 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn To Pay Attention
Apr 26, 2018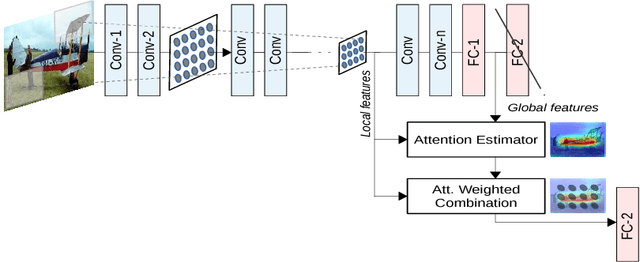
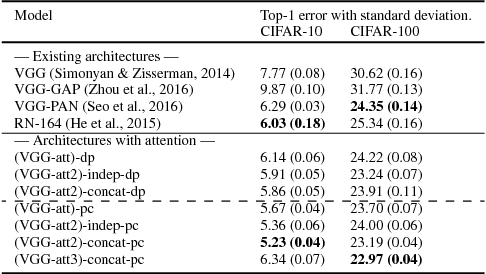
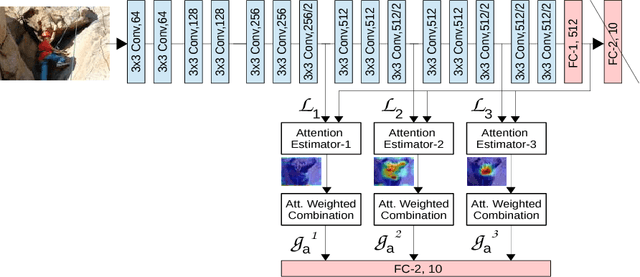
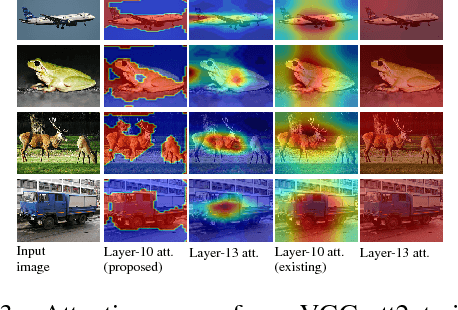
We propose an end-to-end-trainable attention module for convolutional neural network (CNN) architectures built for image classification. The module takes as input the 2D feature vector maps which form the intermediate representations of the input image at different stages in the CNN pipeline, and outputs a 2D matrix of scores for each map. Standard CNN architectures are modified through the incorporation of this module, and trained under the constraint that a convex combination of the intermediate 2D feature vectors, as parameterised by the score matrices, must \textit{alone} be used for classification. Incentivised to amplify the relevant and suppress the irrelevant or misleading, the scores thus assume the role of attention values. Our experimental observations provide clear evidence to this effect: the learned attention maps neatly highlight the regions of interest while suppressing background clutter. Consequently, the proposed function is able to bootstrap standard CNN architectures for the task of image classification, demonstrating superior generalisation over 6 unseen benchmark datasets. When binarised, our attention maps outperform other CNN-based attention maps, traditional saliency maps, and top object proposals for weakly supervised segmentation as demonstrated on the Object Discovery dataset. We also demonstrate improved robustness against the fast gradient sign method of adversarial attack.
