 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix
Aug 02, 2024



In computer vision, the vision transformer (ViT) has increasingly superseded the convolutional neural network (CNN) for improved accuracy and robustness. However, ViT's large model sizes and high sample complexity make it difficult to train on resource-constrained edge devices. Split learning (SL) emerges as a viable solution, leveraging server-side resources to train ViTs while utilizing private data from distributed devices. However, SL requires additional information exchange for weight updates between the device and the server, which can be exposed to various attacks on private training data. To mitigate the risk of data breaches in classification tasks, inspired from the CutMix regularization, we propose a novel privacy-preserving SL framework that injects Gaussian noise into smashed data and mixes randomly chosen patches of smashed data across clients, coined DP-CutMixSL. Our analysis demonstrates that DP-CutMixSL is a differentially private (DP) mechanism that strengthens privacy protection against membership inference attacks during forward propagation. Through simulations, we show that DP-CutMixSL improves privacy protection against membership inference attacks, reconstruction attacks, and label inference attacks, while also improving accuracy compared to DP-SL and DP-MixSL.
SplitLoRA: A Split Parameter-Efficient Fine-Tuning Framework for Large Language Models
Jul 01, 2024The scalability of large language models (LLMs) in handling high-complexity models and large-scale datasets has led to tremendous successes in pivotal domains. While there is an urgent need to acquire more training data for LLMs, a concerning reality is the depletion of high-quality public datasets within a few years. In view of this, the federated learning (FL) LLM fine-tuning paradigm recently has been proposed to facilitate collaborative LLM fine-tuning on distributed private data, where multiple data owners collaboratively fine-tune a shared LLM without sharing raw data. However, the staggering model size of LLMs imposes heavy computing and communication burdens on clients, posing significant barriers to the democratization of the FL LLM fine-tuning paradigm. To address this issue, split learning (SL) has emerged as a promising solution by offloading the primary training workload to a server via model partitioning while exchanging activation/activation's gradients with smaller data sizes rather than the entire LLM. Unfortunately, research on the SL LLM fine-tuning paradigm is still in its nascent stage. To fill this gap, in this paper, we propose the first SL LLM fine-tuning framework, named SplitLoRA. SplitLoRA is built on the split federated learning (SFL) framework, amalgamating the advantages of parallel training from FL and model splitting from SL and thus greatly enhancing the training efficiency. It is worth noting that SplitLoRA is the inaugural open-source benchmark for SL LLM fine-tuning, providing a foundation for research efforts dedicated to advancing SL LLM fine-tuning. Extensive simulations validate that SplitLoRA achieves target accuracy in significantly less time than state-of-the-art LLM fine-tuning frameworks, demonstrating the superior training performance of SplitLoRA. The project page is available at https://fduinc.github.io/splitlora/.
DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images
Mar 28, 2024Neural radiance fields (NeRFs) show potential for transforming images captured worldwide into immersive 3D visual experiences. However, most of this captured visual data remains siloed in our camera rolls as these images contain personal details. Even if made public, the problem of learning 3D representations of billions of scenes captured daily in a centralized manner is computationally intractable. Our approach, DecentNeRF, is the first attempt at decentralized, crowd-sourced NeRFs that require $\sim 10^4\times$ less server computing for a scene than a centralized approach. Instead of sending the raw data, our approach requires users to send a 3D representation, distributing the high computation cost of training centralized NeRFs between the users. It learns photorealistic scene representations by decomposing users' 3D views into personal and global NeRFs and a novel optimally weighted aggregation of only the latter. We validate the advantage of our approach to learn NeRFs with photorealism and minimal server computation cost on structured synthetic and real-world photo tourism datasets. We further analyze how secure aggregation of global NeRFs in DecentNeRF minimizes the undesired reconstruction of personal content by the server.
