 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPEn: An Open-ended Physics Environment for Learning Without a Task
Oct 13, 2021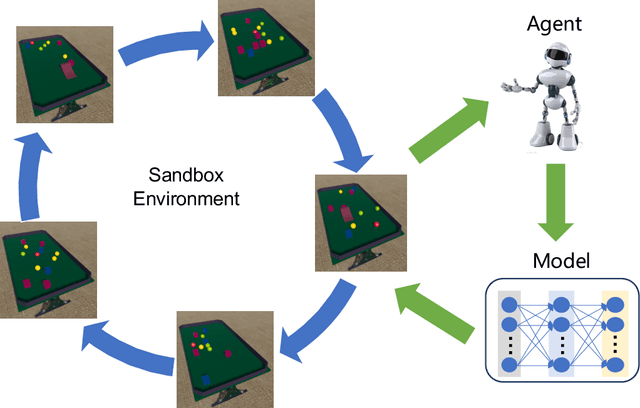
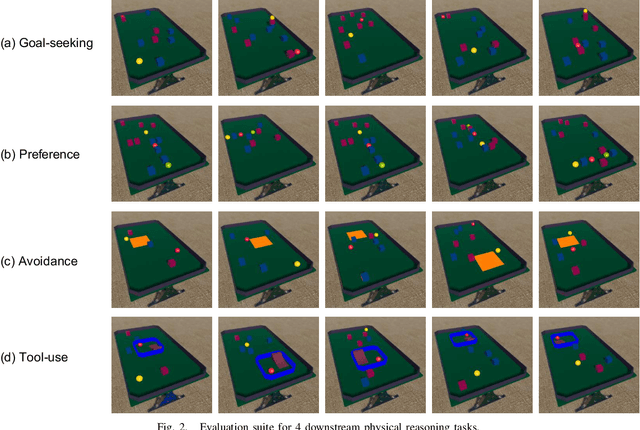
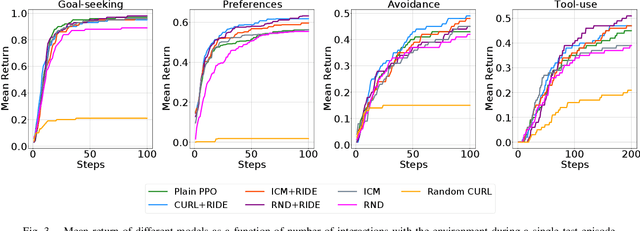
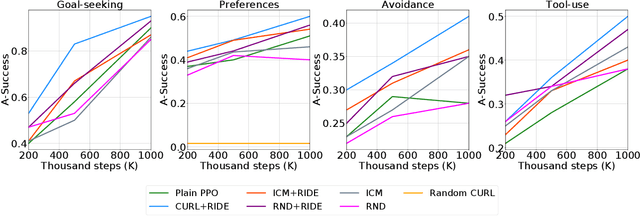
Humans have mental models that allow them to plan, experiment, and reason in the physical world. How should an intelligent agent go about learning such models? In this paper, we will study if models of the world learned in an open-ended physics environment, without any specific tasks, can be reused for downstream physics reasoning tasks. To this end, we build a benchmark Open-ended Physics ENvironment (OPEn) and also design several tasks to test learning representations in this environment explicitly. This setting reflects the conditions in which real agents (i.e. rolling robots) find themselves, where they may be placed in a new kind of environment and must adapt without any teacher to tell them how this environment works. This setting is challenging because it requires solving an exploration problem in addition to a model building and representation learning problem. We test several existing RL-based exploration methods on this benchmark and find that an agent using unsupervised contrastive learning for representation learning, and impact-driven learning for exploration, achieved the best results. However, all models still fall short in sample efficiency when transferring to the downstream tasks. We expect that OPEn will encourage the development of novel rolling robot agents that can build reusable mental models of the world that facilitate many tasks.