DGPose: Disentangled Semi-supervised Deep Generative Models for Human Body Analysis
Apr 17, 2018
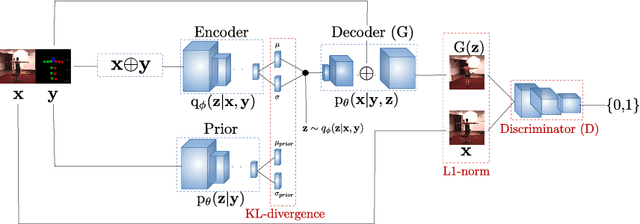
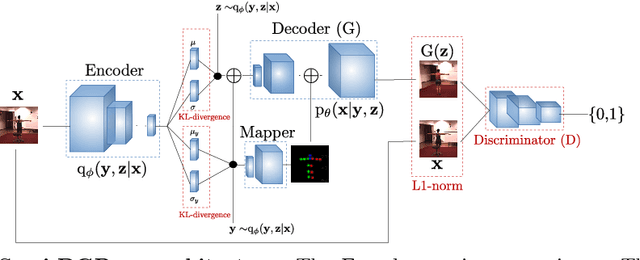
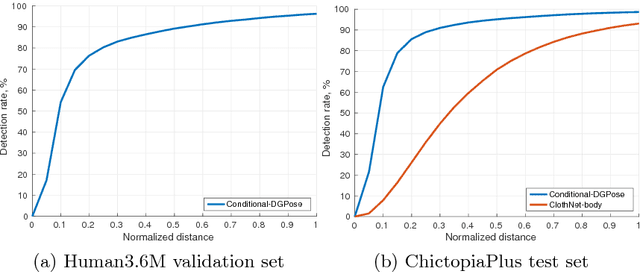
Deep generative modelling for robust human body analysis is an emerging problem with many interesting applications, since it enables analysis-by-synthesis and unsupervised learning. However, the latent space learned by such models is typically not human-interpretable, resulting in less flexible models. In this work, we adopt a structured semi-supervised variational auto-encoder approach and present a deep generative model for human body analysis where the pose and appearance are disentangled in the latent space, allowing for pose estimation. Such a disentanglement allows independent manipulation of pose and appearance and hence enables applications such as pose-transfer without being explicitly trained for such a task. In addition, the ability to train in a semi-supervised setting relaxes the need for labelled data. We demonstrate the merits of our generative model on the Human3.6M and ChictopiaPlus datasets.
FlipDial: A Generative Model for Two-Way Visual Dialogue
Apr 03, 2018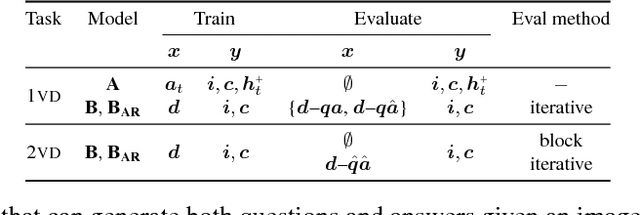
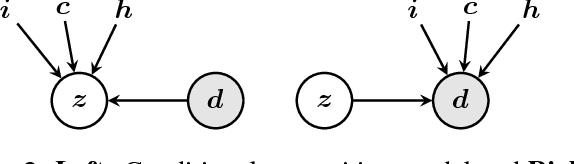
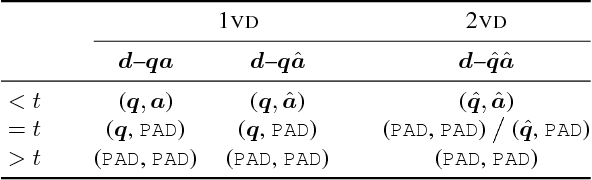
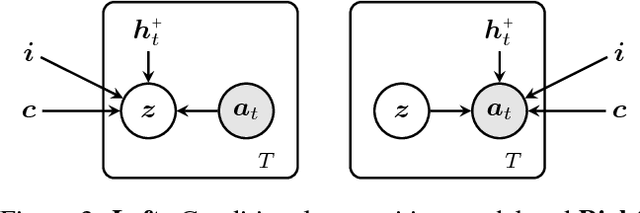
We present FlipDial, a generative model for visual dialogue that simultaneously plays the role of both participants in a visually-grounded dialogue. Given context in the form of an image and an associated caption summarising the contents of the image, FlipDial learns both to answer questions and put forward questions, capable of generating entire sequences of dialogue (question-answer pairs) which are diverse and relevant to the image. To do this, FlipDial relies on a simple but surprisingly powerful idea: it uses convolutional neural networks (CNNs) to encode entire dialogues directly, implicitly capturing dialogue context, and conditional VAEs to learn the generative model. FlipDial outperforms the state-of-the-art model in the sequential answering task (one-way visual dialogue) on the VisDial dataset by 5 points in Mean Rank using the generated answers. We are the first to extend this paradigm to full two-way visual dialogue, where our model is capable of generating both questions and answers in sequence based on a visual input, for which we propose a set of novel evaluation measures and metrics.
