 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCGuard: Latent Communication Guard for Safe KV Sharing in Multi-Agent Systems
May 21, 2026Large language model (LLM)-based multi-agent systems increasingly rely on intermediate communication to coordinate complex tasks. While most existing systems communicate through natural language, recent work shows that latent communication, particularly through transformer key-value (KV) caches, can improve efficiency and preserve richer task-relevant information. However, KV caches also encode contextual inputs, intermediate reasoning states, and agent-specific information, creating an opaque channel through which sensitive content may propagate across agents without explicit textual disclosure. To address this, we introduce \textbf{LCGuard} (Latent Communication Guard), a framework for safe KV-based latent communication in multi-agent LLM systems. LCGuard treats shared KV caches as latent working memory and learns representation-level transformations before cache artifacts are transmitted across agents. We formalize representation-level sensitive information leakage operationally through reconstruction: a shared cache artifact is unsafe if an adversarial decoder can recover agent-specific sensitive inputs from it. This leads to an adversarial training formulation in which the adversary learns to reconstruct sensitive inputs, while LCGuard learns transformations that preserve task-relevant semantics and reduce reconstructable information. Empirical evaluations across multiple model families and multi-agent benchmarks show that LCGuard consistently reduces reconstruction-based leakage and attack success rates while maintaining competitive task performance compared to standard KV-sharing baselines.
MM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
May 12, 2026Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
RefusalGuard: Geometry-Preserving Fine-Tuning for Safety in LLMs
May 03, 2026Fine-tuning safety-aligned language models for downstream tasks often leads to substantial degradation of refusal behavior, making models vulnerable to adversarial misuse. While prior work has shown that safety-relevant features are encoded in structured representations within the model's activation space, how these representations change during fine-tuning and why alignment degrades remains poorly understood. In this work, we investigate the representation-level mechanisms underlying alignment degradation. Our analysis shows that standard fine-tuning induces systematic drift in safety-relevant representations, distorts their geometric structure, and introduces interference between task optimization and safety features. These effects collectively lead to increased harmful compliance. Motivated by these findings, we introduce REFUSALGUARD, a representation-level fine-tuning framework that preserves safety-relevant structure during model adaptation. Our approach constrains updates in hidden representation space, ensuring that safety-mediating components remain stable while allowing task-specific learning in complementary directions. We evaluate REFUSALGUARD across multiple model families, including LLaMA, Gemma, and Qwen, on adversarial safety benchmarks such as AdvBench, DirectHarm4, and JailbreakBench, as well as downstream utility tasks. Our approach achieves attack success rates comparable to base safety-aligned models while maintaining competitive task performance, significantly outperforming baselines.
WIN-U: Woodbury-Informed Newton-Unlearning as a retain-free Machine Unlearning Framework
Apr 15, 2026Privacy concerns in LLMs have led to the rapidly growing need to enforce a data's "right to be forgotten". Machine unlearning addresses precisely this task, namely the removal of the influence of some specific data, i.e., the forget set, from a trained model. The gold standard for unlearning is to produce the model that would have been learned on only the rest of the training data, i.e., the retain set. Most existing unlearning methods rely on direct access to the retained data, which may not be practical due to privacy or cost constraints. We propose WIN-U, a retained-data free unlearning framework that requires only second order information for the originally trained model on the full data. The unlearning is performed using a single Newton-style step. Using the Woodbury matrix identity and a generalized Gauss-Newton approximation for the forget set curvature, the WIN-U update recovers the closed-form linear solution and serves as a local second-order approximation to the gold-standard retraining optimum. Extensive experiments on various vision and language benchmarks demonstrate that WIN-U achieves SOTA performance in terms of unlearning efficacy and utility preservation, while being more robust against relearning attacks compared to existing methods. Importantly, WIN-U does not require access to the retained data.
