 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Representation Learning for Exemplar-Guided Paraphrase Generation
Sep 03, 2021
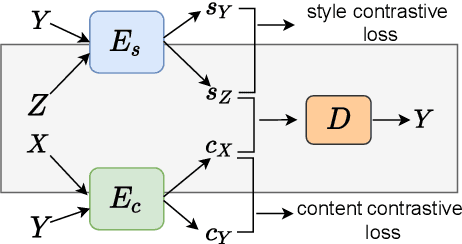
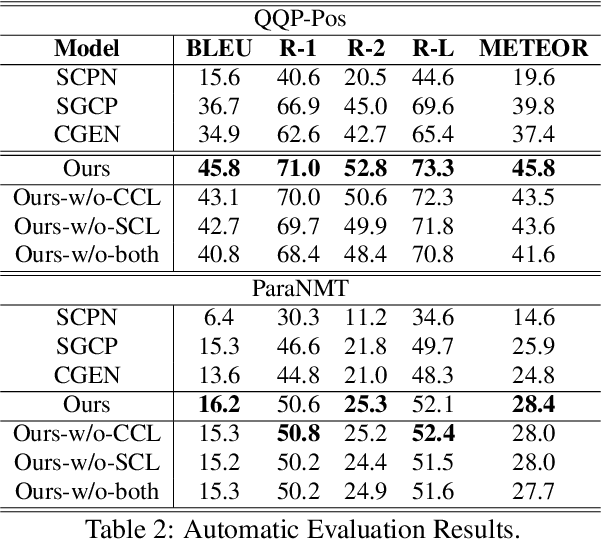
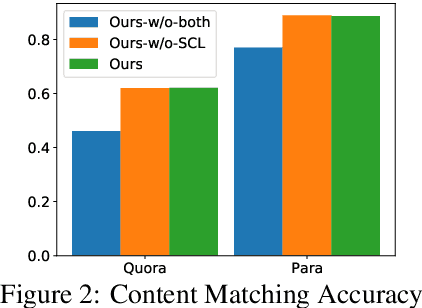
Exemplar-Guided Paraphrase Generation (EGPG) aims to generate a target sentence which conforms to the style of the given exemplar while encapsulating the content information of the source sentence. In this paper, we propose a new method with the goal of learning a better representation of the style andthe content. This method is mainly motivated by the recent success of contrastive learning which has demonstrated its power in unsupervised feature extraction tasks. The idea is to design two contrastive losses with respect to the content and the style by considering two problem characteristics during training. One characteristic is that the target sentence shares the same content with the source sentence, and the second characteristic is that the target sentence shares the same style with the exemplar. These two contrastive losses are incorporated into the general encoder-decoder paradigm. Experiments on two datasets, namely QQP-Pos and ParaNMT, demonstrate the effectiveness of our proposed constrastive losses.
Sentence Semantic Regression for Text Generation
Aug 06, 2021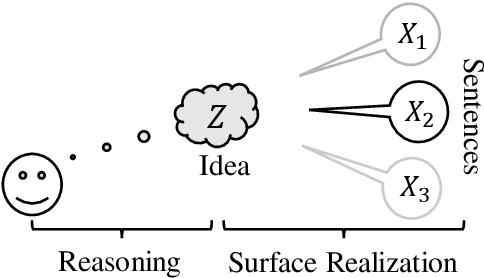
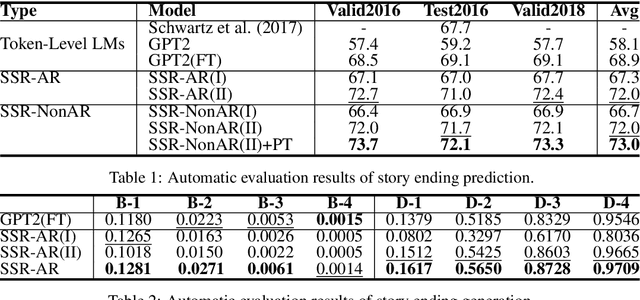
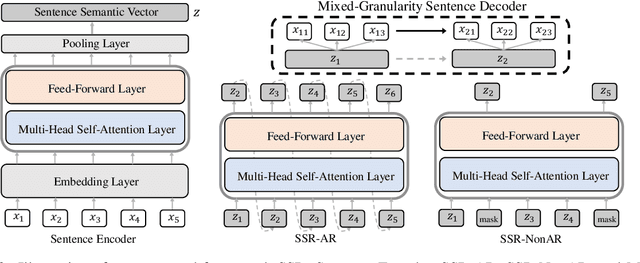
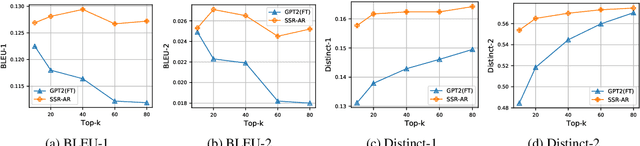
Recall the classical text generation works, the generation framework can be briefly divided into two phases: \textbf{idea reasoning} and \textbf{surface realization}. The target of idea reasoning is to figure out the main idea which will be presented in the following talking/writing periods. Surface realization aims to arrange the most appropriate sentence to depict and convey the information distilled from the main idea. However, the current popular token-by-token text generation methods ignore this crucial process and