Learning to Compare: Relation Network for Few-Shot Learning
Mar 27, 2018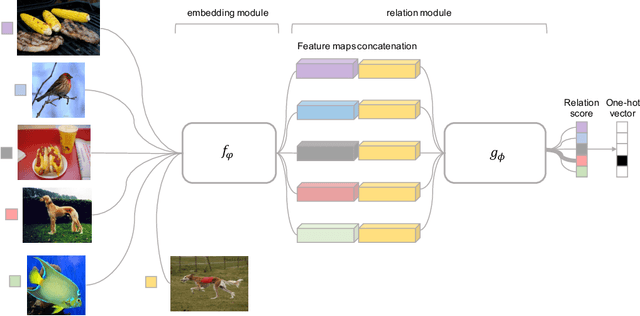
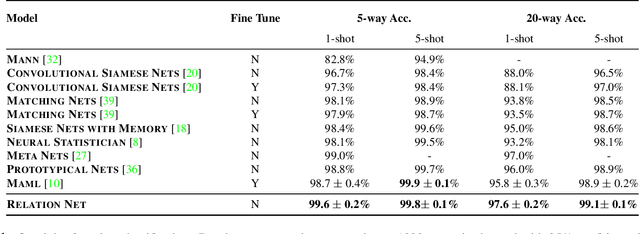
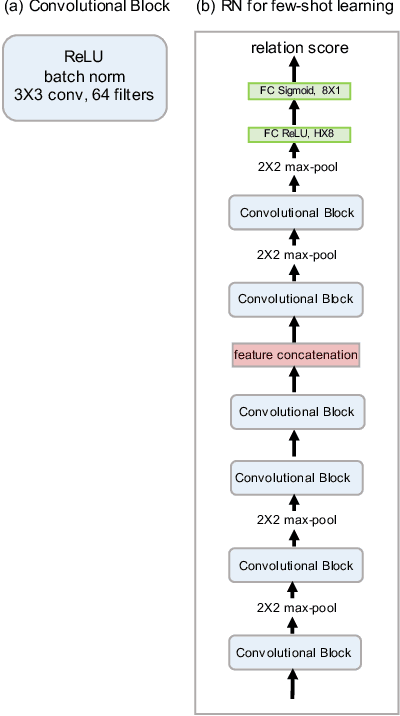
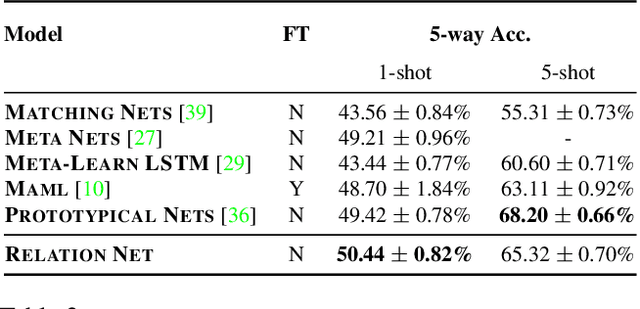
We present a conceptually simple, flexible, and general framework for few-shot learning, where a classifier must learn to recognise new classes given only few examples from each. Our method, called the Relation Network (RN), is trained end-to-end from scratch. During meta-learning, it learns to learn a deep distance metric to compare a small number of images within episodes, each of which is designed to simulate the few-shot setting. Once trained, a RN is able to classify images of new classes by computing relation scores between query images and the few examples of each new class without further updating the network. Besides providing improved performance on few-shot learning, our framework is easily extended to zero-shot learning. Extensive experiments on five benchmarks demonstrate that our simple approach provides a unified and effective approach for both of these two tasks.
