 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Image Classification Using Sequential Attention Models
Dec 04, 2019
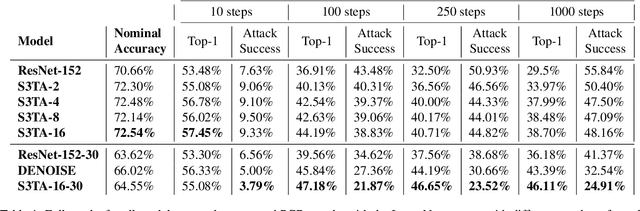
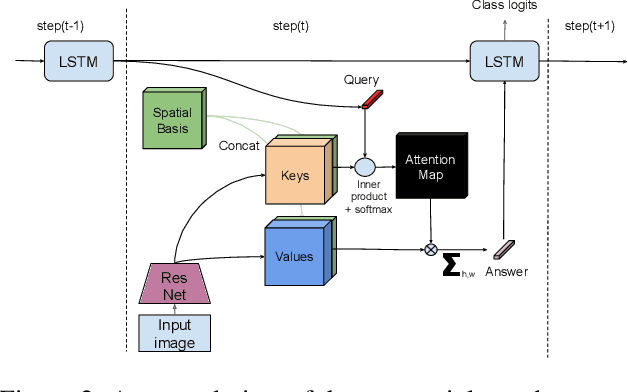

In this paper we propose to augment a modern neural-network architecture with an attention model inspired by human perception. Specifically, we adversarially train and analyze a neural model incorporating a human inspired, visual attention component that is guided by a recurrent top-down sequential process. Our experimental evaluation uncovers several notable findings about the robustness and behavior of this new model. First, introducing attention to the model significantly improves adversarial robustness resulting in state-of-the-art ImageNet accuracies under a wide range of random targeted attack strengths. Second, we show that by varying the number of attention steps (glances/fixations) for which the model is unrolled, we are able to make its defense capabilities stronger, even in light of stronger attacks --- resulting in a "computational race" between the attacker and the defender. Finally, we show that some of the adversarial examples generated by attacking our model are quite different from conventional adversarial examples --- they contain global, salient and spatially coherent structures coming from the target class that would be recognizable even to a human, and work by distracting the attention of the model away from the main object in the original image.
Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019
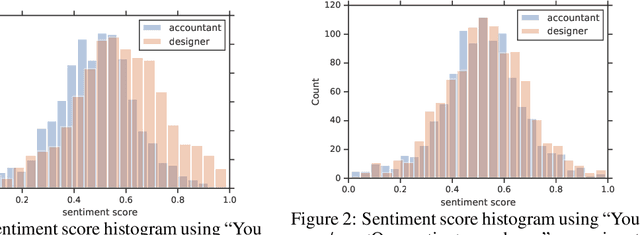
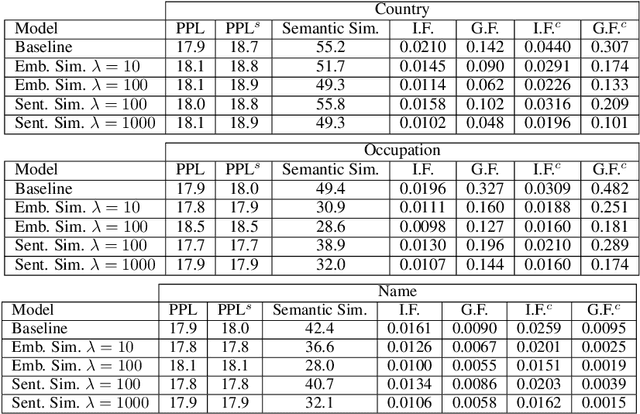
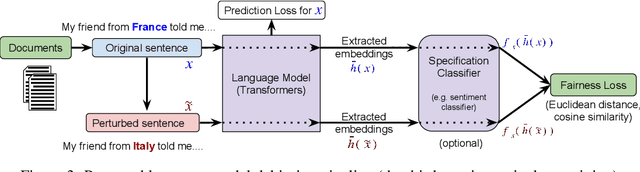
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
Learning Transferable Graph Exploration
Oct 28, 2019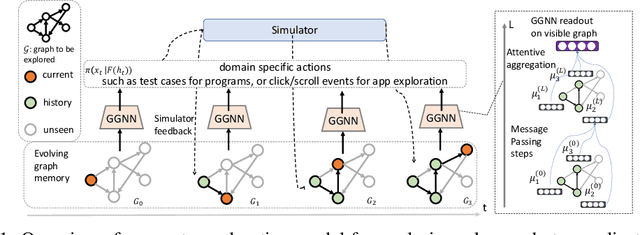
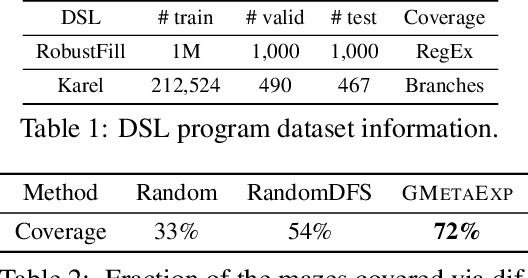