Adaptable Agent Populations via a Generative Model of Policies
Jul 15, 2021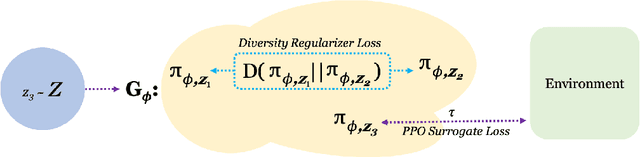
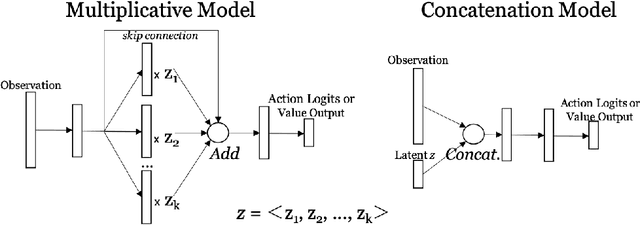

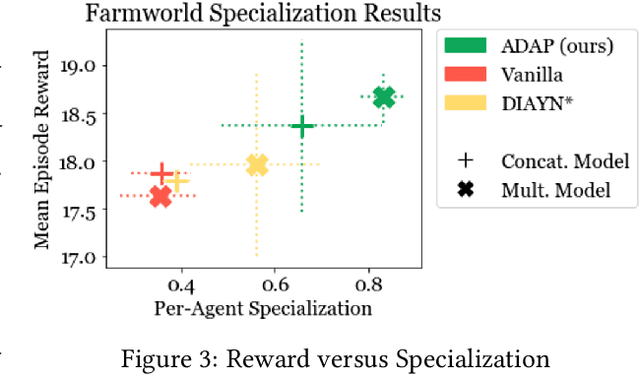
In the natural world, life has found innumerable ways to survive and often thrive. Between and even within species, each individual is in some manner unique, and this diversity lends adaptability and robustness to life. In this work, we aim to learn a space of diverse and high-reward policies on any given environment. To this end, we introduce a generative model of policies, which maps a low-dimensional latent space to an agent policy space. Our method enables learning an entire population of agent policies, without requiring the use of separate policy parameters. Just as real world populations can adapt and evolve via natural selection, our method is able to adapt to changes in our environment solely by selecting for policies in latent space. We test our generative model's capabilities in a variety of environments, including an open-ended grid-world and a two-player soccer environment. Code, visualizations, and additional experiments can be found at https://kennyderek.github.io/adap/.
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Jul 01, 2021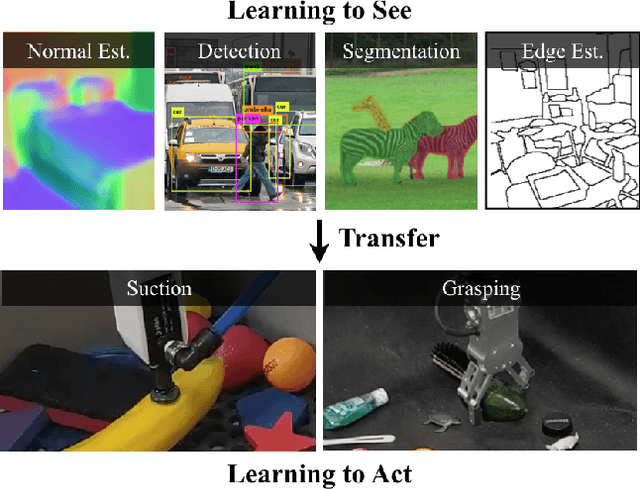

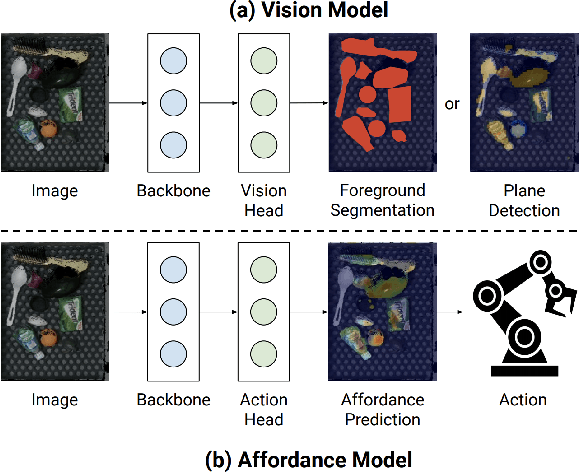

Does having visual priors (e.g. the ability to detect objects) facilitate learning to perform vision-based manipulation (e.g. picking up objects)? We study this problem under the framework of transfer learning, where the model is first trained on a passive vision task, and adapted to perform an active manipulation task. We find that pre-training on vision tasks significantly improves generalization and sample efficiency for learning to manipulate objects. However, realizing these gains requires careful selection of which parts of the model to transfer. Our key insight is that outputs of standard vision models highly correlate with affordance maps commonly used in manipulation. Therefore, we explore directly transferring model parameters from vision networks to affordance prediction networks, and show that this can result in successful zero-shot adaptation, where a robot can pick up certain objects with zero robotic experience. With just a small amount of robotic experience, we can further fine-tune the affordance model to achieve better results. With just 10 minutes of suction experience or 1 hour of grasping experience, our method achieves ~80% success rate at picking up novel objects.