Three Birds One Stone: A Unified Framework for Salient Object Segmentation, Edge Detection and Skeleton Extraction
Mar 27, 2018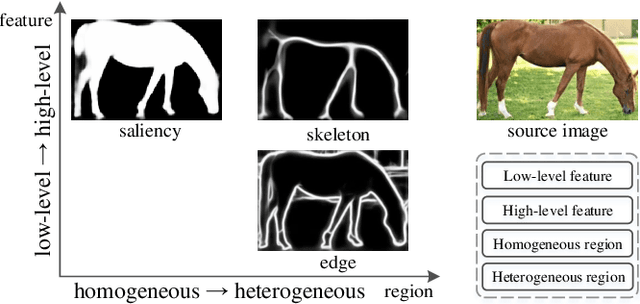
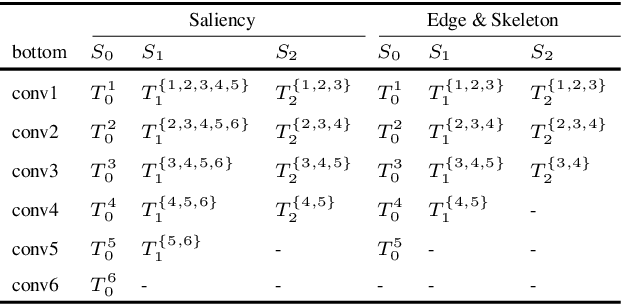
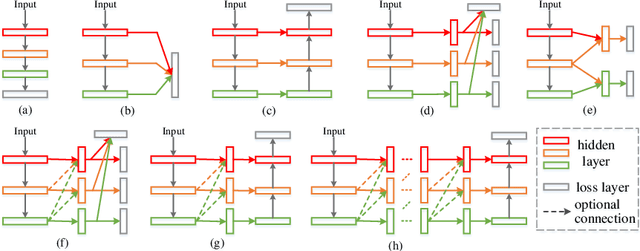
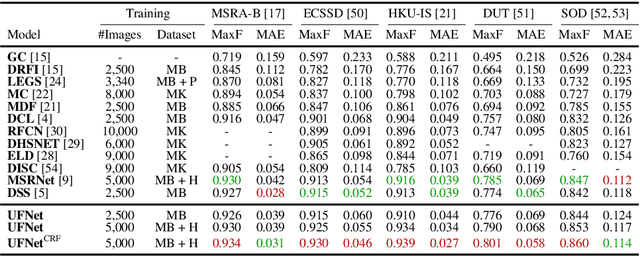
In this paper, we aim at solving pixel-wise binary problems, including salient object segmentation, skeleton extraction, and edge detection, by introducing a unified architecture. Previous works have proposed tailored methods for solving each of the three tasks independently. Here, we show that these tasks share some similarities that can be exploited for developing a unified framework. In particular, we introduce a horizontal cascade, each component of which is densely connected to the outputs of previous component. Stringing these components together allows us to effectively exploit features across different levels hierarchically to effectively address the multiple pixel-wise binary regression tasks. To assess the performance of our proposed network on these tasks, we carry out exhaustive evaluations on multiple representative datasets. Although these tasks are inherently very different, we show that our unified approach performs very well on all of them and works far better than current single-purpose state-of-the-art methods. All the code in this paper will be publicly available.
WebSeg: Learning Semantic Segmentation from Web Searches
Mar 27, 2018


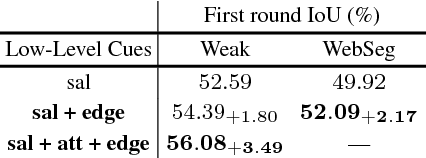
In this paper, we improve semantic segmentation by automatically learning from Flickr images associated with a particular keyword, without relying on any explicit user annotations, thus substantially alleviating the dependence on accurate annotations when compared to previous weakly supervised methods. To solve such a challenging problem, we leverage several low-level cues (such as saliency, edges, etc.) to help generate a proxy ground truth. Due to the diversity of web-crawled images, we anticipate a large amount of 'label noise' in which other objects might be present. We design an online noise filtering scheme which is able to deal with this label noise, especially in cluttered images. We use this filtering strategy as an auxiliary module to help assist the segmentation network in learning cleaner proxy annotations. Extensive experiments on the popular PASCAL VOC 2012 semantic segmentation benchmark show surprising good results in both our WebSeg (mIoU = 57.0%) and weakly supervised (mIoU = 63.3%) settings.
Devon: Deformable Volume Network for Learning Optical Flow
Feb 20, 2018
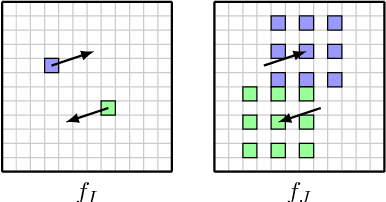
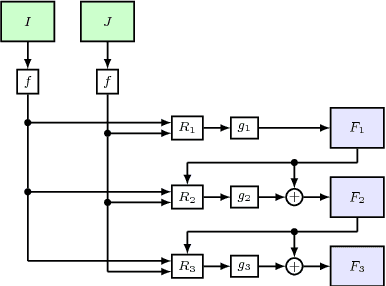
We propose a lightweight neural network model, Deformable Volume Network (Devon) for learning optical flow. Devon benefits from a multi-stage framework to iteratively refine its prediction. Each stage is by itself a neural network with an identical architecture. The optical flow between two stages is propagated with a newly proposed module, the deformable cost volume. The deformable cost volume does not distort the original images or their feature maps and therefore avoids the artifacts associated with warping, a common drawback in previous models. Devon only has one million parameters. Experiments show that Devon achieves comparable results to previous neural network models, despite of its small size.