Data Acquisition via Experimental Design for Decentralized Data Markets
Mar 20, 2024Acquiring high-quality training data is essential for current machine learning models. Data markets provide a way to increase the supply of data, particularly in data-scarce domains such as healthcare, by incentivizing potential data sellers to join the market. A major challenge for a data buyer in such a market is selecting the most valuable data points from a data seller. Unlike prior work in data valuation, which assumes centralized data access, we propose a federated approach to the data selection problem that is inspired by linear experimental design. Our proposed data selection method achieves lower prediction error without requiring labeled validation data and can be optimized in a fast and federated procedure. The key insight of our work is that a method that directly estimates the benefit of acquiring data for test set prediction is particularly compatible with a decentralized market setting.
Differentially Private CutMix for Split Learning with Vision Transformer
Oct 28, 2022



Recently, vision transformer (ViT) has started to outpace the conventional CNN in computer vision tasks. Considering privacy-preserving distributed learning with ViT, federated learning (FL) communicates models, which becomes ill-suited due to ViT' s large model size and computing costs. Split learning (SL) detours this by communicating smashed data at a cut-layer, yet suffers from data privacy leakage and large communication costs caused by high similarity between ViT' s smashed data and input data. Motivated by this problem, we propose DP-CutMixSL, a differentially private (DP) SL framework by developing DP patch-level randomized CutMix (DP-CutMix), a novel privacy-preserving inter-client interpolation scheme that replaces randomly selected patches in smashed data. By experiment, we show that DP-CutMixSL not only boosts privacy guarantees and communication efficiency, but also achieves higher accuracy than its Vanilla SL counterpart. Theoretically, we analyze that DP-CutMix amplifies R\'enyi DP (RDP), which is upper-bounded by its Vanilla Mixup counterpart.
Differentially Private Fréchet Mean on the Manifold of Symmetric Positive Definite (SPD) Matrices
Aug 08, 2022
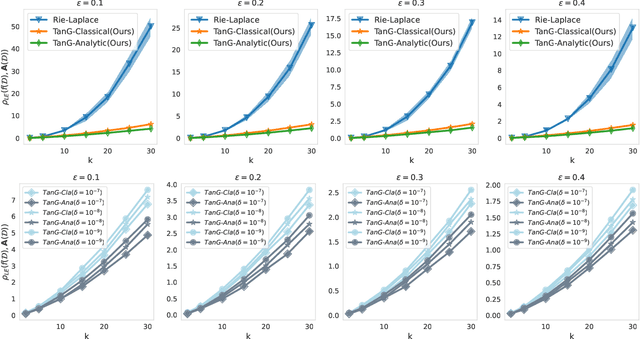
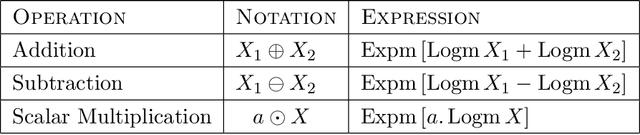
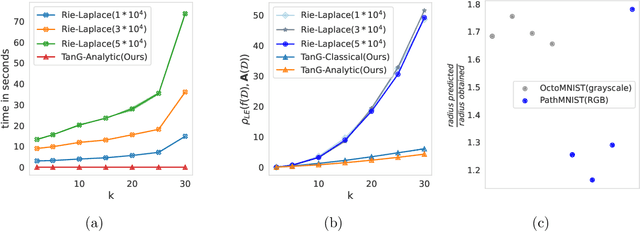
Differential privacy has become crucial in the real-world deployment of statistical and machine learning algorithms with rigorous privacy guarantees. The earliest statistical queries, for which differential privacy mechanisms have been developed, were for the release of the sample mean. In Geometric Statistics, the sample Fr\'echet mean represents one of the most fundamental statistical summaries, as it generalizes the sample mean for data belonging to nonlinear manifolds. In that spirit, the only geometric statistical query for which a differential privacy mechanism has been developed, so far, is for the release of the sample Fr\'echet mean: the \emph{Riemannian Laplace mechanism} was recently proposed to privatize the Fr\'echet mean on complete Riemannian manifolds. In many fields, the manifold of Symmetric Positive Definite (SPD) matrices is used to model data spaces, including in medical imaging where privacy requirements are key. We propose a novel, simple and fast mechanism - the \emph{Tangent Gaussian mechanism} - to compute a differentially private Fr\'echet mean on the SPD manifold endowed with the log-Euclidean Riemannian metric. We show that our new mechanism obtains quadratic utility improvement in terms of data dimension over the current and only available baseline. Our mechanism is also simpler in practice as it does not require any expensive Markov Chain Monte Carlo (MCMC) sampling, and is computationally faster by multiple orders of magnitude -- as confirmed by extensive experiments.