Learning to See by Looking at Noise
Jun 10, 2021
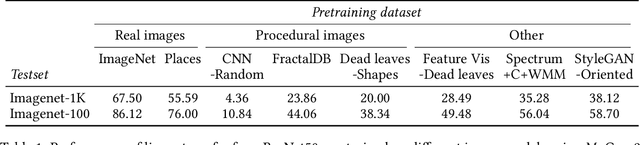

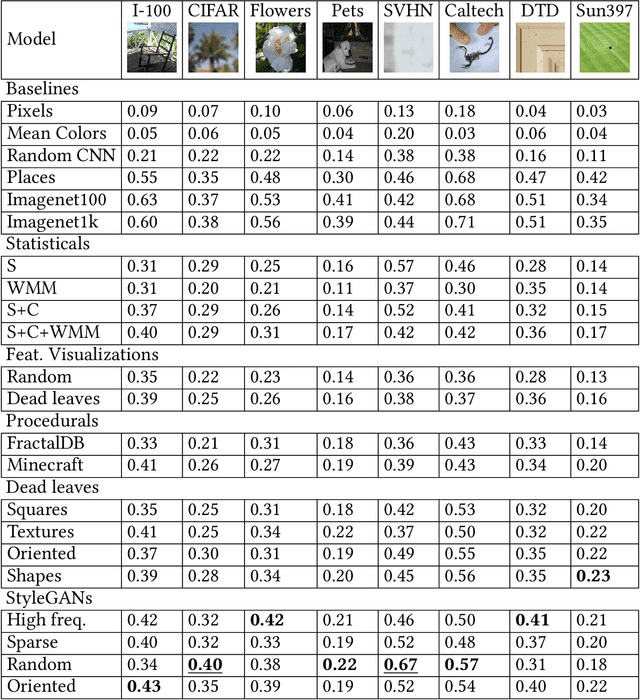
Current vision systems are trained on huge datasets, and these datasets come with costs: curation is expensive, they inherit human biases, and there are concerns over privacy and usage rights. To counter these costs, interest has surged in learning from cheaper data sources, such as unlabeled images. In this paper we go a step further and ask if we can do away with real image datasets entirely, instead learning from noise processes. We investigate a suite of image generation models that produce images from simple random processes. These are then used as training data for a visual representation learner with a contrastive loss. We study two types of noise processes, statistical image models and deep generative models under different random initializations. Our findings show that it is important for the noise to capture certain structural properties of real data but that good performance can be achieved even with processes that are far from realistic. We also find that diversity is a key property to learn good representations. Datasets, models, and code are available at https://mbaradad.github.io/learning_with_noise.
