we optimize the information-theoretical generalization bound by manipulating the noise structure in SGLD. We prove that with constraint to guarantee low empirical risk, the optimal noise covariance is the square root of the expected gradient covariance if both the prior and the posterior are jointly optimized. This validates that the optimal noise is quite close to the empirical gradient covariance. Technically, we develop a new information-theoretical bound that enables such an optimization analysis. We then apply matrix analysis to derive the form of optimal noise covariance. Presented constraint and results are validated by the empirical observations.
Equivariant vector field network for many-body system modeling
Oct 26, 2021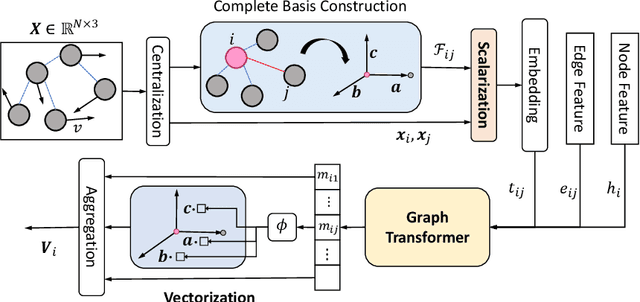
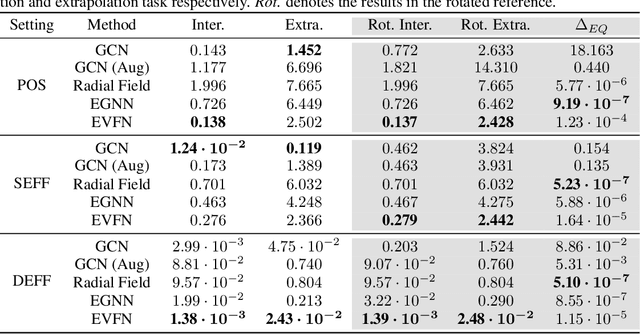
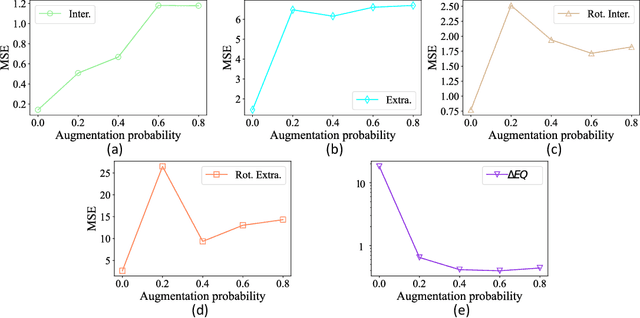
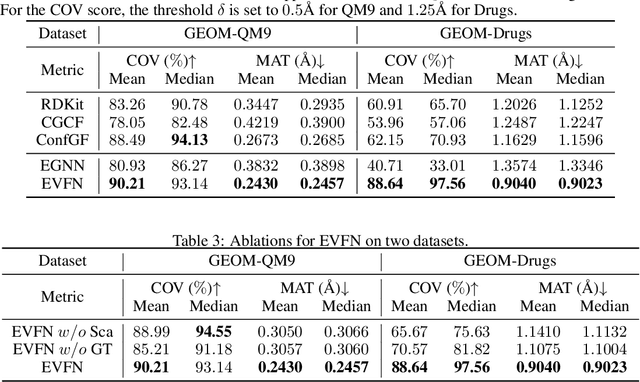
Modeling many-body systems has been a long-standing challenge in science, from classical and quantum physics to computational biology. Equivariance is a critical physical symmetry for many-body dynamic systems, which enables robust and accurate prediction under arbitrary reference transformations. In light of this, great efforts have been put on encoding this symmetry into deep neural networks, which significantly boosts the prediction performance of down-streaming tasks. Some general equivariant models which are computationally efficient have been proposed, however, these models have no guarantee on the approximation power and may have information loss. In this paper, we leverage insights from the scalarization technique in differential geometry to model many-body systems by learning the gradient vector fields, which are SE(3) and permutation equivariant. Specifically, we propose the Equivariant Vector Field Network (EVFN), which is built on a novel tuple of equivariant basis and the associated scalarization and vectorization layers. Since our tuple equivariant basis forms a complete basis, learning the dynamics with our EVFN has no information loss and no tensor operations are involved before the final vectorization, which reduces the complex optimization on tensors to a minimum. We evaluate our method on predicting trajectories of simulated Newton mechanics systems with both full and partially observed data, as well as the equilibrium state of small molecules (molecular conformation) evolving as a statistical mechanics system. Experimental results across multiple tasks demonstrate that our model achieves best or competitive performance on baseline models in various types of datasets.
