 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGAL: Transfer Learning For Fast Optimization of Computation Graphs
May 30, 2019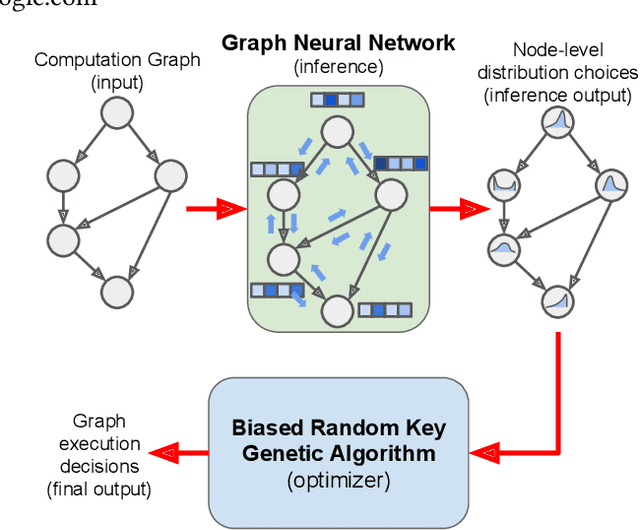
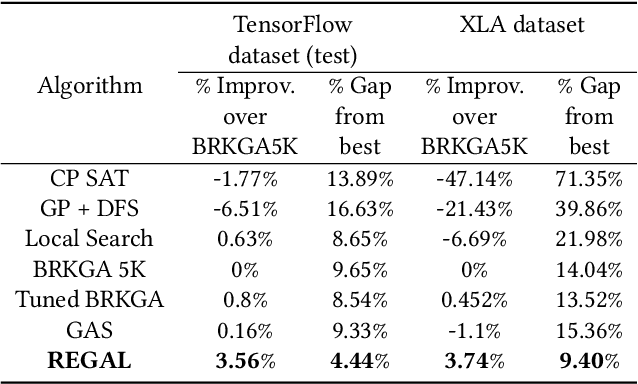
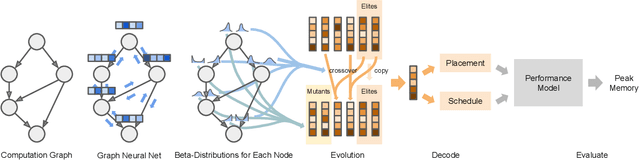
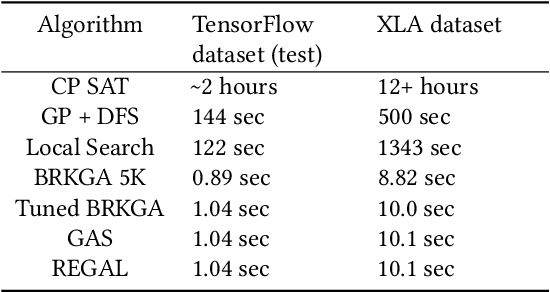
We present a deep reinforcement learning approach to optimizing the execution cost of computation graphs in a static compiler. The key idea is to combine a neural network policy with a genetic algorithm, the Biased Random-Key Genetic Algorithm (BRKGA). The policy is trained to predict, given an input graph to be optimized, the node-level probability distributions for sampling mutations and crossovers in BRKGA. Our approach, "REINFORCE-based Genetic Algorithm Learning" (REGAL), uses the policy's ability to transfer to new graphs to significantly improve the solution quality of the genetic algorithm for the same objective evaluation budget. As a concrete application, we show results for minimizing peak memory in TensorFlow graphs by jointly optimizing device placement and scheduling. REGAL achieves on average 3.56% lower peak memory than BRKGA on previously unseen graphs, outperforming all the algorithms we compare to, and giving 4.4x bigger improvement than the next best algorithm. We also evaluate REGAL on a production compiler team's performance benchmark of XLA graphs and achieve on average 3.74% lower peak memory than BRKGA, again outperforming all others. Our approach and analysis is made possible by collecting a dataset of 372 unique real-world TensorFlow graphs, more than an order of magnitude more data than previous work.