This paper considers the problem of efficient exploration of unseen environments, a key challenge in AI. We propose a `learning to explore' framework where we learn a policy from a distribution of environments. At test time, presented with an unseen environment from the same distribution, the policy aims to generalize the exploration strategy to visit the maximum number of unique states in a limited number of steps. We particularly focus on environments with graph-structured state-spaces that are encountered in many important real-world applications like software testing and map building. We formulate this task as a reinforcement learning problem where the `exploration' agent is rewarded for transitioning to previously unseen environment states and employ a graph-structured memory to encode the agent's past trajectory. Experimental results demonstrate that our approach is extremely effective for exploration of spatial maps; and when applied on the challenging problems of coverage-guided software-testing of domain-specific programs and real-world mobile applications, it outperforms methods that have been hand-engineered by human experts.
An Alternative Surrogate Loss for PGD-based Adversarial Testing
Oct 21, 2019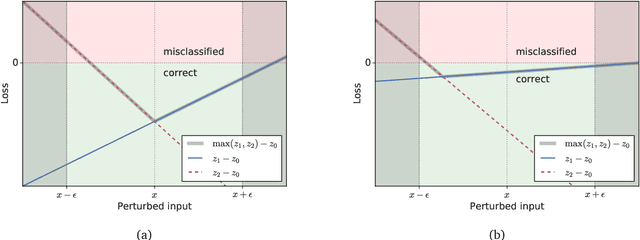

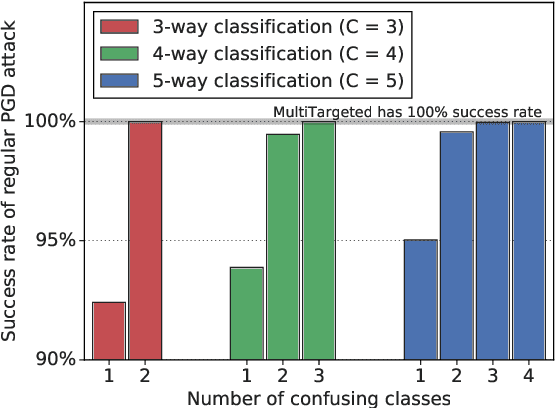

Adversarial testing methods based on Projected Gradient Descent (PGD) are widely used for searching norm-bounded perturbations that cause the inputs of neural networks to be misclassified. This paper takes a deeper look at these methods and explains the effect of different hyperparameters (i.e., optimizer, step size and surrogate loss). We introduce the concept of MultiTargeted testing, which makes clever use of alternative surrogate losses, and explain when and how MultiTargeted is guaranteed to find optimal perturbations. Finally, we demonstrate that MultiTargeted outperforms more sophisticated methods and often requires less iterative steps than other variants of PGD found in the literature. Notably, MultiTargeted ranks first on MadryLab's white-box MNIST and CIFAR-10 leaderboards, reducing the accuracy of their MNIST model to 88.36% (with $\ell_\infty$ perturbations of $\epsilon = 0.3$) and the accuracy of their CIFAR-10 model to 44.03% (at $\epsilon = 8/255$). MultiTargeted also ranks first on the TRADES leaderboard reducing the accuracy of their CIFAR-10 model to 53.07% (with $\ell_\infty$ perturbations of $\epsilon = 0.031$).
Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation
Sep 03, 2019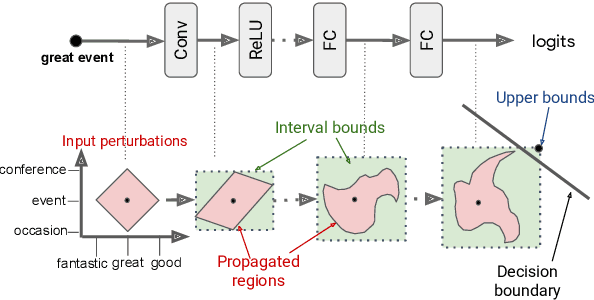


Neural networks are part of many contemporary NLP systems, yet their empirical successes come at the price of vulnerability to adversarial attacks. Previous work has used adversarial training and data augmentation to partially mitigate such brittleness, but these are unlikely to find worst-case adversaries due to the complexity of the search space arising from discrete text perturbations. In this work, we approach the problem from the opposite direction: to formally verify a system's robustness against a predefined class of adversarial attacks. We study text classification under synonym replacements or character flip perturbations. We propose modeling these input perturbations as a simplex and then using Interval Bound Propagation -- a formal model verification method. We modify the conventional log-likelihood training objective to train models that can be efficiently verified, which would otherwise come with exponential search complexity. The resulting models show only little difference in terms of nominal accuracy, but have much improved verified accuracy under perturbations and come with an efficiently computable formal guarantee on worst case adversaries.
Knowing When to Stop: Evaluation and Verification of Conformity to Output-size Specifications
Apr 26, 2019
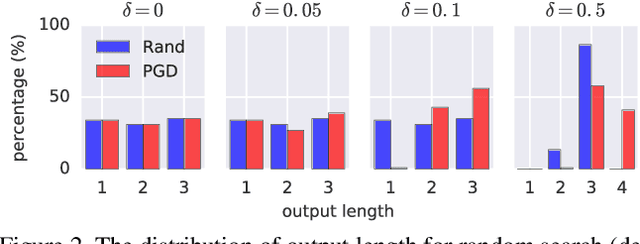
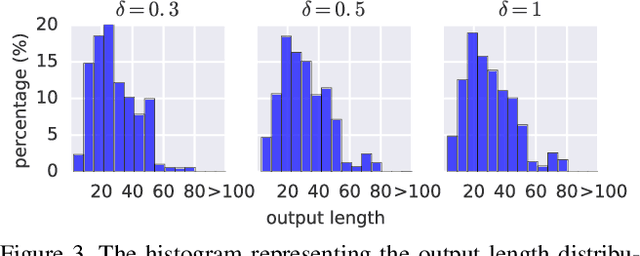
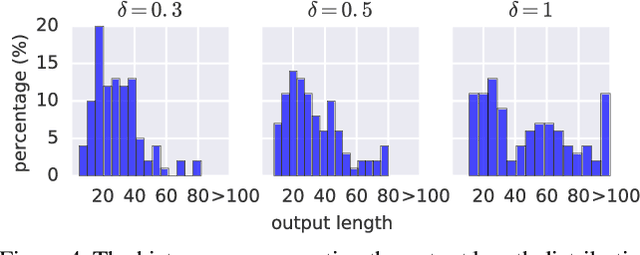
Models such as Sequence-to-Sequence and Image-to-Sequence are widely used in real world applications. While the ability of these neural architectures to produce variable-length outputs makes them extremely effective for problems like Machine Translation and Image Captioning, it also leaves them vulnerable to failures of the form where the model produces outputs of undesirable length. This behavior can have severe consequences such as usage of increased computation and induce faults in downstream modules that expect outputs of a certain length. Motivated by the need to have a better understanding of the failures of these models, this paper proposes and studies the novel output-size modulation problem and makes two key technical contributions. First, to evaluate model robustness, we develop an easy-to-compute differentiable proxy objective that can be used with gradient-based algorithms to find output-lengthening inputs. Second and more importantly, we develop a verification approach that can formally verify whether a network always produces outputs within a certain length. Experimental results on Machine Translation and Image Captioning show that our output-lengthening approach can produce outputs that are 50 times longer than the input, while our verification approach can, given a model and input domain, prove that the output length is below a certain size.
