 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer Bubbles: Information Exposure in AI-Mediated Search
Mar 17, 2026Generative search systems are increasingly replacing link-based retrieval with AI-generated summaries, yet little is known about how these systems differ in sources, language, and fidelity to cited material. We examine responses to 11,000 real search queries across four systems -- vanilla GPT, Search GPT, Google AI Overviews, and traditional Google Search -- at three levels: source diversity, linguistic characterization of the generated summary, and source-summary fidelity. We find that generative search systems exhibit significant \textit{source-selection} biases in their citations, favoring certain sources over others. Incorporating search also selectively attenuates epistemic markers, reducing hedging by up to 60\% while preserving confidence language in the AI-generated summaries. At the same time, AI summaries further compound the citation biases: Wikipedia and longer sources are disproportionately overrepresented, whereas cited social media content and negatively framed sources are substantially underrepresented. Our findings highlight the potential for \textit{answer bubbles}, in which identical queries yield structurally different information realities across systems, with implications for user trust, source visibility, and the transparency of AI-mediated information access.
Designing Beyond Language: Sociotechnical Barriers in AI Health Technologies for Limited English Proficiency
Nov 10, 2025



Limited English proficiency (LEP) patients in the U.S. face systemic barriers to healthcare beyond language and interpreter access, encompassing procedural and institutional constraints. AI advances may support communication and care through on-demand translation and visit preparation, but also risk exacerbating existing inequalities. We conducted storyboard-driven interviews with 14 patient navigators to explore how AI could shape care experiences for Spanish-speaking LEP individuals. We identified tensions around linguistic and cultural misunderstandings, privacy concerns, and opportunities and risks for AI to augment care workflows. Participants highlighted structural factors that can undermine trust in AI systems, including sensitive information disclosure, unstable technology access, and low digital literacy. While AI tools can potentially alleviate social barriers and institutional constraints, there are risks of misinformation and uprooting human camaraderie. Our findings contribute design considerations for AI that support LEP patients and care teams via rapport-building, education, and language support, and minimizing disruptions to existing practices.
Earnings-21: A Practical Benchmark for ASR in the Wild
Apr 28, 2021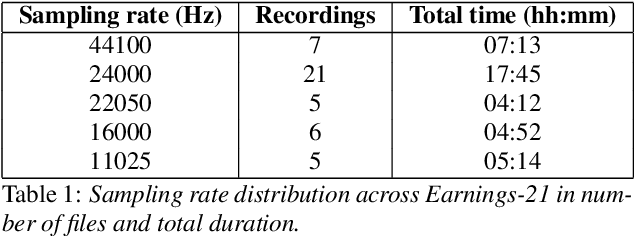
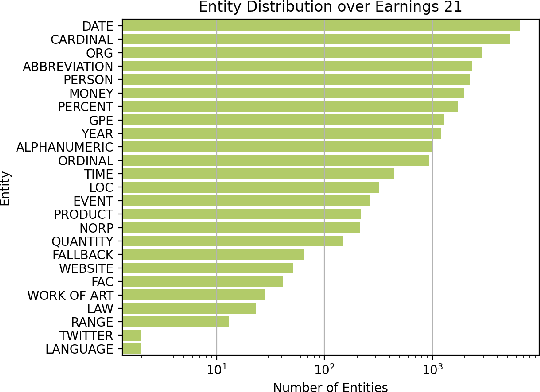
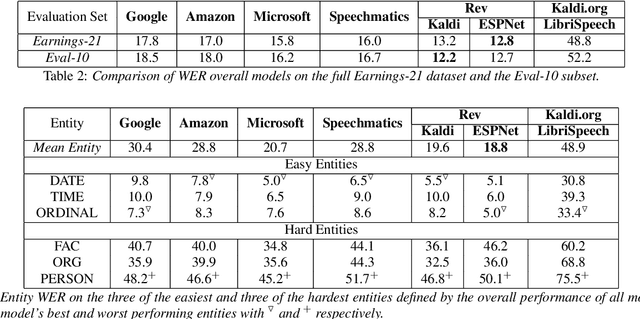
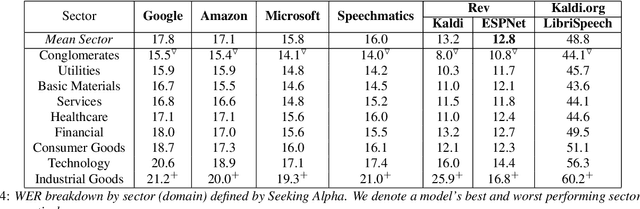
Commonly used speech corpora inadequately challenge academic and commercial ASR systems. In particular, speech corpora lack metadata needed for detailed analysis and WER measurement. In response, we present Earnings-21, a 39-hour corpus of earnings calls containing entity-dense speech from nine different financial sectors. This corpus is intended to benchmark ASR systems in the wild with special attention towards named entity recognition. We benchmark four commercial ASR models, two internal models built with open-source tools, and an open-source LibriSpeech model and discuss their differences in performance on Earnings-21. Using our recently released fstalign tool, we provide a candid analysis of each model's recognition capabilities under different partitions. Our analysis finds that ASR accuracy for certain NER categories is poor, presenting a significant impediment to transcript comprehension and usage. Earnings-21 bridges academic and commercial ASR system evaluation and enables further research on entity modeling and WER on real world audio.
Accented Speech Recognition: A Survey
Apr 21, 2021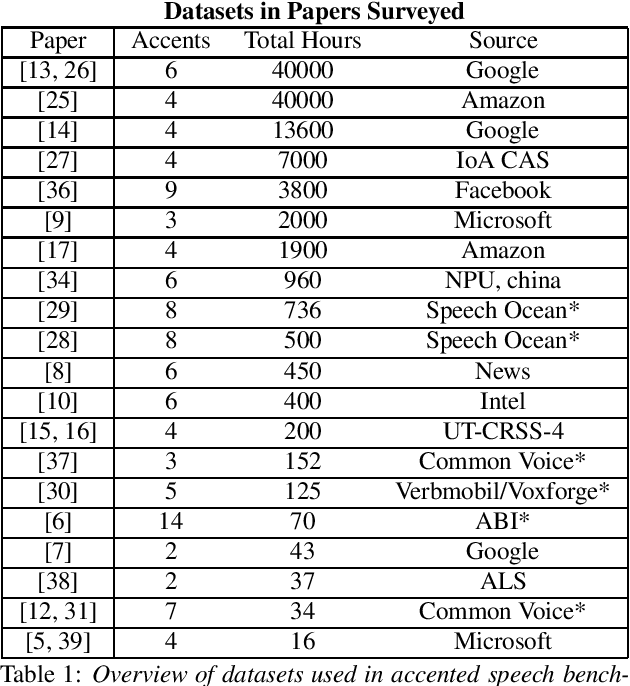
Automatic Speech Recognition (ASR) systems generalize poorly on accented speech. The phonetic and linguistic variability of accents present hard challenges for ASR systems today in both data collection and modeling strategies. The resulting bias in ASR performance across accents comes at a cost to both users and providers of ASR. We present a survey of current promising approaches to accented speech recognition and highlight the key challenges in the space. Approaches mostly focus on single model generalization and accent feature engineering. Among the challenges, lack of a standard benchmark makes research and comparison especially difficult.