suffer from many serious issues, such as idea/topic drift. To tackle the problems and realize this two-phase paradigm, we propose a new framework named Sentence Semantic Regression (\textbf{SSR}) based on sentence-level language modeling. For idea reasoning, two architectures \textbf{SSR-AR} and \textbf{SSR-NonAR} are designed to conduct sentence semantic regression autoregressively (like GPT2/3) and bidirectionally (like BERT). In the phase of surface realization, a mixed-granularity sentence decoder is designed to generate text with better consistency by jointly incorporating the predicted sentence-level main idea as well as the preceding contextual token-level information. We conduct experiments on four tasks of story ending prediction, story ending generation, dialogue generation, and sentence infilling. The results show that SSR can obtain better performance in terms of automatic metrics and human evaluation.
Dialogue Summarization with Supporting Utterance Flow Modeling and Fact Regularization
Aug 03, 2021
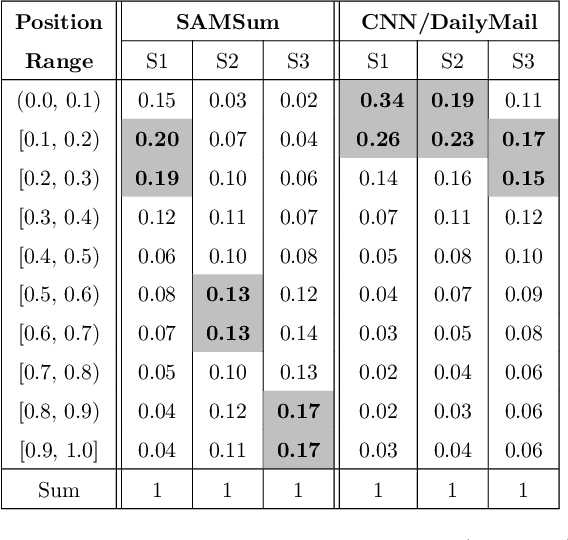
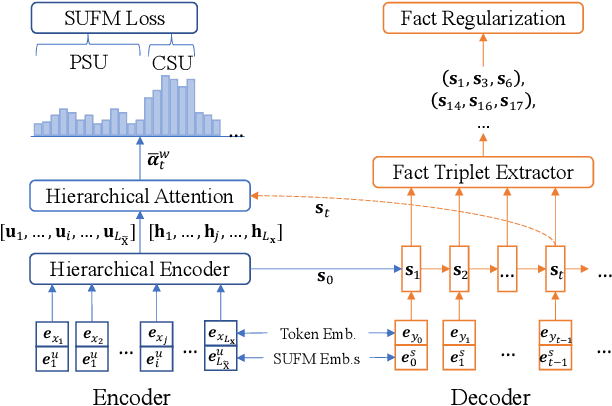
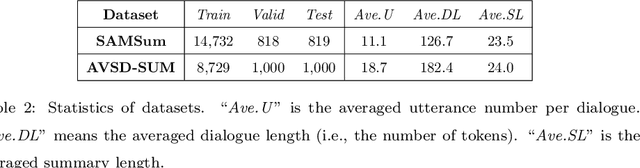
Dialogue summarization aims to generate a summary that indicates the key points of a given dialogue. In this work, we propose an end-to-end neural model for dialogue summarization with two novel modules, namely, the \emph{supporting utterance flow modeling module} and the \emph{fact regularization module}. The supporting utterance flow modeling helps to generate a coherent summary by smoothly shifting the focus from the former utterances to the later ones. The fact regularization encourages the generated summary to be factually consistent with the ground-truth summary during model training, which helps to improve the factual correctness of the generated summary in inference time. Furthermore, we also introduce a new benchmark dataset for dialogue summarization. Extensive experiments on both existing and newly-introduced datasets demonstrate the effectiveness of our model.
CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
Jul 01, 2021
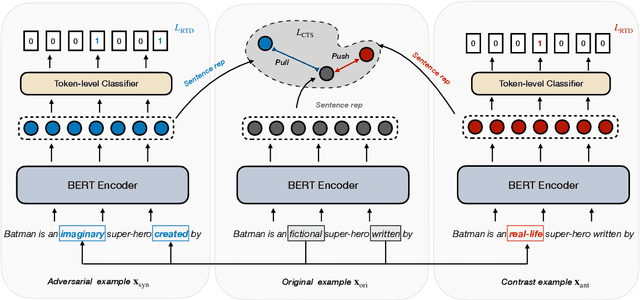
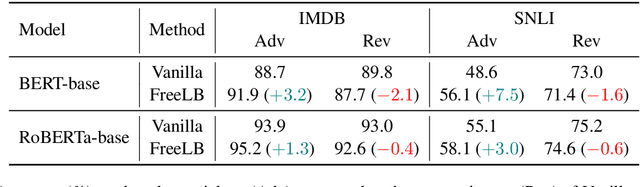

Despite pre-trained language models have proven useful for learning high-quality semantic representations, these models are still vulnerable to simple perturbations. Recent works aimed to improve the robustness of pre-trained models mainly focus on adversarial training from perturbed examples with similar semantics, neglecting the utilization of different or even opposite semantics. Different from the image processing field, the text is discrete and few word substitutions can cause significant semantic changes. To study the impact of semantics caused by small perturbations, we conduct a series of pilot experiments and surprisingly find that adversarial training is useless or even harmful for the model to detect these semantic changes. To address this problem, we propose Contrastive Learning with semantIc Negative Examples (CLINE), which constructs semantic negative examples unsupervised to improve the robustness under semantically adversarial attacking. By comparing with similar and opposite semantic examples, the model can effectively perceive the semantic changes caused by small perturbations. Empirical results show that our approach yields substantial improvements on a range of sentiment analysis, reasoning, and reading comprehension tasks. And CLINE also ensures the compactness within the same semantics and separability across different semantics in sentence-level.
A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy
Jun 26, 2021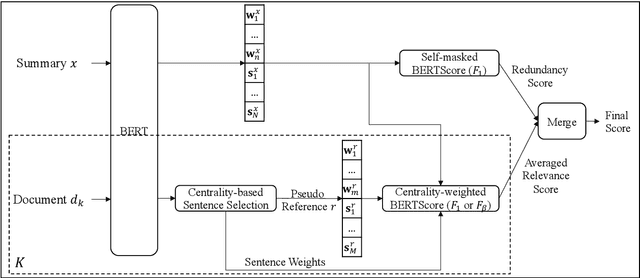
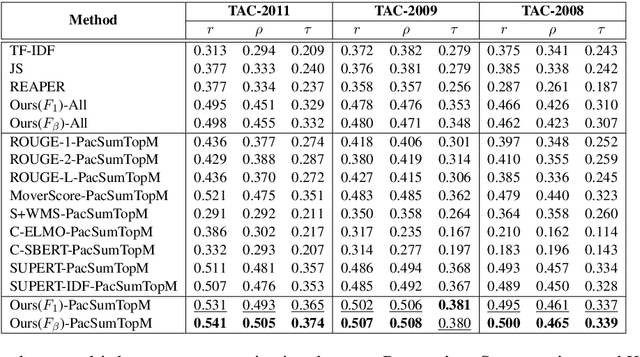
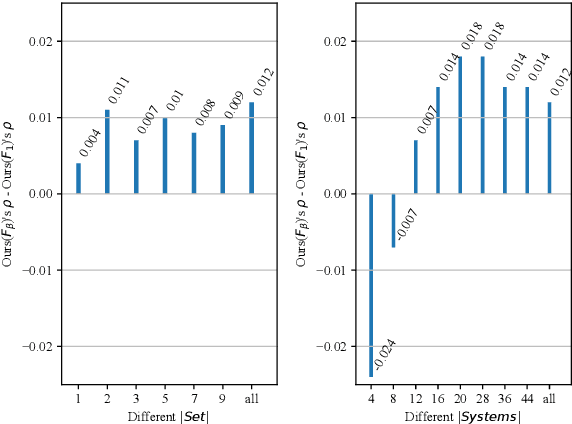
In recent years, reference-based and supervised summarization evaluation metrics have been widely explored. However, collecting human-annotated references and ratings are costly and time-consuming. To avoid these limitations, we propose a training-free and reference-free summarization evaluation metric. Our metric consists of a centrality-weighted relevance score and a self-referenced redundancy score. The relevance score is computed between the pseudo reference built from the source document and the given summary, where the pseudo reference content is weighted