Generative Models as a Data Source for Multiview Representation Learning
Jun 09, 2021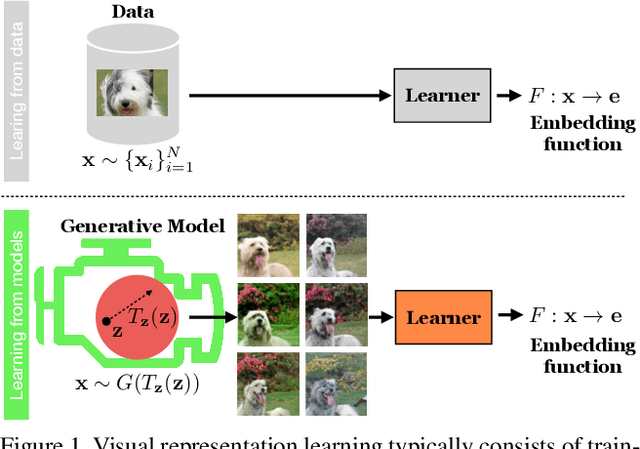
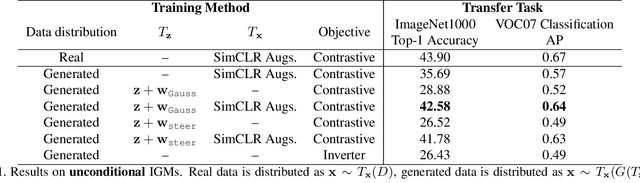
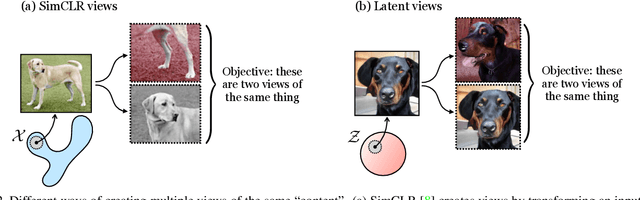
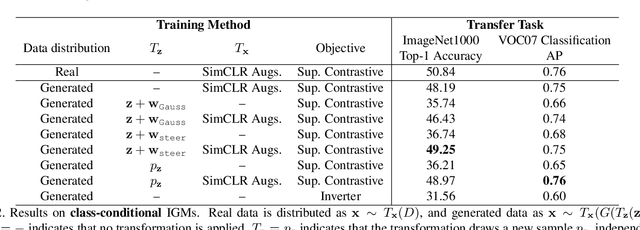
Generative models are now capable of producing highly realistic images that look nearly indistinguishable from the data on which they are trained. This raises the question: if we have good enough generative models, do we still need datasets? We investigate this question in the setting of learning general-purpose visual representations from a black-box generative model rather than directly from data. Given an off-the-shelf image generator without any access to its training data, we train representations from the samples output by this generator. We compare several representation learning methods that can be applied to this setting, using the latent space of the generator to generate multiple "views" of the same semantic content. We show that for contrastive methods, this multiview data can naturally be used to identify positive pairs (nearby in latent space) and negative pairs (far apart in latent space). We find that the resulting representations rival those learned directly from real data, but that good performance requires care in the sampling strategy applied and the training method. Generative models can be viewed as a compressed and organized copy of a dataset, and we envision a future where more and more "model zoos" proliferate while datasets become increasingly unwieldy, missing, or private. This paper suggests several techniques for dealing with visual representation learning in such a future. Code is released on our project page: https://ali-design.github.io/GenRep/
Curious Representation Learning for Embodied Intelligence
May 03, 2021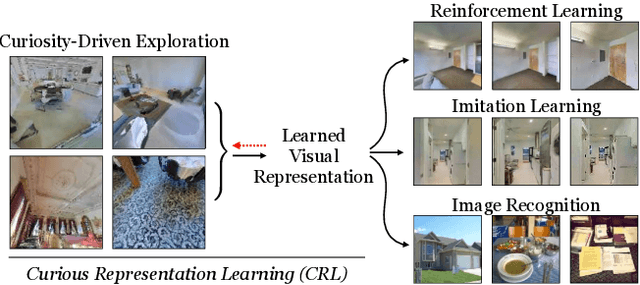
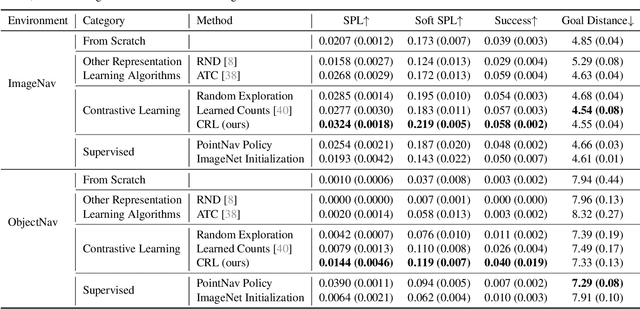
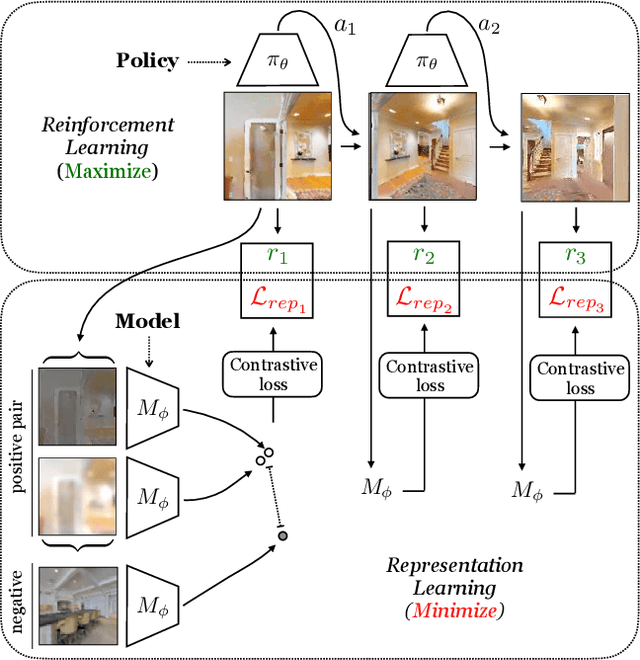

Self-supervised representation learning has achieved remarkable success in recent years. By subverting the need for supervised labels, such approaches are able to utilize the numerous unlabeled images that exist on the Internet and in photographic datasets. Yet to build truly intelligent agents, we must construct representation learning algorithms that can learn not only