Private independence testing across two parties
Jul 08, 2022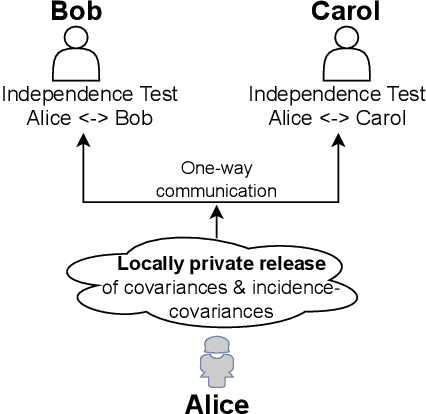

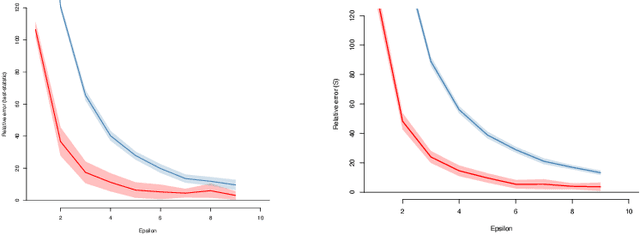
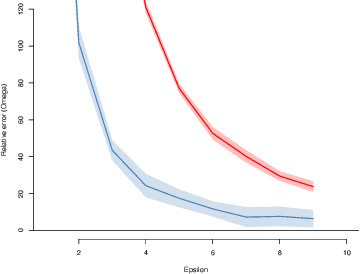
We introduce $\pi$-test, a privacy-preserving algorithm for testing statistical independence between data distributed across multiple parties. Our algorithm relies on privately estimating the distance correlation between datasets, a quantitative measure of independence introduced in Sz\'ekely et al. [2007]. We establish both additive and multiplicative error bounds on the utility of our differentially private test, which we believe will find applications in a variety of distributed hypothesis testing settings involving sensitive data.