by the sentence centrality to provide importance guidance. Besides an $F_1$-based relevance score, we also design an $F_\beta$-based variant that pays more attention to the recall score. As for the redundancy score of the summary, we compute a self-masked similarity score with the summary itself to evaluate the redundant information in the summary. Finally, we combine the relevance and redundancy scores to produce the final evaluation score of the given summary. Extensive experiments show that our methods can significantly outperform existing methods on both multi-document and single-document summarization evaluation.
Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction
Jun 20, 2021
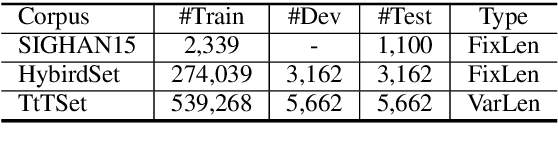

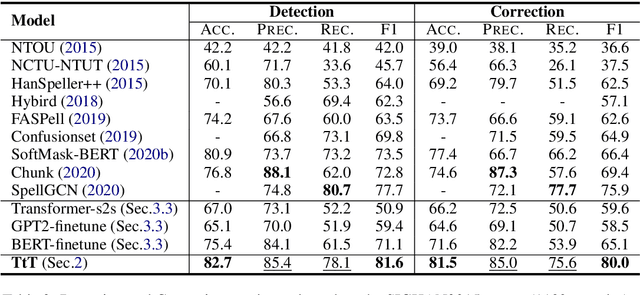
We investigate the problem of Chinese Grammatical Error Correction (CGEC) and present a new framework named Tail-to-Tail (\textbf{TtT}) non-autoregressive sequence prediction to address the deep issues hidden in CGEC. Considering that most tokens are correct and can be conveyed directly from source to target, and the error positions can be estimated and corrected based on the bidirectional context information, thus we employ a BERT-initialized Transformer Encoder as the backbone model to conduct information modeling and conveying. Considering that only relying on the same position substitution cannot handle the variable-length correction cases, various operations such substitution, deletion, insertion, and local paraphrasing are required jointly. Therefore, a Conditional Random Fields (CRF) layer is stacked on the up tail to conduct non-autoregressive sequence prediction by modeling the token dependencies. Since most tokens are correct and easily to be predicted/conveyed to the target, then the models may suffer from a severe class imbalance issue. To alleviate this problem, focal loss penalty strategies are integrated into the loss functions. Moreover, besides the typical fix-length error correction datasets, we also construct a variable-length corpus to conduct experiments. Experimental results on standard datasets, especially on the variable-length datasets, demonstrate the effectiveness of TtT in terms of sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of error Detection and Correction.