from datasets but also learn from environments. An agent in a natural environment will not typically be fed curated data. Instead, it must explore its environment to acquire the data it will learn from. We propose a framework, curious representation learning (CRL), which jointly learns a reinforcement learning policy and a visual representation model. The policy is trained to maximize the error of the representation learner, and in doing so is incentivized to explore its environment. At the same time, the learned representation becomes stronger and stronger as the policy feeds it ever harder data to learn from. Our learned representations enable promising transfer to downstream navigation tasks, performing better than or comparably to ImageNet pretraining without using any supervision at all. In addition, despite being trained in simulation, our learned representations can obtain interpretable results on real images.
Ensembling with Deep Generative Views
Apr 29, 2021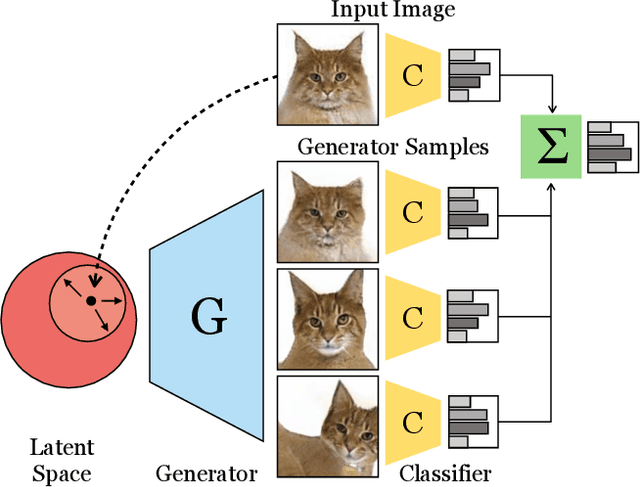
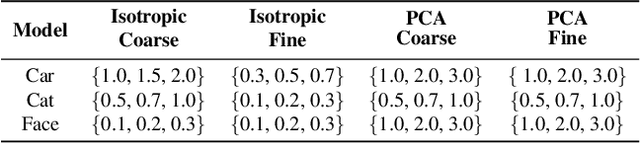

Recent generative models can synthesize "views" of artificial images that mimic real-world variations, such as changes in color or pose, simply by learning from unlabeled image collections. Here, we investigate whether such views can be applied to real images to benefit downstream analysis tasks such as image classification. Using a pretrained generator, we first find the latent code corresponding to a given real input image. Applying perturbations to the code creates natural variations of the image, which can then be ensembled together at test-time. We use StyleGAN2 as the source of generative augmentations and investigate this setup on classification tasks involving facial attributes, cat faces, and cars. Critically, we find that several design decisions are required towards making this process work; the perturbation procedure, weighting between the augmentations and original image, and training the classifier on synthesized images can all impact the result. Currently, we find that while test-time ensembling with GAN-based augmentations can offer some small improvements, the remaining bottlenecks are the efficiency and accuracy of the GAN reconstructions, coupled with classifier sensitivities to artifacts in GAN-generated images.