Structured agents for physical construction
May 13, 2019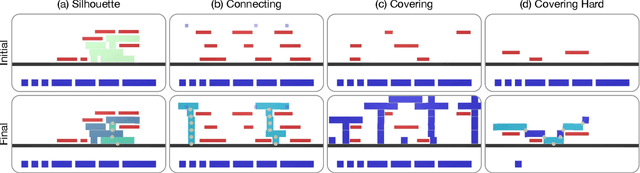
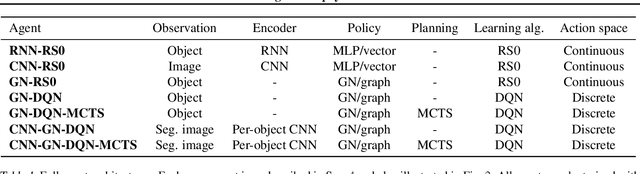
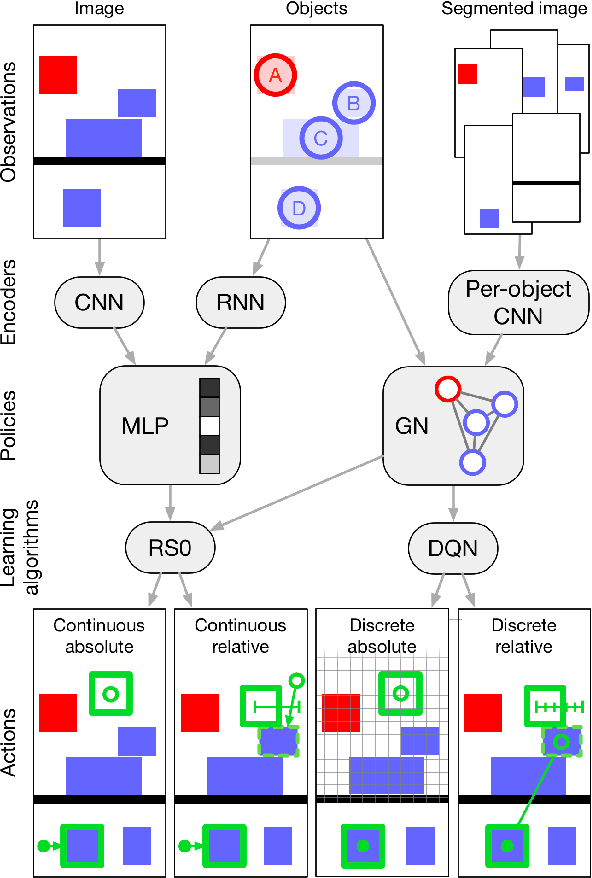
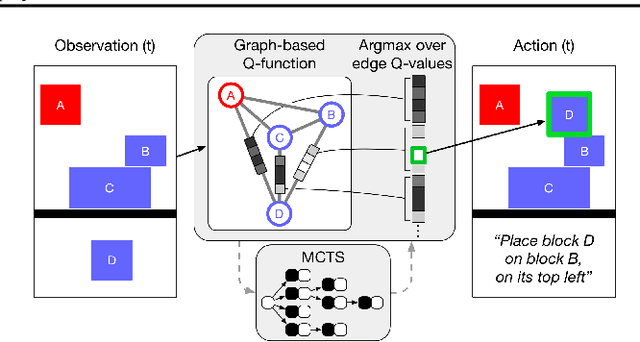
Physical construction---the ability to compose objects, subject to physical dynamics, to serve some function---is fundamental to human intelligence. We introduce a suite of challenging physical construction tasks inspired by how children play with blocks, such as matching a target configuration, stacking blocks to connect objects together, and creating shelter-like structures over target objects. We examine how a range of deep reinforcement learning agents fare on these challenges, and introduce several new approaches which provide superior performance. Our results show that agents which use structured representations (e.g., objects and scene graphs) and structured policies (e.g., object-centric actions) outperform those which use less structured representations, and generalize better beyond their training when asked to reason about larger scenes. Model-based agents which use Monte-Carlo Tree Search also outperform strictly model-free agents in our most challenging construction problems. We conclude that approaches which combine structured representations and reasoning with powerful learning are a key path toward agents that possess rich intuitive physics, scene understanding, and planning.