Non-Autoregressive Text Generation with Pre-trained Language Models
Feb 16, 2021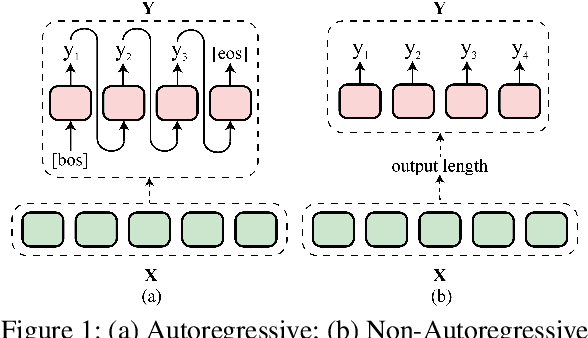
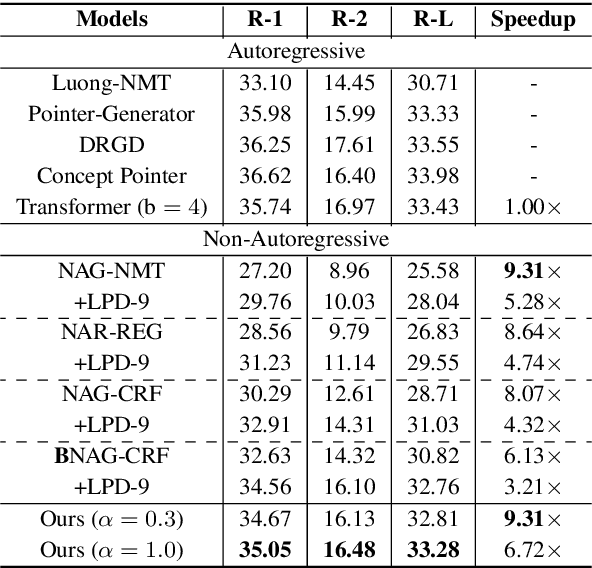
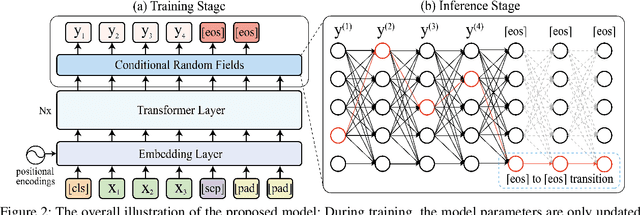
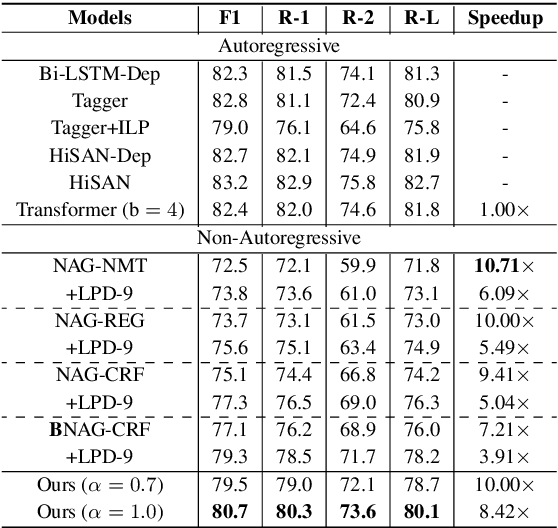
Non-autoregressive generation (NAG) has recently attracted great attention due to its fast inference speed. However, the generation quality of existing NAG models still lags behind their autoregressive counterparts. In this work, we show that BERT can be employed as the backbone of a NAG model to greatly improve performance. Additionally, we devise mechanisms to alleviate the two common problems of vanilla NAG models: the inflexibility of prefixed output length and the conditional independence of individual token predictions. Lastly, to further increase the speed advantage of the proposed model, we propose a new decoding strategy, ratio-first, for applications where the output lengths can be approximately estimated beforehand. For a comprehensive evaluation, we test the proposed model on three text generation tasks, including text summarization, sentence compression and machine translation. Experimental results show that our model significantly outperforms existing non-autoregressive baselines and achieves competitive performance with many strong autoregressive models. In addition, we also conduct extensive analysis experiments to reveal the effect of each proposed component.