Real-Time Dense Stereo Matching With ELAS on FPGA Accelerated Embedded Devices
Feb 20, 2018
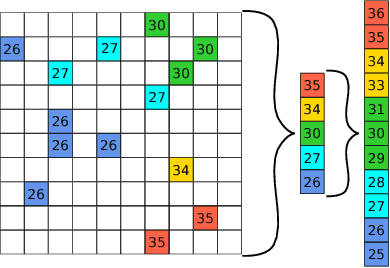
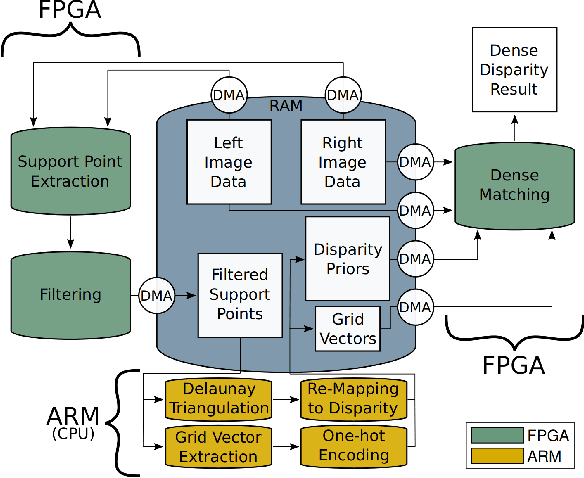
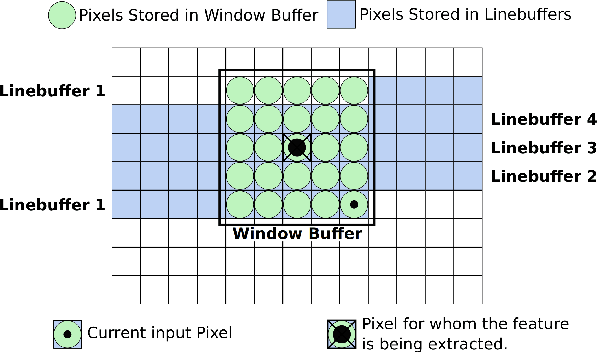
For many applications in low-power real-time robotics, stereo cameras are the sensors of choice for depth perception as they are typically cheaper and more versatile than their active counterparts. Their biggest drawback, however, is that they do not directly sense depth maps; instead, these must be estimated through data-intensive processes. Therefore, appropriate algorithm selection plays an important role in achieving the desired performance characteristics. Motivated by applications in space and mobile robotics, we implement and evaluate a FPGA-accelerated adaptation of the ELAS algorithm. Despite offering one of the best trade-offs between efficiency and accuracy, ELAS has only been shown to run at 1.5-3 fps on a high-end CPU. Our system preserves all intriguing properties of the original algorithm, such as the slanted plane priors, but can achieve a frame rate of 47fps whilst consuming under 4W of power. Unlike previous FPGA based designs, we take advantage of both components on the CPU/FPGA System-on-Chip to showcase the strategy necessary to accelerate more complex and computationally diverse algorithms for such low power, real-time systems.