Graph Matching Networks for Learning the Similarity of Graph Structured Objects
May 12, 2019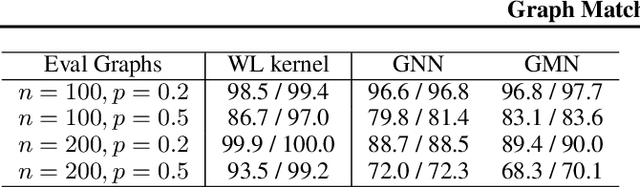
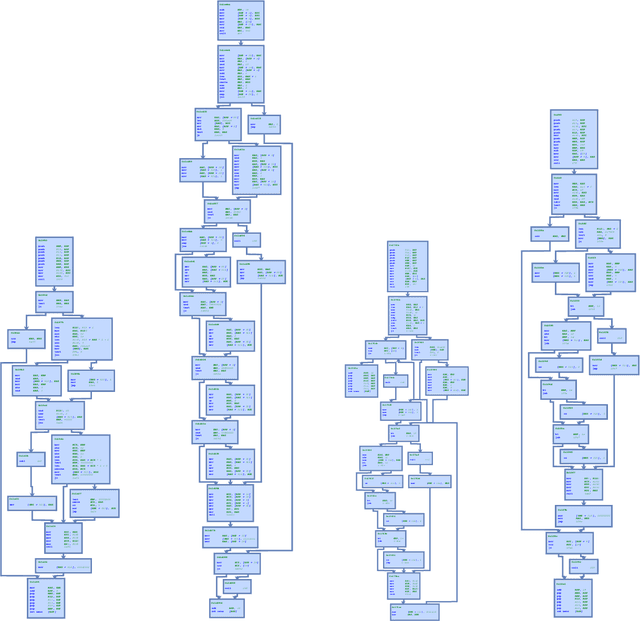
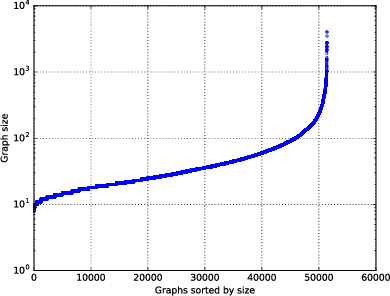
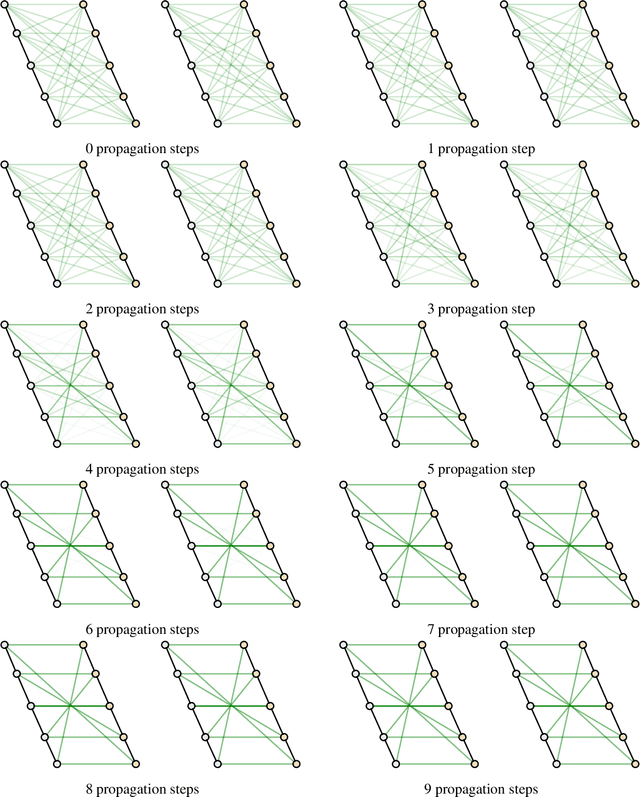
This paper addresses the challenging problem of retrieval and matching of graph structured objects, and makes two key contributions. First, we demonstrate how Graph Neural Networks (GNN), which have emerged as an effective model for various supervised prediction problems defined on structured data, can be trained to produce embedding of graphs in vector spaces that enables efficient similarity reasoning. Second, we propose a novel Graph Matching Network model that, given a pair of graphs as input, computes a similarity score between them by jointly reasoning on the pair through a new cross-graph attention-based matching mechanism. We demonstrate the effectiveness of our models on different domains including the challenging problem of control-flow-graph based function similarity search that plays an important role in the detection of vulnerabilities in software systems. The experimental analysis demonstrates that our models are not only able to exploit structure in the context of similarity learning but they can also outperform domain-specific baseline systems that have been carefully hand-engineered for these problems.
