 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
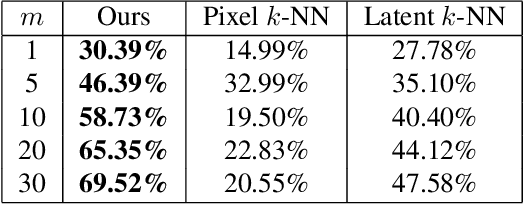
Add to EdgeLocal Class-Specific and Global Image-Level Generative Adversarial Networks for Semantic-Guided Scene Generation
Dec 27, 2019
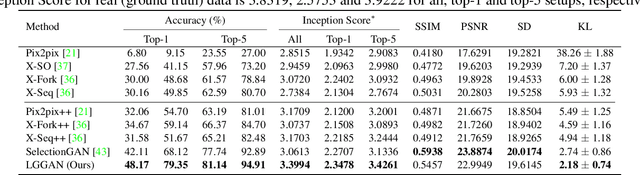
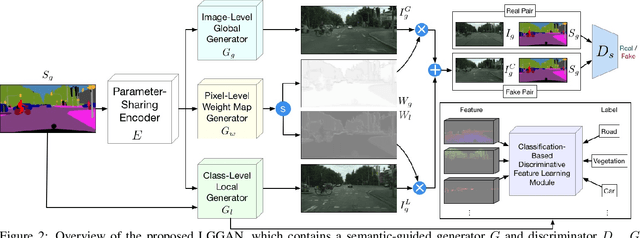
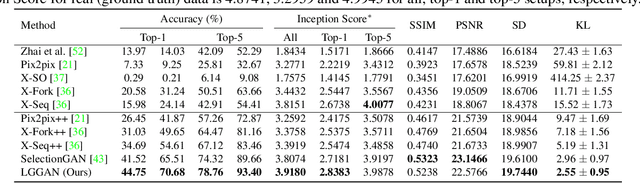
In this paper, we address the task of semantic-guided scene generation. One open challenge in scene generation is the difficulty of the generation of small objects and detailed local texture, which has been widely observed in global image-level generation methods. To tackle this issue, in this work we consider learning the scene generation in a local context, and correspondingly design a local class-specific generative network with semantic maps as a guidance, which separately constructs and learns sub-generators concentrating on the generation of different classes, and is able to provide more scene details. To learn more discriminative class-specific feature representations for the local generation, a novel classification module is also proposed. To combine the advantage of both the global image-level and the local class-specific generation, a joint generation network is designed with an attention fusion module and a dual-discriminator structure embedded. Extensive experiments on two scene image generation tasks show superior generation performance of the proposed model. The state-of-the-art results are established by large margins on both tasks and on challenging public benchmarks. The source code and trained models are available at https://github.com/Ha0Tang/LGGAN.
Learning Regional Attraction for Line Segment Detection
Dec 18, 2019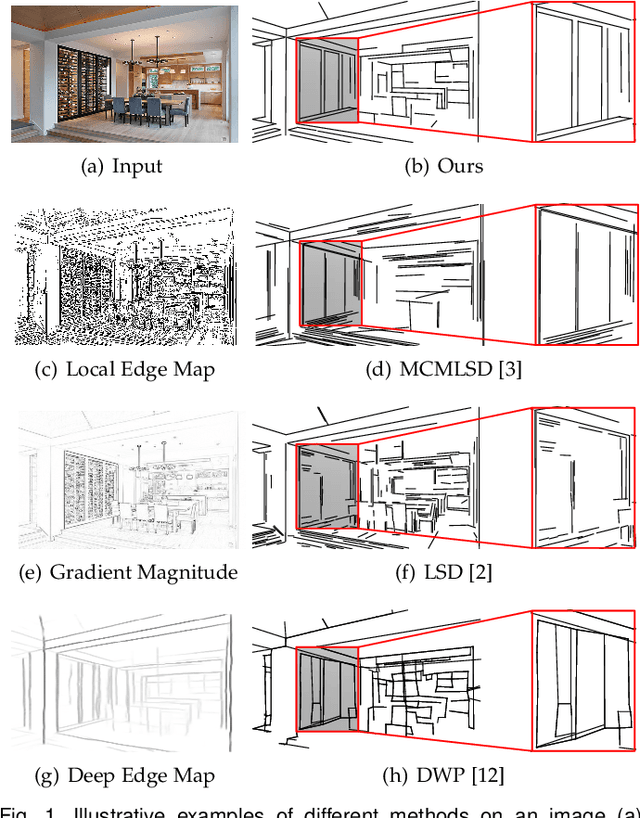
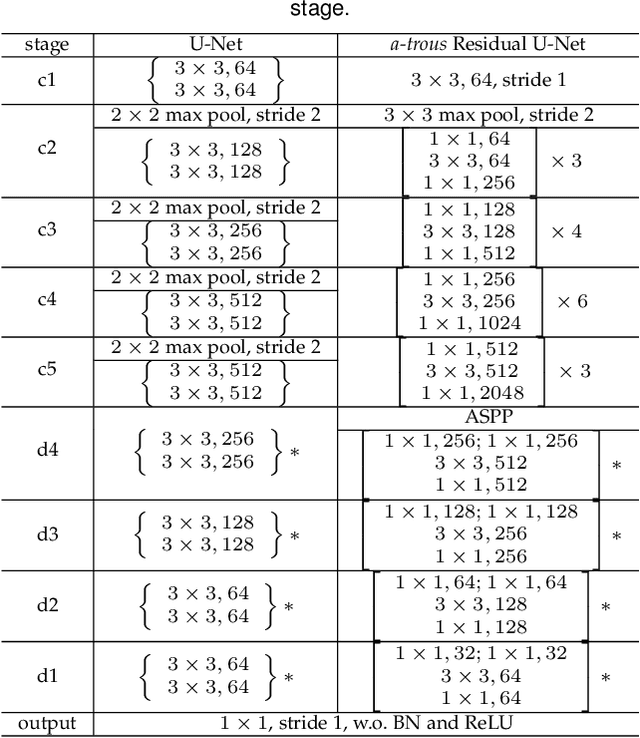
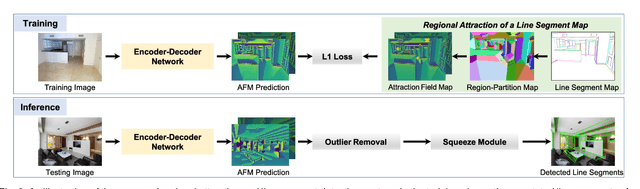
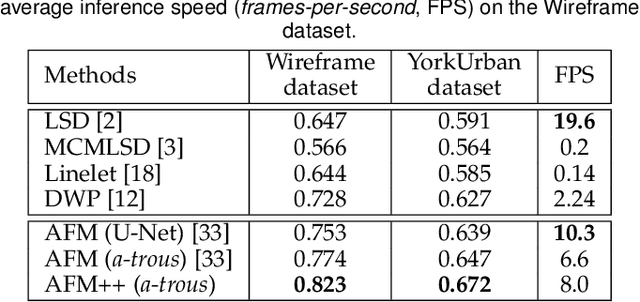