Visual Transformer Meets CutMix for Improved Accuracy, Communication Efficiency, and Data Privacy in Split Learning
Jul 01, 2022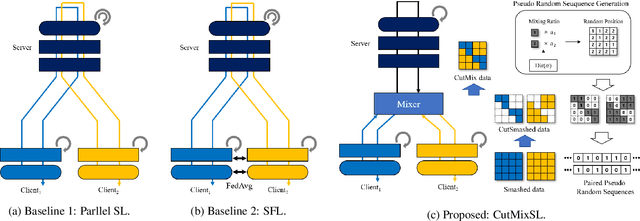
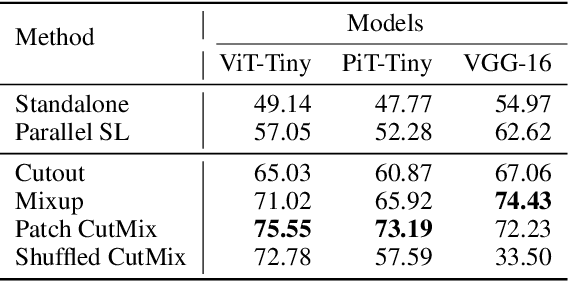
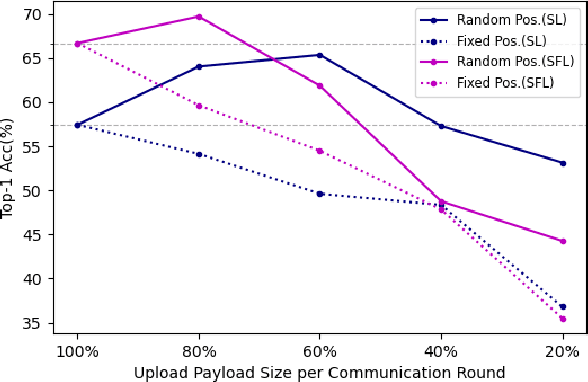
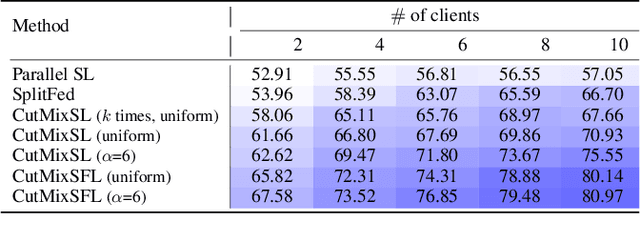
This article seeks for a distributed learning solution for the visual transformer (ViT) architectures. Compared to convolutional neural network (CNN) architectures, ViTs often have larger model sizes, and are computationally expensive, making federated learning (FL) ill-suited. Split learning (SL) can detour this problem by splitting a model and communicating the hidden representations at the split-layer, also known as smashed data. Notwithstanding, the smashed data of ViT are as large as and as similar as the input data, negating the communication efficiency of SL while violating data privacy. To resolve these issues, we propose a new form of CutSmashed data by randomly punching and compressing the original smashed data. Leveraging this, we develop a novel SL framework for ViT, coined CutMixSL, communicating CutSmashed data. CutMixSL not only reduces communication costs and privacy leakage, but also inherently involves the CutMix data augmentation, improving accuracy and scalability. Simulations corroborate that CutMixSL outperforms baselines such as parallelized SL and SplitFed that integrates FL with SL.
Decouple-and-Sample: Protecting sensitive information in task agnostic data release
Mar 17, 2022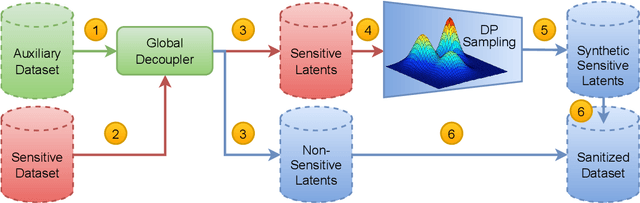
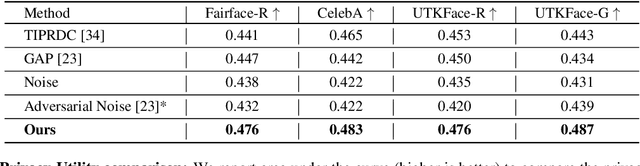
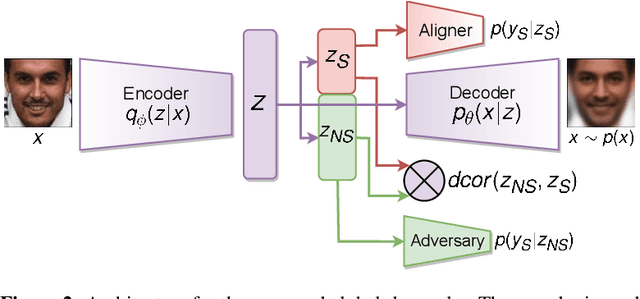
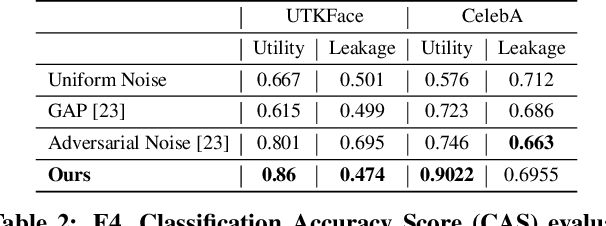
We propose sanitizer, a framework for secure and task-agnostic data release. While releasing datasets continues to make a big impact in various applications of computer vision, its impact is mostly realized when data sharing is not inhibited by privacy concerns. We alleviate these concerns by sanitizing datasets in a two-stage process. First, we introduce a global decoupling stage for decomposing raw data into sensitive and non-sensitive latent representations. Secondly, we design a local sampling stage to synthetically