Knowing When to Stop: Evaluation and Verification of Conformity to Output-size Specifications
Apr 26, 2019
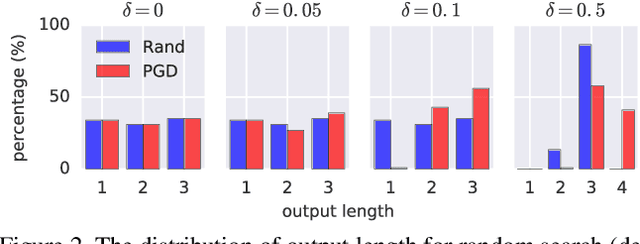
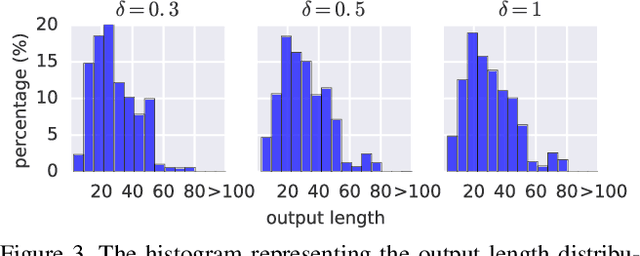
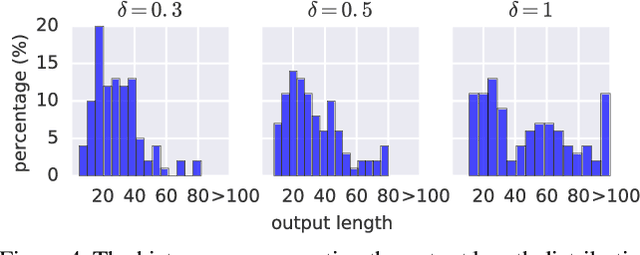
Models such as Sequence-to-Sequence and Image-to-Sequence are widely used in real world applications. While the ability of these neural architectures to produce variable-length outputs makes them extremely effective for problems like Machine Translation and Image Captioning, it also leaves them vulnerable to failures of the form where the model produces outputs of undesirable length. This behavior can have severe consequences such as usage of increased computation and induce faults in downstream modules that expect outputs of a certain length. Motivated by the need to have a better understanding of the failures of these models, this paper proposes and studies the novel output-size modulation problem and makes two key technical contributions. First, to evaluate model robustness, we develop an easy-to-compute differentiable proxy objective that can be used with gradient-based algorithms to find output-lengthening inputs. Second and more importantly, we develop a verification approach that can formally verify whether a network always produces outputs within a certain length. Experimental results on Machine Translation and Image Captioning show that our output-lengthening approach can produce outputs that are 50 times longer than the input, while our verification approach can, given a model and input domain, prove that the output length is below a certain size.
The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision
Apr 26, 2019
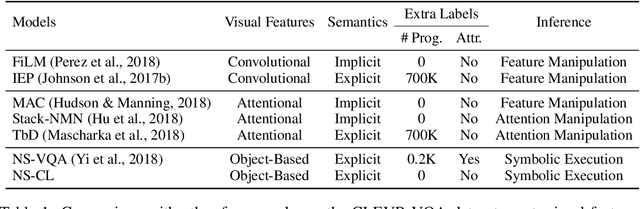

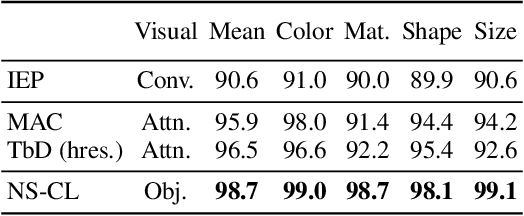
We propose the Neuro-Symbolic Concept Learner (NS-CL), a model that learns visual concepts, words, and semantic parsing of sentences without explicit supervision on any of them; instead, our model learns by simply looking at images and reading paired questions and answers. Our model builds an object-based scene representation and translates sentences into executable, symbolic programs. To bridge the learning of two modules, we use a neuro-symbolic reasoning module that executes these programs on the latent scene representation. Analogical to human concept learning, the perception module learns visual concepts based on the language description of the object being referred to. Meanwhile, the learned visual concepts facilitate learning new words and parsing new sentences. We use curriculum learning to guide the searching over the large compositional space of images and language. Extensive experiments demonstrate the accuracy and efficiency of our model on learning visual concepts, word representations, and semantic parsing of sentences. Further, our method allows easy generalization to new object attributes, compositions, language concepts, scenes and questions, and even new program domains. It also empowers applications including visual question answering and bidirectional image-text retrieval.