Neural Phrase-to-Phrase Machine Translation
Nov 06, 2018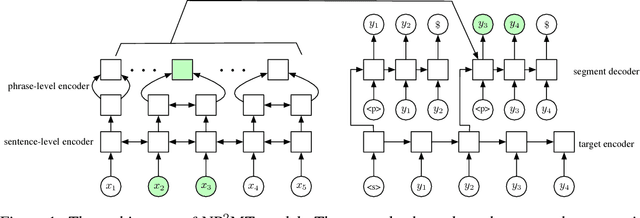
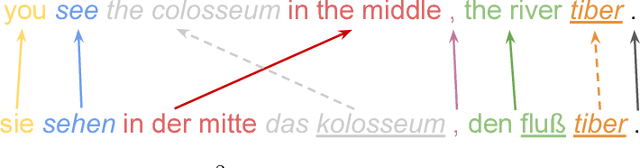
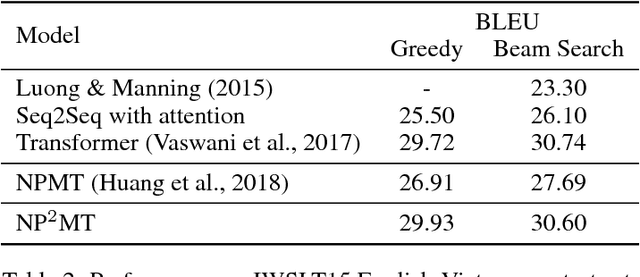
In this paper, we propose Neural Phrase-to-Phrase Machine Translation (NP$^2$MT). Our model uses a phrase attention mechanism to discover relevant input (source) segments that are used by a decoder to generate output (target) phrases. We also design an efficient dynamic programming algorithm to decode segments that allows the model to be trained faster than the existing neural phrase-based machine translation method by Huang et al. (2018). Furthermore, our method can naturally integrate with external phrase dictionaries during decoding. Empirical experiments show that our method achieves comparable performance with the state-of-the art methods on benchmark datasets. However, when the training and testing data are from different distributions or domains, our method performs better.