Momentum Doesn't Change the Implicit Bias
Oct 08, 2021
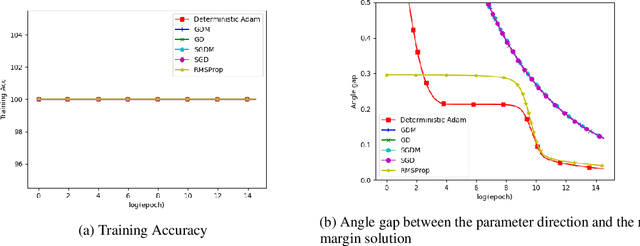
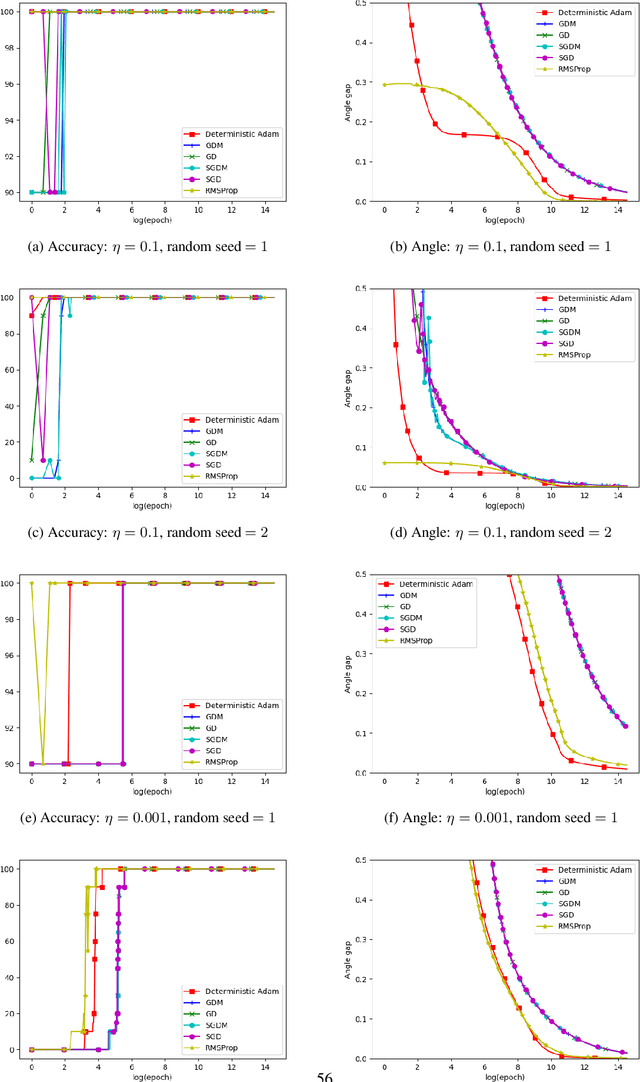
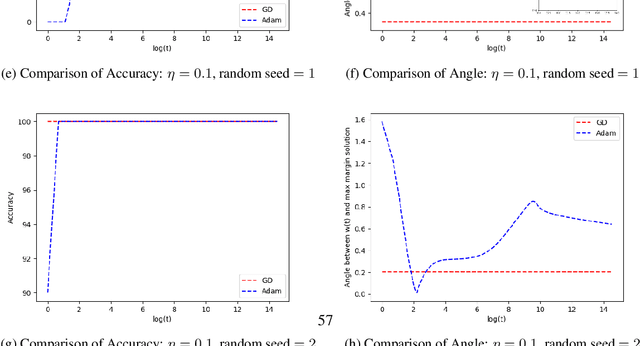
The momentum acceleration technique is widely adopted in many optimization algorithms. However, the theoretical understanding of how the momentum affects the generalization performance of the optimization algorithms is still unknown. In this paper, we answer this question through analyzing the implicit bias of momentum-based optimization. We prove that both SGD with momentum and Adam converge to the $L_2$ max-margin solution for exponential-tailed loss, which is the same as vanilla gradient descent. That means, these optimizers with momentum acceleration still converge to a model with low complexity, which provides guarantees on their generalization. Technically, to overcome the difficulty brought by the error accumulation in analyzing the momentum, we construct new Lyapunov functions as a tool to analyze the gap between the model parameter and the max-margin solution.