Analysing Mathematical Reasoning Abilities of Neural Models
Apr 02, 2019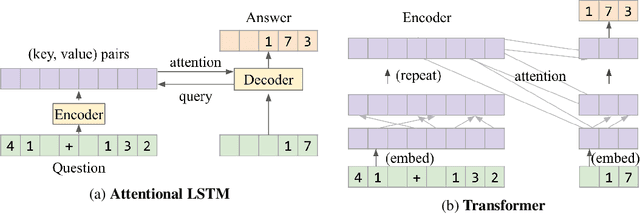
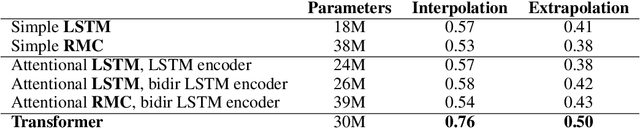
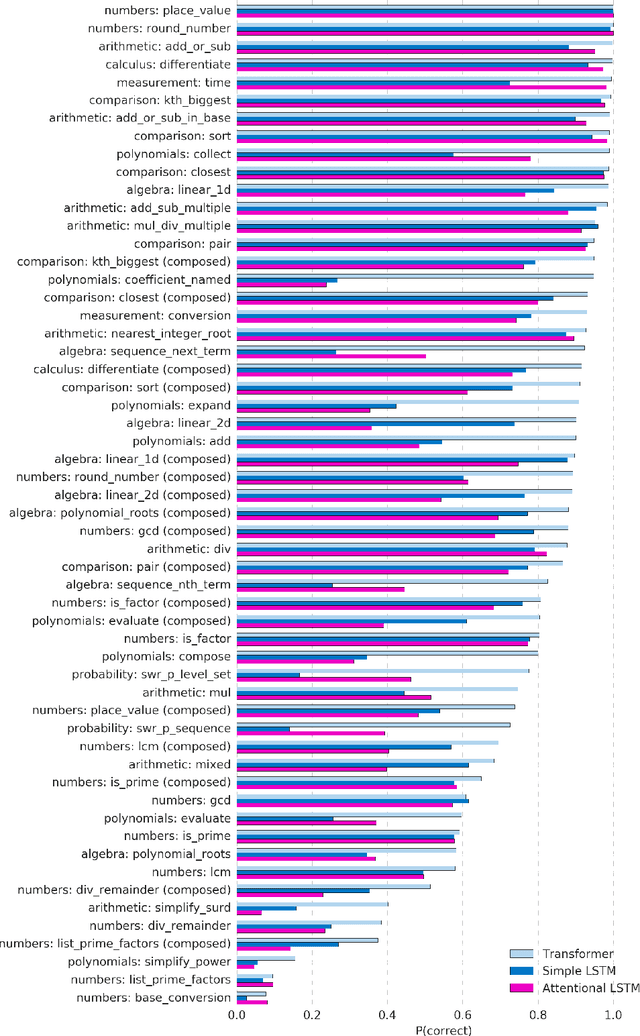
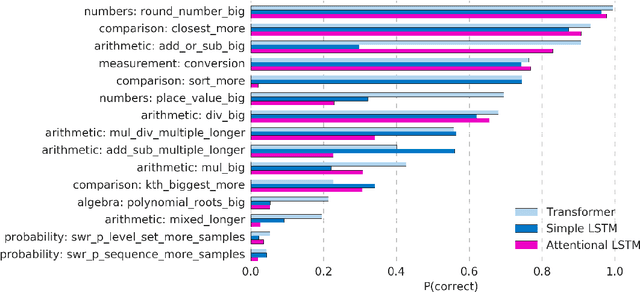
Mathematical reasoning---a core ability within human intelligence---presents some unique challenges as a domain: we do not come to understand and solve mathematical problems primarily on the back of experience and evidence, but on the basis of inferring, learning, and exploiting laws, axioms, and symbol manipulation rules. In this paper, we present a new challenge for the evaluation (and eventually the design) of neural architectures and similar system, developing a task suite of mathematics problems involving sequential questions and answers in a free-form textual input/output format. The structured nature of the mathematics domain, covering arithmetic, algebra, probability and calculus, enables the construction of training and test splits designed to clearly illuminate the capabilities and failure-modes of different architectures, as well as evaluate their ability to compose and relate knowledge and learned processes. Having described the data generation process and its potential future expansions, we conduct a comprehensive analysis of models from two broad classes of the most powerful sequence-to-sequence architectures and find notable differences in their ability to resolve mathematical problems and generalize their knowledge.