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017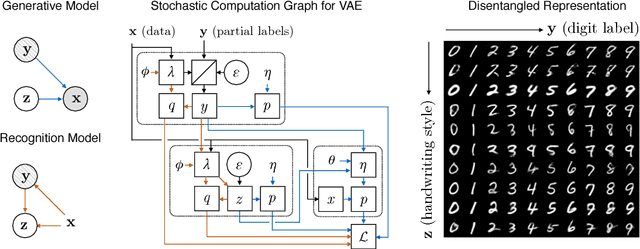

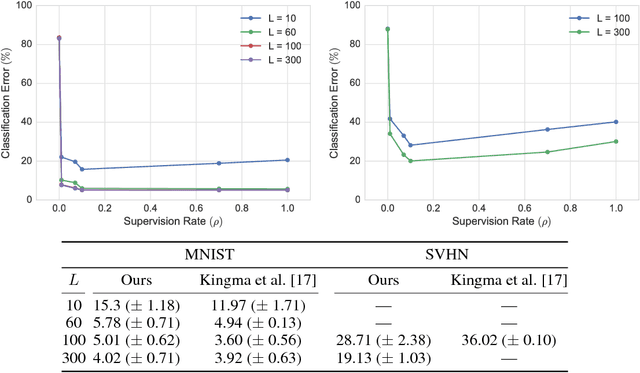
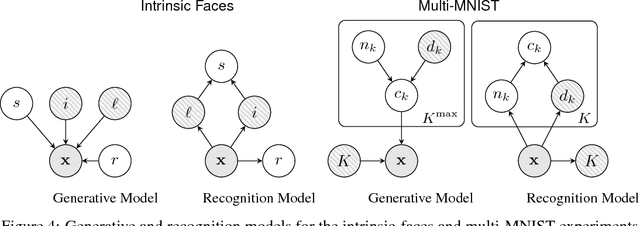
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Holistic, Instance-Level Human Parsing
Sep 11, 2017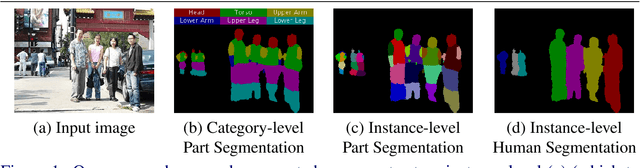
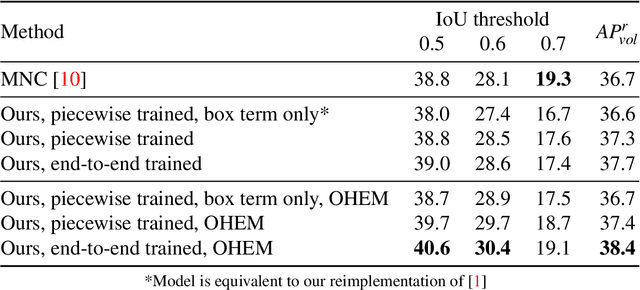
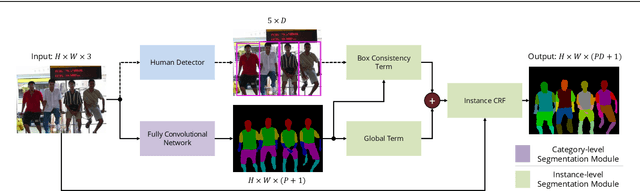
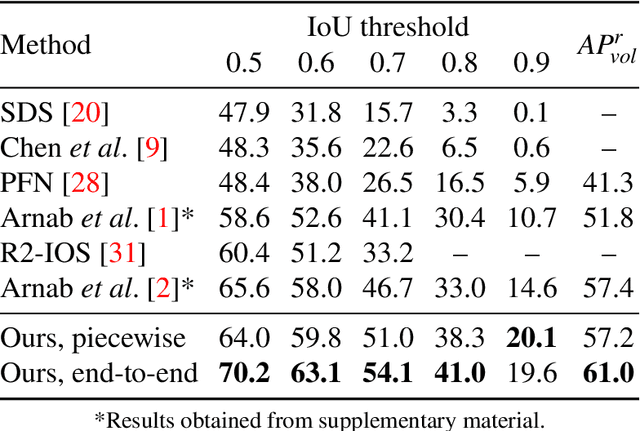
Object parsing -- the task of decomposing an object into its semantic parts -- has traditionally been formulated as a category-level segmentation problem. Consequently, when there are multiple objects in an image, current methods cannot count the number of objects in the scene, nor can they determine which part belongs to which object. We address this problem by segmenting the parts of objects at an instance-level, such that each pixel in the image is assigned a part label, as well as the identity of the object it belongs to. Moreover, we show how this approach benefits us in obtaining segmentations at coarser granularities as well. Our proposed network is trained end-to-end given detections, and begins with a category-level segmentation module. Thereafter, a differentiable Conditional Random Field, defined over a variable number of instances for every input image, reasons about the identity of each part by associating it with a human detection. In contrast to other approaches, our method can handle the varying number of people in each image and our holistic network produces state-of-the-art results in instance-level part and human segmentation, together with competitive results in category-level part segmentation, all achieved by a single forward-pass through our neural network.