Generating Diversified Comments via Reader-Aware Topic Modeling and Saliency Detection
Feb 13, 2021
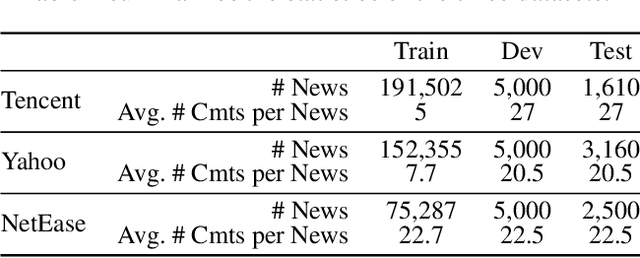
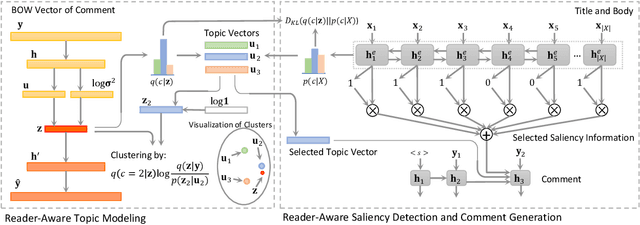
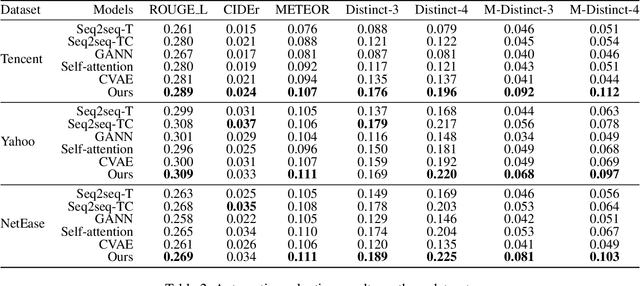
Automatic comment generation is a special and challenging task to verify the model ability on news content comprehension and language generation. Comments not only convey salient and interesting information in news articles, but also imply various and different reader characteristics which we treat as the essential clues for diversity. However, most of the comment generation approaches only focus on saliency information extraction, while the reader-aware factors implied by comments are neglected. To address this issue, we propose a unified reader-aware topic modeling and saliency information detection framework to enhance the quality of generated comments. For reader-aware topic modeling, we design a variational generative clustering algorithm for latent semantic learning and topic mining from reader comments. For saliency information detection, we introduce Bernoulli distribution estimating on news content to select saliency information. The obtained topic representations as well as the selected saliency information are incorporated into the decoder to generate diversified and informative comments. Experimental results on three datasets show that our framework outperforms existing baseline methods in terms of both automatic metrics and human evaluation. The potential ethical issues are also discussed in detail.
Abstractive Opinion Tagging
Jan 24, 2021
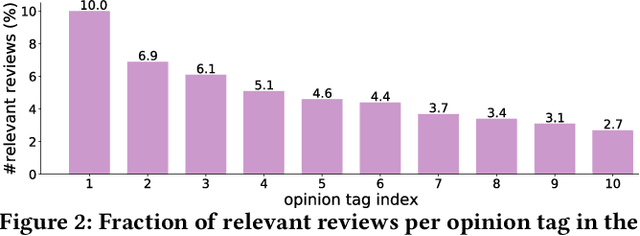
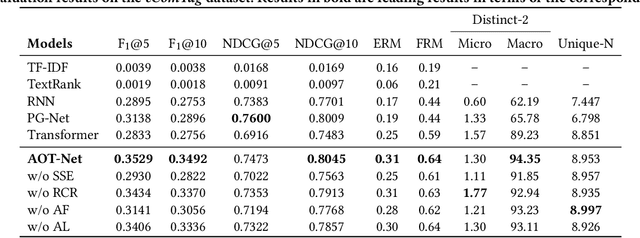
In e-commerce, opinion tags refer to a ranked list of tags provided by the e-commerce platform that reflect characteristics of reviews of an item. To assist consumers to quickly grasp a large number of reviews about an item, opinion tags are increasingly being applied by e-commerce platforms. Current mechanisms for generating opinion tags rely on either manual labelling or heuristic methods, which is time-consuming and ineffective. In this paper, we propose the abstractive opinion tagging task, where systems have to automatically generate a ranked list of opinion tags that are based on, but need not occur in, a given set of user-generated reviews. The abstractive opinion tagging task comes with three main challenges: (1) the noisy nature of reviews; (2) the formal nature of opinion tags vs. the colloquial language usage in reviews; and (3) the need to distinguish between different items with very similar aspects. To address these challenges, we propose an abstractive opinion tagging framework, named AOT-Net, to generate a ranked list of opinion tags given a large number of reviews. First, a sentence-level salience estimation component estimates each review's salience score. Next, a review clustering and ranking component ranks reviews in two steps: first, reviews are grouped into clusters and ranked by cluster size; then, reviews within each cluster are ranked by their distance to the cluster center. Finally, given the ranked reviews, a rank-aware opinion tagging component incorporates an alignment feature and alignment loss to generate a ranked list of opinion tags. To facilitate the study of this task, we create and release a large-scale dataset, called eComTag, crawled from real-world e-commerce websites. Extensive experiments conducted on the eComTag dataset verify the effectiveness of the proposed AOT-Net in terms of various evaluation metrics.