Meta-Learning surrogate models for sequential decision making
Mar 28, 2019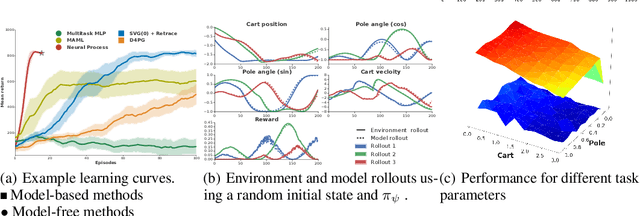

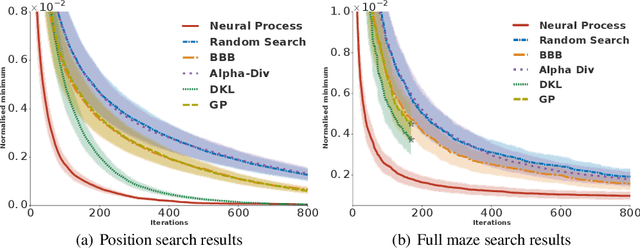
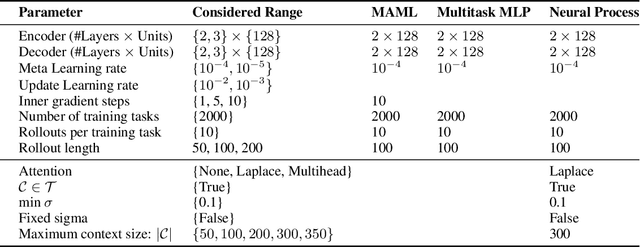
Meta-learning methods leverage past experience to learn data-driven inductive biases from related problems, increasing learning efficiency on new tasks. This ability renders them particularly suitable for sequential decision making with limited experience. Within this problem family, we argue for the use of such approaches in the study of model-based approaches to Bayesian Optimisation, contextual bandits and Reinforcement Learning. We approach the problem by learning distributions over functions using Neural Processes (NPs), a recently introduced probabilistic meta-learning method. This allows the treatment of model uncertainty to tackle the exploration/exploitation dilemma. We show that NPs are suitable for sequential decision making on a diverse set of domains, including adversarial task search, recommender systems and model-based reinforcement learning.