ZoomR: Memory Efficient Reasoning through Multi-Granularity Key Value Retrieval
Apr 13, 2026Large language models (LLMs) have shown great performance on complex reasoning tasks but often require generating long intermediate thoughts before reaching a final answer. During generation, LLMs rely on a key-value (KV) cache for autoregressive decoding. However, the memory footprint of the KV cache grows with output length. Prior work on KV cache optimization mostly focus on compressing the long input context, while retaining the full KV cache for decoding. For tasks requiring long output generation, this leads to increased computational and memory costs. In this paper, we introduce ZoomR, a novel approach that enables LLMs to adaptively compress verbose reasoning thoughts into summaries and uses a dynamic KV cache selection policy that leverages these summaries while also strategically "zooming in" on fine-grained details. By using summary keys as a coarse-grained index during decoding, ZoomR uses the query to retrieve details for only the most important thoughts. This hierarchical strategy significantly reduces memory usage by avoiding full-cache attention at each step. Experiments across math and reasoning tasks show that our approach achieves competitive performance compared to baselines, while reducing inference memory requirements by more than $4\times$. These results demonstrate that a multi-granularity KV selection enables more memory efficient decoding, especially for long output generation.
The Alignment Game: A Theory of Long-Horizon Alignment Through Recursive Curation
Nov 16, 2025In self-consuming generative models that train on their own outputs, alignment with user preferences becomes a recursive rather than one-time process. We provide the first formal foundation for analyzing the long-term effects of such recursive retraining on alignment. Under a two-stage curation mechanism based on the Bradley-Terry (BT) model, we model alignment as an interaction between two factions: the Model Owner, who filters which outputs should be learned by the model, and the Public User, who determines which outputs are ultimately shared and retained through interactions with the model. Our analysis reveals three structural convergence regimes depending on the degree of preference alignment: consensus collapse, compromise on shared optima, and asymmetric refinement. We prove a fundamental impossibility theorem: no recursive BT-based curation mechanism can simultaneously preserve diversity, ensure symmetric influence, and eliminate dependence on initialization. Framing the process as dynamic social choice, we show that alignment is not a static goal but an evolving equilibrium, shaped both by power asymmetries and path dependence.
Towards Reversible Model Merging For Low-rank Weights
Oct 15, 2025Model merging aims to combine multiple fine-tuned models into a single set of weights that performs well across all source tasks. While prior work has shown that merging can approximate the performance of individual fine-tuned models for each task, it largely overlooks scenarios where models are compressed into low-rank representations, either through low-rank adaptation (LoRA) or post-training singular value decomposition (SVD). We first demonstrate that applying conventional merging methods to low-rank weights leads to severe performance degradation in the merged model. Motivated by this phenomenon, we propose a fundamentally different approach: instead of collapsing all adapters into one set of weights, we construct a compact basis (e.g., an equivalent of holding two or more models) from which original task-specific models can be recovered via linear combination. This reframes merging as generating a reconstruction-capable model space rather than producing a single merged model. Crucially, this allows us to ``revert'' to each individual model when needed, recognizing that no merged model can consistently outperform one specialized for its task. Building on this insight, we introduce our method, Reversible Model Merging (RMM), an efficient, data-free, and flexible method that provides a closed-form solution for selecting the optimal basis of model weights and task-specific coefficients for linear combination. Extensive experiments across diverse datasets and model scales demonstrate that RMM consistently outperforms existing merging approaches, preserving the performance of low-rank compressed models by a significant margin.
OFMU: Optimization-Driven Framework for Machine Unlearning
Sep 26, 2025Large language models deployed in sensitive applications increasingly require the ability to unlearn specific knowledge, such as user requests, copyrighted materials, or outdated information, without retraining from scratch to ensure regulatory compliance, user privacy, and safety. This task, known as machine unlearning, aims to remove the influence of targeted data (forgetting) while maintaining performance on the remaining data (retention). A common approach is to formulate this as a multi-objective problem and reduce it to a single-objective problem via scalarization, where forgetting and retention losses are combined using a weighted sum. However, this often results in unstable training dynamics and degraded model utility due to conflicting gradient directions. To address these challenges, we propose OFMU, a penalty-based bi-level optimization framework that explicitly prioritizes forgetting while preserving retention through a hierarchical structure. Our method enforces forgetting via an inner maximization step that incorporates a similarity-aware penalty to decorrelate the gradients of the forget and retention objectives, and restores utility through an outer minimization step. To ensure scalability, we develop a two-loop algorithm with provable convergence guarantees under both convex and non-convex regimes. We further provide a rigorous theoretical analysis of convergence rates and show that our approach achieves better trade-offs between forgetting efficacy and model utility compared to prior methods. Extensive experiments across vision and language benchmarks demonstrate that OFMU consistently outperforms existing unlearning methods in both forgetting efficacy and retained utility.