R-Drop: Regularized Dropout for Neural Networks
Jun 28, 2021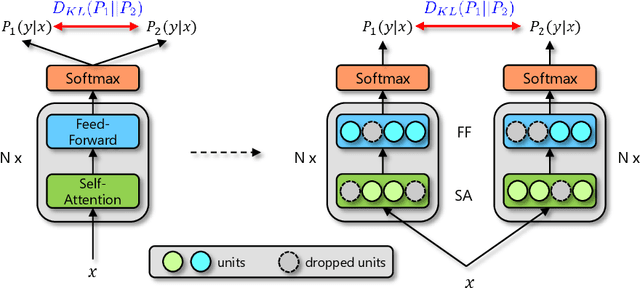

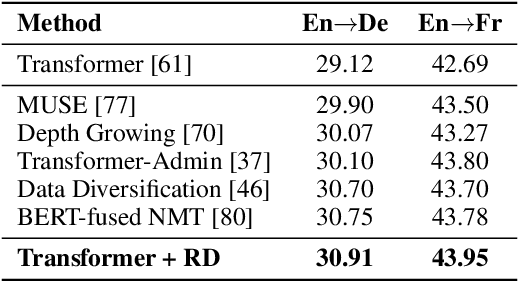
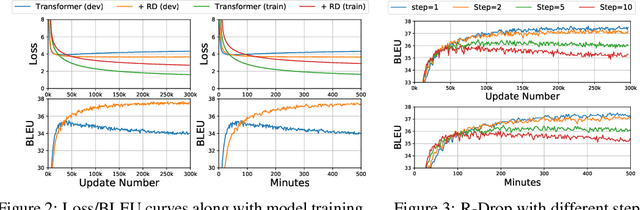
Dropout is a powerful and widely used technique to regularize the training of deep neural networks. In this paper, we introduce a simple regularization strategy upon dropout in model training, namely R-Drop, which forces the output distributions of different sub models generated by dropout to be consistent with each other. Specifically, for each training sample, R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by dropout. Theoretical analysis reveals that R-Drop reduces the freedom of the model parameters and complements dropout. Experiments on $\bf{5}$ widely used deep learning tasks ($\bf{18}$ datasets in total), including neural machine translation, abstractive summarization, language understanding, language modeling, and image classification, show that R-Drop is universally effective. In particular, it yields substantial improvements when applied to fine-tune large-scale pre-trained models, e.g., ViT, RoBERTa-large, and BART, and achieves state-of-the-art (SOTA) performances with the vanilla Transformer model on WMT14 English$\to$German translation ($\bf{30.91}$ BLEU) and WMT14 English$\to$French translation ($\bf{43.95}$ BLEU), even surpassing models trained with extra large-scale data and expert-designed advanced variants of Transformer models. Our code is available at GitHub{\url{https://github.com/dropreg/R-Drop}}.
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Driven Adaptive Prior
Jun 11, 2021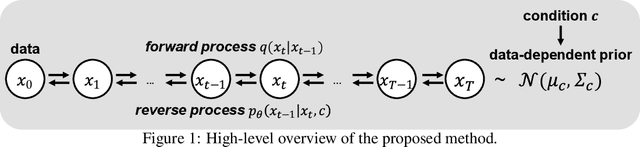
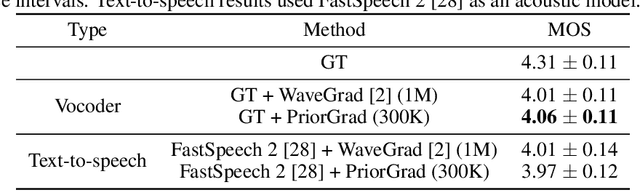


Denoising diffusion probabilistic models have been recently proposed to generate high-quality samples by estimating the gradient of the data density. The framework assumes the prior noise as a standard Gaussian distribution, whereas the corresponding data distribution may be more complicated than the standard Gaussian distribution, which potentially introduces inefficiency in denoising the prior noise into the data sample because of the discrepancy between the data and the prior. In this paper, we propose PriorGrad to improve the efficiency of the conditional diffusion model (for example, a vocoder using a mel-spectrogram as the condition) by applying an adaptive prior derived from the data statistics based on the conditional information. We formulate the training and sampling procedures of PriorGrad and demonstrate the advantages of an adaptive prior through a theoretical analysis. Focusing on the audio domain, we consider the recently proposed diffusion-based audio generative models based on both the spectral and time domains and show that PriorGrad achieves a faster convergence leading to data and parameter efficiency and improved quality, and thereby demonstrating the efficiency of a data-driven adaptive prior.