Degenerate Feedback Loops in Recommender Systems
Mar 27, 2019
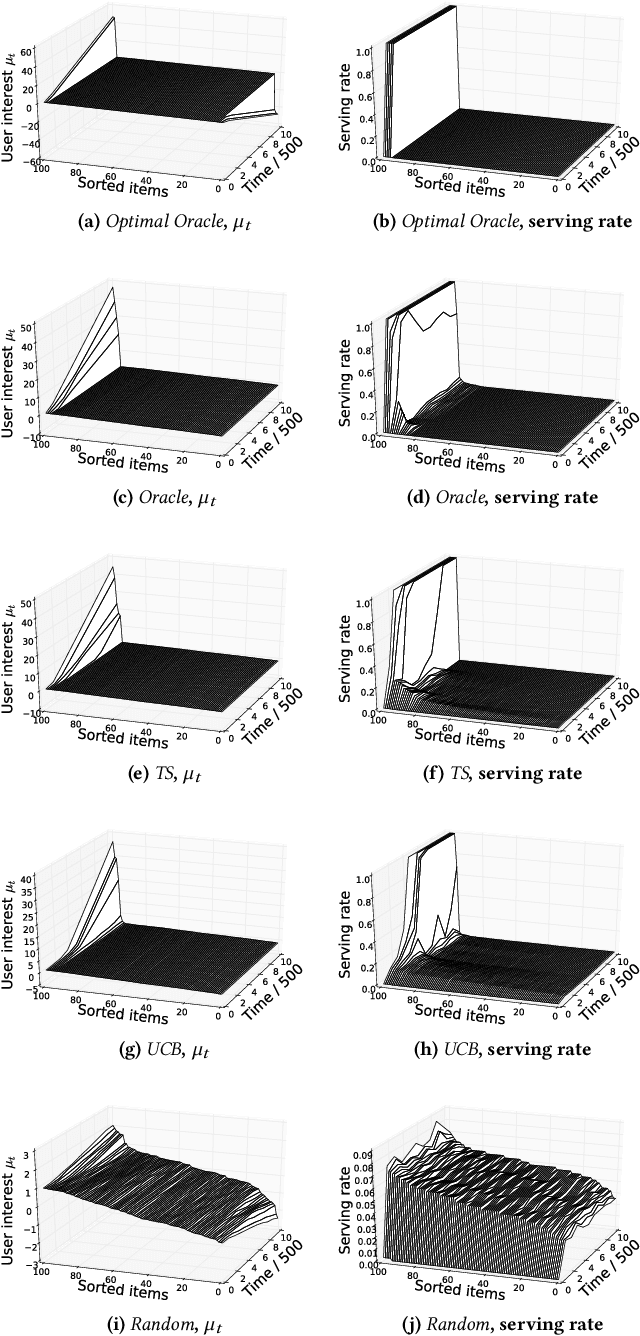
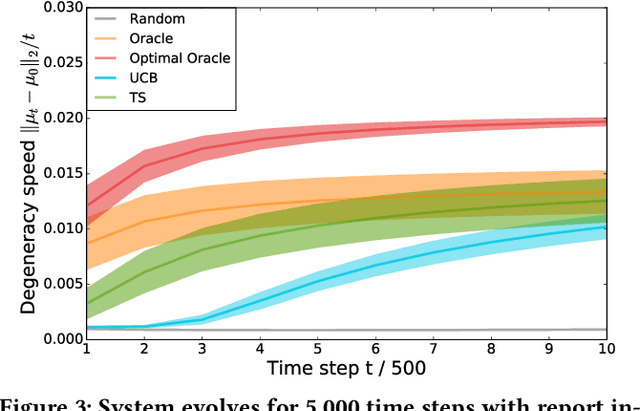
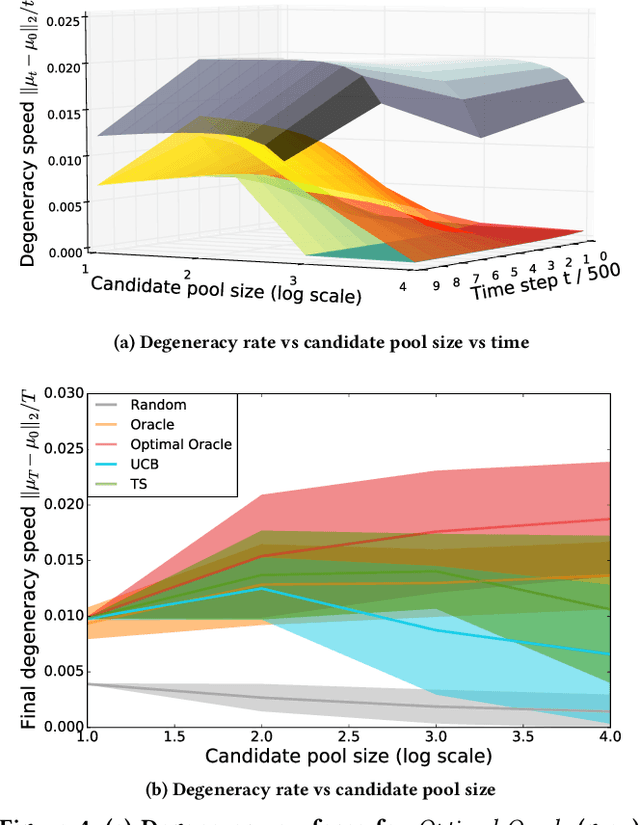
Machine learning is used extensively in recommender systems deployed in products. The decisions made by these systems can influence user beliefs and preferences which in turn affect the feedback the learning system receives - thus creating a feedback loop. This phenomenon can give rise to the so-called "echo chambers" or "filter bubbles" that have user and societal implications. In this paper, we provide a novel theoretical analysis that examines both the role of user dynamics and the behavior of recommender systems, disentangling the echo chamber from the filter bubble effect. In addition, we offer practical solutions to slow down system degeneracy. Our study contributes toward understanding and developing solutions to commonly cited issues in the complex temporal scenario, an area that is still largely unexplored.