Toward Efficient Influence Function: Dropout as a Compression Tool
Sep 19, 2025
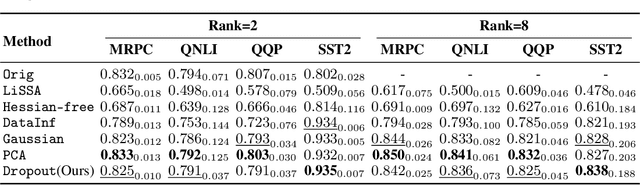
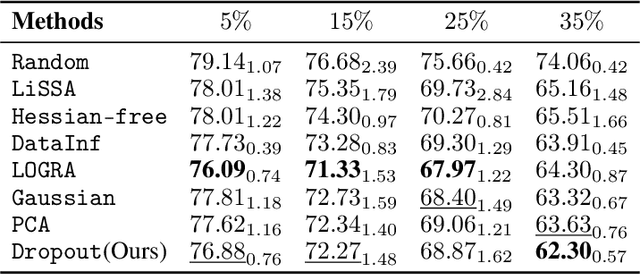
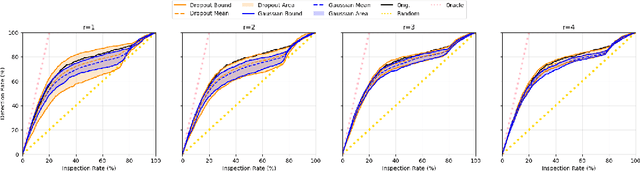
Assessing the impact the training data on machine learning models is crucial for understanding the behavior of the model, enhancing the transparency, and selecting training data. Influence function provides a theoretical framework for quantifying the effect of training data points on model's performance given a specific test data. However, the computational and memory costs of influence function presents significant challenges, especially for large-scale models, even when using approximation methods, since the gradients involved in computation are as large as the model itself. In this work, we introduce a novel approach that leverages dropout as a gradient compression mechanism to compute the influence function more efficiently. Our method significantly reduces computational and memory overhead, not only during the influence function computation but also in gradient compression process. Through theoretical analysis and empirical validation, we demonstrate that our method could preserves critical components of the data influence and enables its application to modern large-scale models.
SentenceKV: Efficient LLM Inference via Sentence-Level Semantic KV Caching
Apr 01, 2025



Large language models face significant computational and memory challenges when processing long contexts. During inference, efficient management of the key-value (KV) cache, which stores intermediate activations for autoregressive generation, is critical to reducing memory overhead and improving computational efficiency. Traditional token-level efficient KV caching methods overlook semantic information, treating tokens independently without considering their semantic relationships. Meanwhile, existing semantic-preserving KV cache management approaches often suffer from substantial memory usage and high time-to-first-token. To address these limitations, we propose SentenceKV, a novel sentence-level semantic KV caching approach designed to enhance inference efficiency while preserving semantic coherence. During prefilling, SentenceKV groups tokens based on sentence-level semantic similarity, compressing sentence representations into concise semantic vectors stored directly on the GPU, while individual KV pairs are offloaded to CPU. During decoding, SentenceKV generates tokens by selectively retrieving semantically relevant sentence-level KV entries, leveraging the semantic similarity between the prefilling-stage semantic vectors and decoding-stage queries. This ensures efficient and contextually accurate predictions, minimizing the loading of redundant or irrelevant data into GPU memory and significantly reducing memory overhead while maintaining stable inference latency, even for extremely long contexts. Extensive evaluations on benchmarks including PG-19, LongBench, and Needle-In-A-Haystack demonstrate that SentenceKV significantly outperforms state-of-the-art methods in both efficiency and memory usage, without compromising model accuracy.