 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling shared model governance via model splitting
Paper and Code
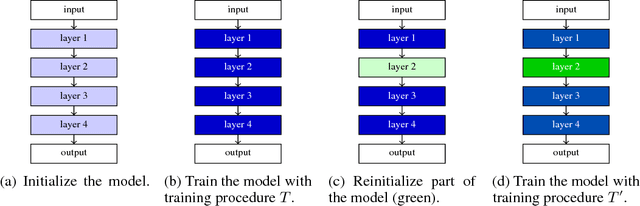

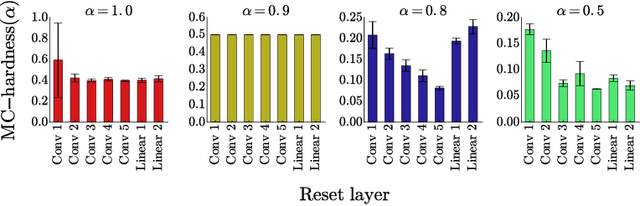

Currently the only techniques for sharing governance of a deep learning model are homomorphic encryption and secure multiparty computation. Unfortunately, neither of these techniques is applicable to the training of large neural networks due to their large computational and communication overheads. As a scalable technique for shared model governance, we propose splitting deep learning model between multiple parties. This paper empirically investigates the security guarantee of this technique, which is introduced as the problem of model completion: Given the entire training data set or an environment simulator, and a subset of the parameters of a trained deep learning model, how much training is required to recover the model's original performance? We define a metric for evaluating the hardness of the model completion problem and study it empirically in both supervised learning on ImageNet and reinforcement learning on Atari and DeepMind~Lab. Our experiments show that (1) the model completion problem is harder in reinforcement learning than in supervised learning because of the unavailability of the trained agent's trajectories, and (2) its hardness depends not primarily on the number of parameters of the missing part, but more so on their type and location. Our results suggest that model splitting might be a feasible technique for shared model governance in some settings where training is very expensive.