Verification of Non-Linear Specifications for Neural Networks
Feb 25, 2019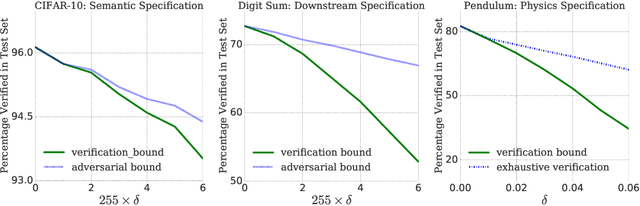
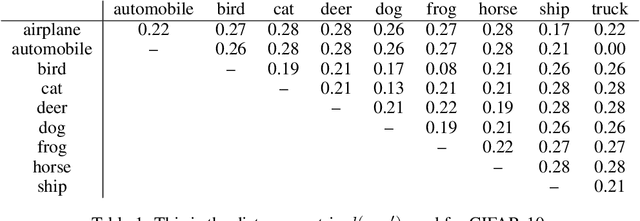
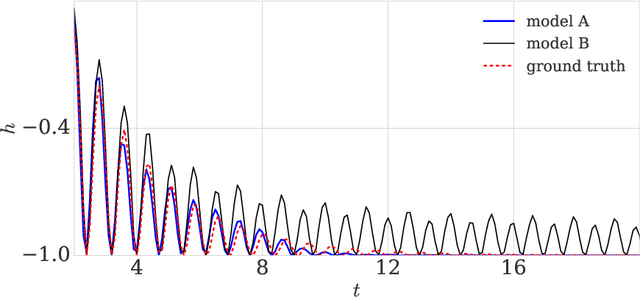
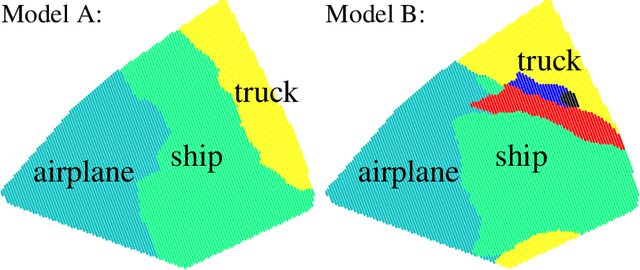
Prior work on neural network verification has focused on specifications that are linear functions of the output of the network, e.g., invariance of the classifier output under adversarial perturbations of the input. In this paper, we extend verification algorithms to be able to certify richer properties of neural networks. To do this we introduce the class of convex-relaxable specifications, which constitute nonlinear specifications that can be verified using a convex relaxation. We show that a number of important properties of interest can be modeled within this class, including conservation of energy in a learned dynamics model of a physical system; semantic consistency of a classifier's output labels under adversarial perturbations and bounding errors in a system that predicts the summation of handwritten digits. Our experimental evaluation shows that our method is able to effectively verify these specifications. Moreover, our evaluation exposes the failure modes in models which cannot be verified to satisfy these specifications. Thus, emphasizing the importance of training models not just to fit training data but also to be consistent with specifications.
Scaling shared model governance via model splitting
Dec 14, 2018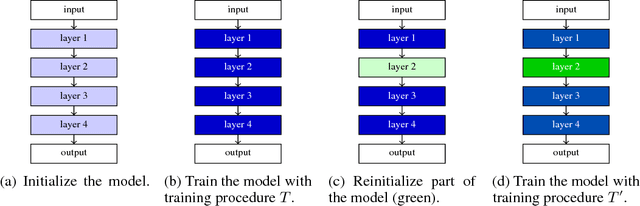

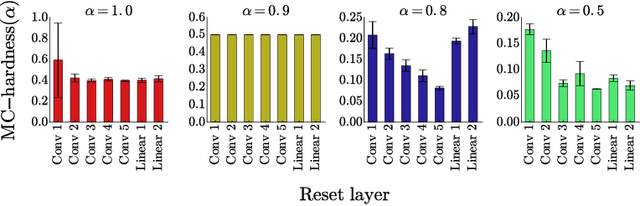

Currently the only techniques for sharing governance of a deep learning model are homomorphic encryption and secure multiparty computation. Unfortunately, neither of these techniques is applicable to the training of large neural networks due to their large computational and communication overheads. As a scalable technique for shared model governance, we propose splitting deep learning model between multiple parties. This paper empirically investigates the security guarantee of this technique, which is introduced as the problem of model completion: Given the entire training data set or an environment simulator, and a subset of the parameters of a trained deep learning model, how much training is required to recover the model's original performance? We define a metric for evaluating the hardness of the model completion problem and study it empirically in both supervised learning on ImageNet and reinforcement learning on Atari and DeepMind~Lab. Our experiments show that (1) the model completion problem is harder in reinforcement learning than in supervised learning because of the unavailability of the trained agent's trajectories, and (2) its hardness depends not primarily on the number of parameters of the missing part, but more so on their type and location. Our results suggest that model splitting might be a feasible technique for shared model governance in some settings where training is very expensive.