Incorporating NODE with Pre-trained Neural Differential Operator for Learning Dynamics
Jun 09, 2021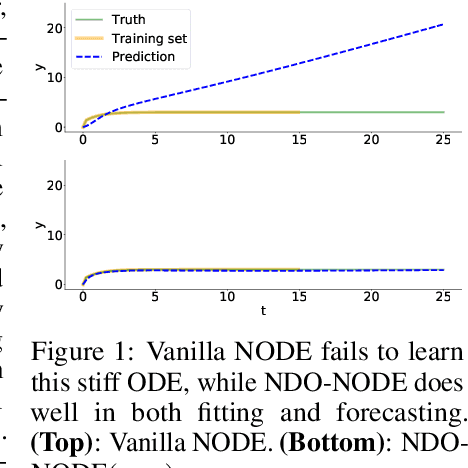
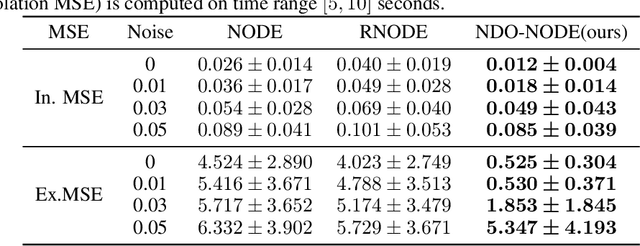
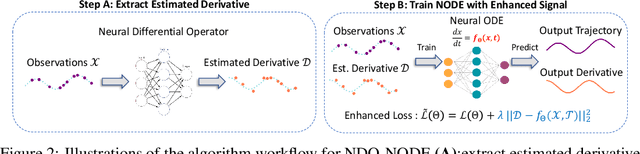
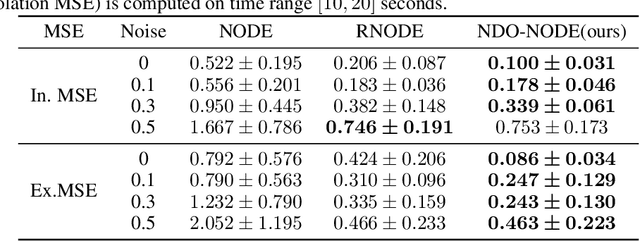
Learning dynamics governed by differential equations is crucial for predicting and controlling the systems in science and engineering. Neural Ordinary Differential Equation (NODE), a deep learning model integrated with differential equations, learns the dynamics directly from the samples on the trajectory and shows great promise in the scientific field. However, the training of NODE highly depends on the numerical solver, which can amplify numerical noise and be unstable, especially for ill-conditioned dynamical systems. In this paper, to reduce the reliance on the numerical solver, we propose to enhance the supervised signal in learning dynamics. Specifically, beyond learning directly from the trajectory samples, we pre-train a neural differential operator (NDO) to output an estimation of the derivatives to serve as an additional supervised signal. The NDO is pre-trained on a class of symbolic functions, and it learns the mapping between the trajectory samples of these functions to their derivatives. We provide theoretical guarantee on that the output of NDO can well approximate the ground truth derivatives by proper tuning the complexity of the library. To leverage both the trajectory signal and the estimated derivatives from NDO, we propose an algorithm called NDO-NODE, in which the loss function contains two terms: the fitness on the true trajectory samples and the fitness on the estimated derivatives that are output by the pre-trained NDO. Experiments on various of dynamics show that our proposed NDO-NODE can consistently improve the forecasting accuracy.