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021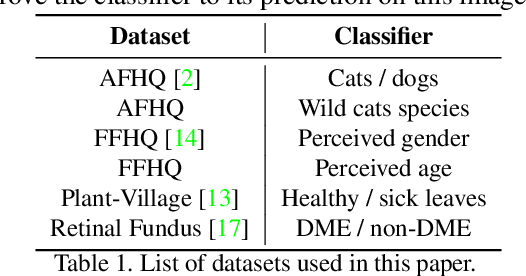
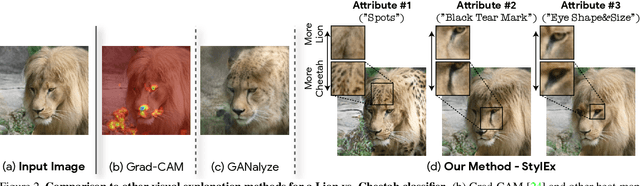
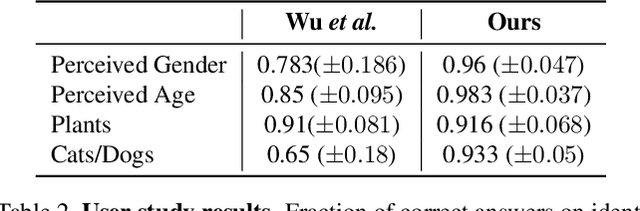
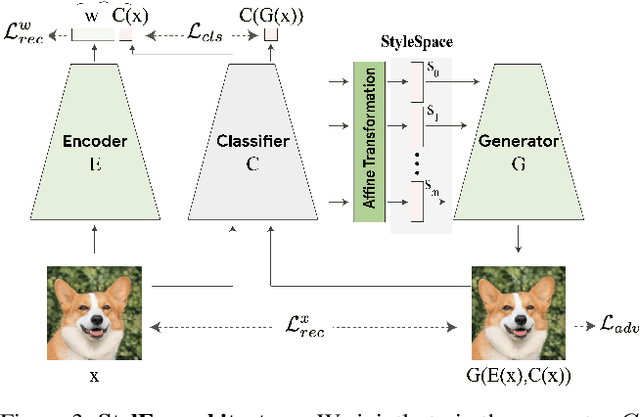
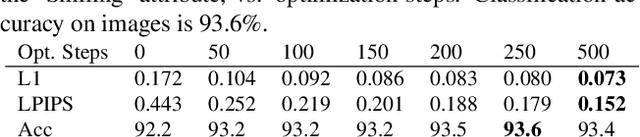
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
The Low-Rank Simplicity Bias in Deep Networks
Mar 18, 2021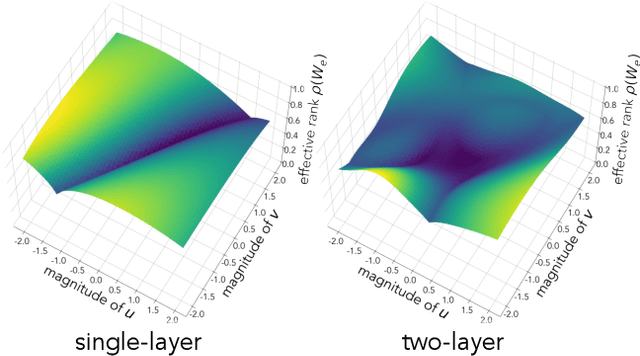
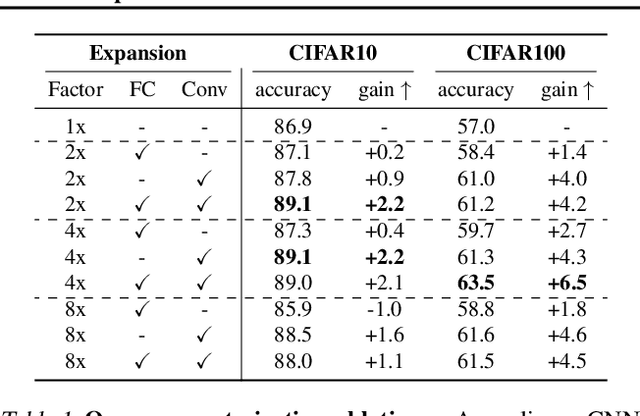
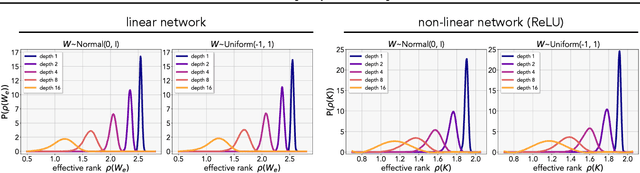
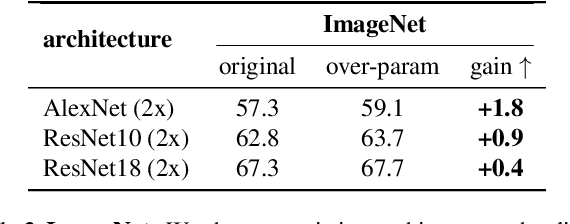
Modern deep neural networks are highly over-parameterized compared to the data on which they are trained, yet they often generalize remarkably well. A flurry of recent work has asked: why do deep networks not overfit to their training data? We investigate the hypothesis that deeper nets are implicitly biased to find lower rank solutions and that these are the solutions that generalize well. We prove for the asymptotic case that the percent volume of low effective-rank solutions increases monotonically as linear neural networks are made deeper. We then show empirically that our claim holds true on finite width models. We further empirically find that a similar result holds for non-linear networks: deeper non-linear networks learn a feature space whose kernel has a lower rank. We further demonstrate how linear over-parameterization of deep non-linear models can be used to induce low-rank bias, improving generalization performance without changing the effective model capacity. We evaluate on various model architectures and demonstrate that linearly over-parameterized models outperform existing baselines on image classification tasks, including ImageNet.