Predicting Events in MOBA Games: Dataset, Attribution, and Evaluation
Dec 24, 2020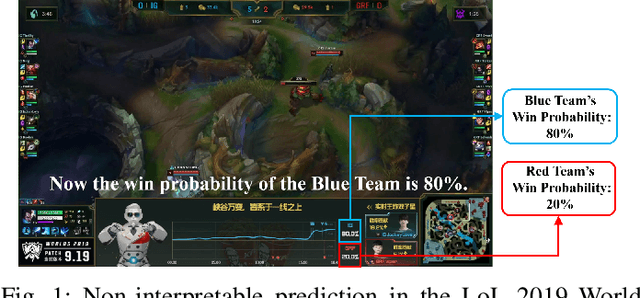
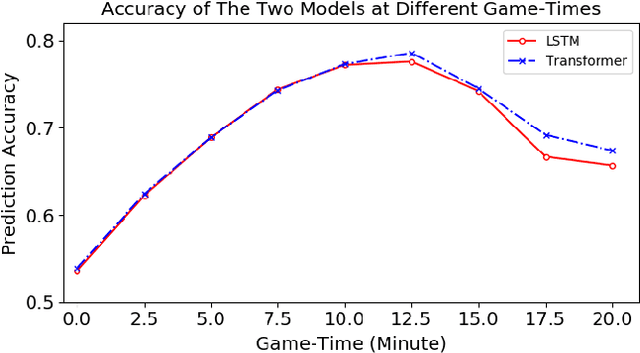
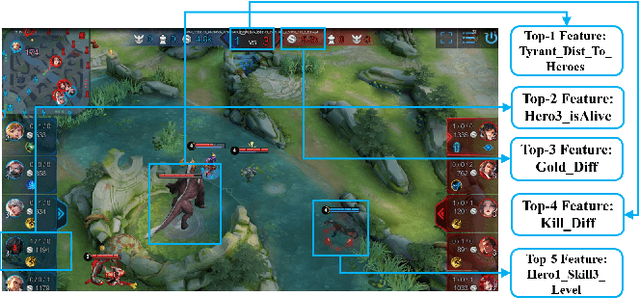
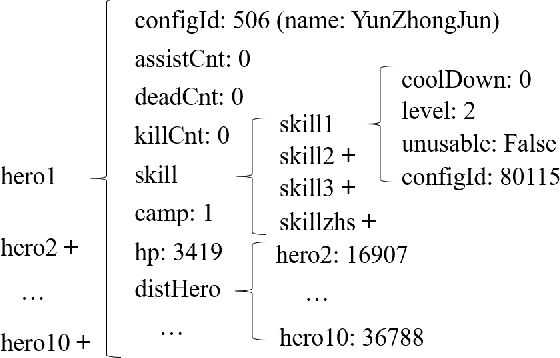
The multiplayer online battle arena (MOBA) games have become increasingly popular in recent years. Consequently, many efforts have been devoted to providing pre-game or in-game predictions for them. However, these works are limited in the following two aspects: 1) the lack of sufficient in-game features; 2) the absence of interpretability in the prediction results. These two limitations greatly restrict the practical performance and industrial application of the current works. In this work, we collect and release a large-scale dataset containing rich in-game features for the popular MOBA game Honor of Kings. We then propose to predict four types of important events in an interpretable way by attributing the predictions to the input features using two gradient-based attribution methods: Integrated Gradients and SmoothGrad. To evaluate the explanatory power of different models and attribution methods, a fidelity-based evaluation metric is further proposed. Finally, we evaluate the accuracy and Fidelity of several competitive methods on the collected dataset to assess how well machines predict events in MOBA games.