M-Walk: Learning to Walk over Graphs using Monte Carlo Tree Search
Nov 01, 2018
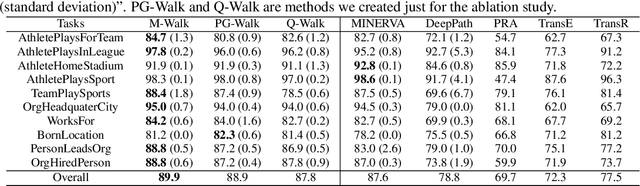
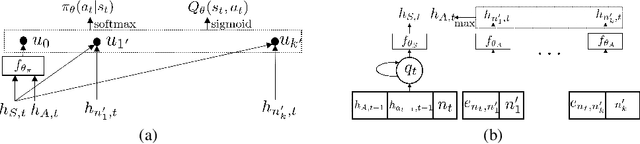

Learning to walk over a graph towards a target node for a given query and a source node is an important problem in applications such as knowledge base completion (KBC). It can be formulated as a reinforcement learning (RL) problem with a known state transition model. To overcome the challenge of sparse rewards, we develop a graph-walking agent called M-Walk, which consists of a deep recurrent neural network (RNN) and Monte Carlo Tree Search (MCTS). The RNN encodes the state (i.e., history of the walked path) and maps it separately to a policy and Q-values. In order to effectively train the agent from sparse rewards, we combine MCTS with the neural policy to generate trajectories yielding more positive rewards. From these trajectories, the network is improved in an off-policy manner using Q-learning, which modifies the RNN policy via parameter sharing. Our proposed RL algorithm repeatedly applies this policy-improvement step to learn the model. At test time, MCTS is combined with the neural policy to predict the target node. Experimental results on several graph-walking benchmarks show that M-Walk is able to learn better policies than other RL-based methods, which are mainly based on policy gradients. M-Walk also outperforms traditional KBC baselines.
Towards Neural Phrase-based Machine Translation
Sep 24, 2018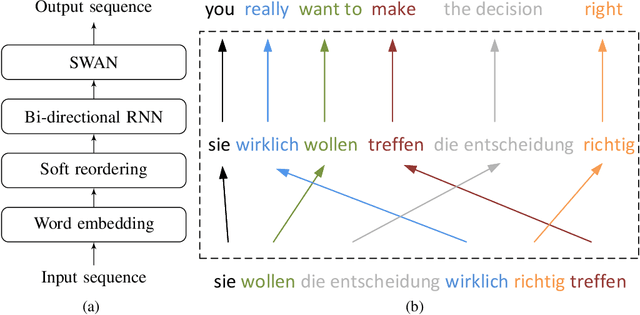
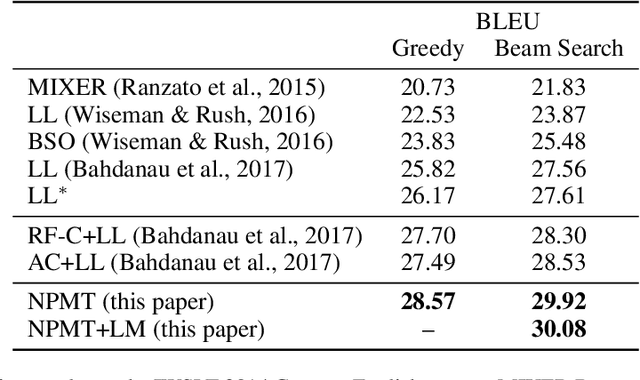
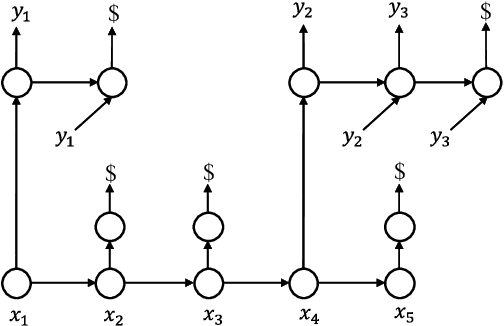

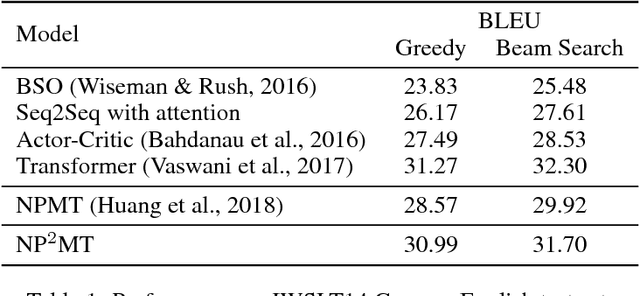
In this paper, we present Neural Phrase-based Machine Translation (NPMT). Our method explicitly models the phrase structures in output sequences using Sleep-WAke Networks (SWAN), a recently proposed segmentation-based sequence modeling method. To mitigate the monotonic alignment requirement of SWAN, we introduce a new layer to perform (soft) local reordering of input sequences. Different from existing neural machine translation (NMT) approaches, NPMT does not use attention-based decoding mechanisms. Instead, it directly outputs phrases in a sequential order and can decode in linear time. Our experiments show that NPMT achieves superior performances on IWSLT 2014 German-English/English-German and IWSLT 2015 English-Vietnamese machine translation tasks compared with strong NMT baselines. We also observe that our method produces meaningful phrases in output languages.