generate sensitive information with differential privacy and merge it with non-sensitive latent features to create a useful representation while preserving the privacy. This newly formed latent information is a task-agnostic representation of the original dataset with anonymized sensitive information. While most algorithms sanitize data in a task-dependent manner, a few task-agnostic sanitization techniques sanitize data by censoring sensitive information. In this work, we show that a better privacy-utility trade-off is achieved if sensitive information can be synthesized privately. We validate the effectiveness of the sanitizer by outperforming state-of-the-art baselines on the existing benchmark tasks and demonstrating tasks that are not possible using existing techniques.
Server-Side Local Gradient Averaging and Learning Rate Acceleration for Scalable Split Learning
Dec 11, 2021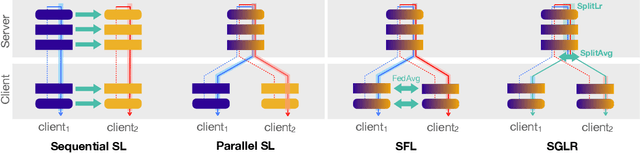
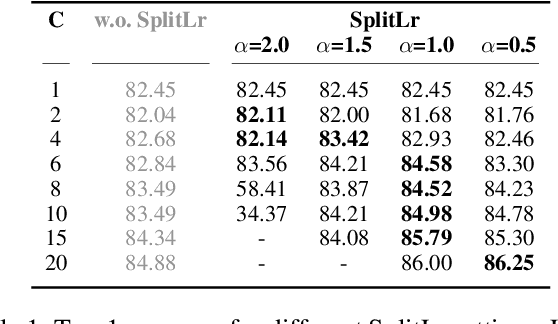
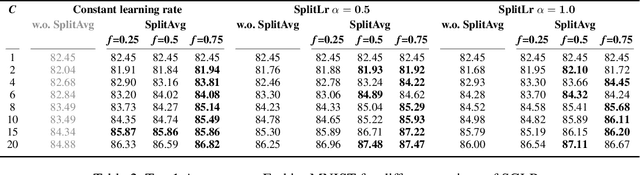

In recent years, there have been great advances in the field of decentralized learning with private data. Federated learning (FL) and split learning (SL) are two spearheads possessing their pros and cons, and are suited for many user clients and large models, respectively. To enjoy both benefits, hybrid approaches such as SplitFed have emerged of late, yet their fundamentals have still been illusive. In this work, we first identify the fundamental bottlenecks of SL, and thereby propose a scalable SL framework, coined SGLR. The server under SGLR broadcasts a common gradient averaged at the split-layer, emulating FL without any additional communication across clients as opposed to SplitFed. Meanwhile, SGLR splits the learning rate into its server-side and client-side rates, and separately adjusts them to support many clients in parallel. Simulation results corroborate that SGLR achieves higher accuracy than other baseline SL methods including SplitFed, which is even on par with FL consuming higher energy and communication costs. As a secondary result, we observe greater reduction in leakage of sensitive information via mutual information using SLGR over the baselines.