Using latent space regression to analyze and leverage compositionality in GANs
Mar 18, 2021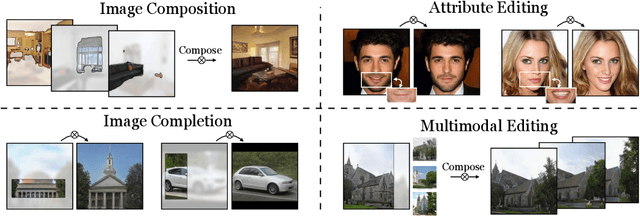



In recent years, Generative Adversarial Networks have become ubiquitous in both research and public perception, but how GANs convert an unstructured latent code to a high quality output is still an open question. In this work, we investigate regression into the latent space as a probe to understand the compositional properties of GANs. We find that combining the regressor and a pretrained generator provides a strong image prior, allowing us to create composite images from a collage of random image parts at inference time while maintaining global consistency. To compare compositional properties across different generators, we measure the trade-offs between reconstruction of the unrealistic input and image quality of the regenerated samples. We find that the regression approach enables more localized editing of individual image parts compared to direct editing in the latent space, and we conduct experiments to quantify this independence effect. Our method is agnostic to the semantics of edits, and does not require labels or predefined concepts during training. Beyond image composition, our method extends to a number of related applications, such as image inpainting or example-based image editing, which we demonstrate on several GANs and datasets, and because it uses only a single forward pass, it can operate in real-time. Code is available on our project page: https://chail.github.io/latent-composition/.