Robust Text-to-SQL Generation with Execution-Guided Decoding
Sep 13, 2018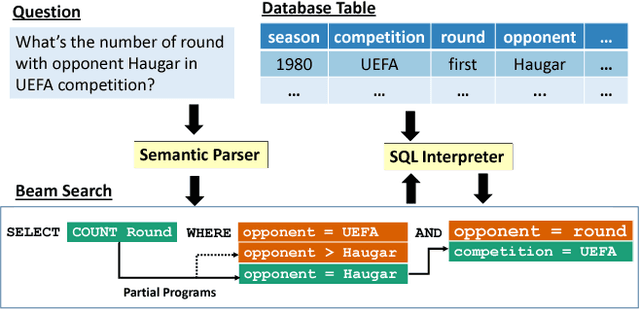
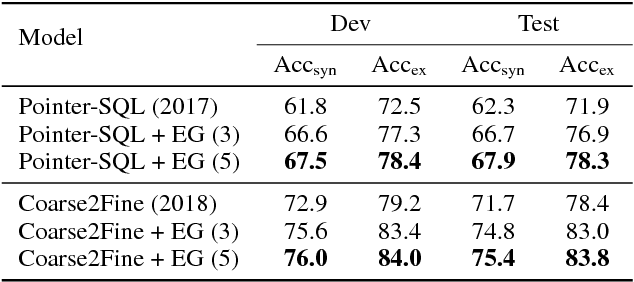
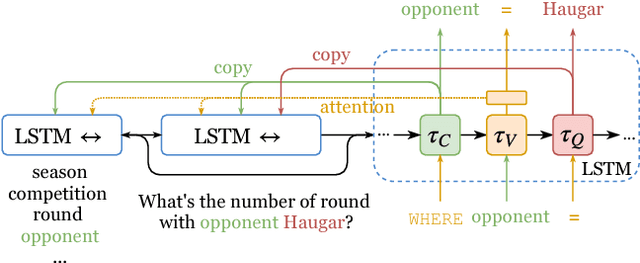
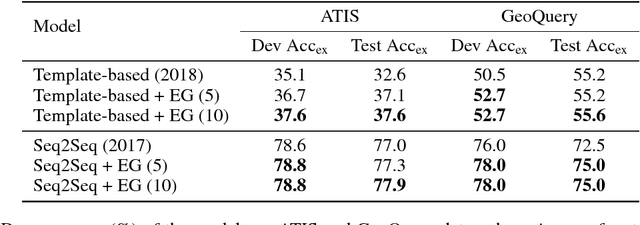
We consider the problem of neural semantic parsing, which translates natural language questions into executable SQL queries. We introduce a new mechanism, execution guidance, to leverage the semantics of SQL. It detects and excludes faulty programs during the decoding procedure by conditioning on the execution of partially generated program. The mechanism can be used with any autoregressive generative model, which we demonstrate on four state-of-the-art recurrent or template-based semantic parsing models. We demonstrate that execution guidance universally improves model performance on various text-to-SQL datasets with different scales and query complexity: WikiSQL, ATIS, and GeoQuery. As a result, we achieve new state-of-the-art execution accuracy of 83.8% on WikiSQL.