This paper presents regional attraction of line segment maps, and hereby poses the problem of line segment detection (LSD) as a problem of region coloring. Given a line segment map, the proposed regional attraction first establishes the relationship between line segments and regions in the image lattice. Based on this, the line segment map is equivalently transformed to an attraction field map (AFM), which can be remapped to a set of line segments without loss of information. Accordingly, we develop an end-to-end framework to learn attraction field maps for raw input images, followed by a squeeze module to detect line segments. Apart from existing works, the proposed detector properly handles the local ambiguity and does not rely on the accurate identification of edge pixels. Comprehensive experiments on the Wireframe dataset and the YorkUrban dataset demonstrate the superiority of our method. In particular, we achieve an F-measure of 0.831 on the Wireframe dataset, advancing the state-of-the-art performance by 10.3 percent.
Lessons from reinforcement learning for biological representations of space
Dec 13, 2019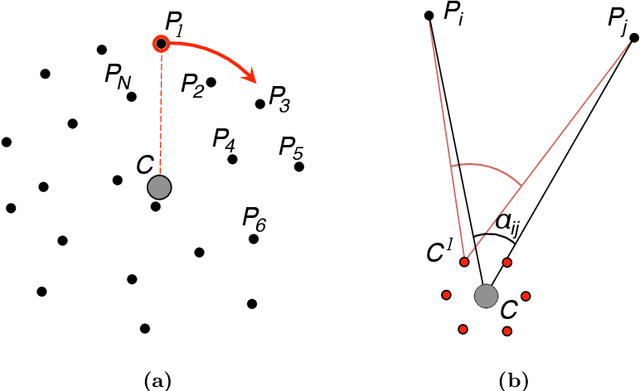

Neuroscientists postulate 3D representations in the brain in a variety of different coordinate frames (e.g. 'head-centred', 'hand-centred' and 'world-based'). Recent advances in reinforcement learning demonstrate a quite different approach that may provide a more promising model for biological representations underlying spatial perception and navigation. In this paper, we focus on reinforcement learning methods that reward an agent for arriving at a target image without any attempt to build up a 3D 'map'. We test the ability of this type of representation to support geometrically consistent spatial tasks, such as interpolating between learned locations, and compare its performance to that of a hand-crafted representation which has, by design, a high degree of geometric consistency. Our comparison of these two models demonstrates that it is advantageous to include information about the persistence of features as the camera translates (e.g. distant features persist). It is likely that non-Cartesian representations of this sort will be increasingly important in the search for robust models of human spatial perception and navigation.
ManiGAN: Text-Guided Image Manipulation
Dec 12, 2019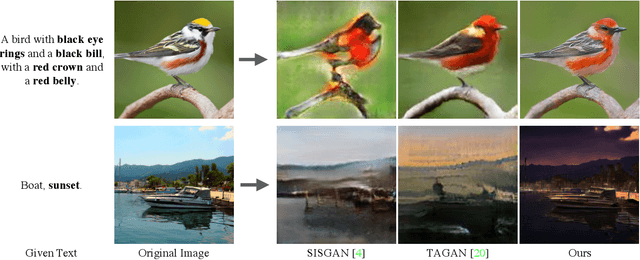
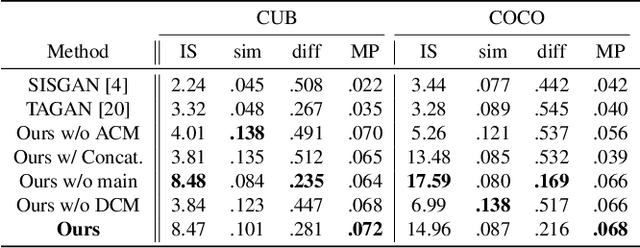
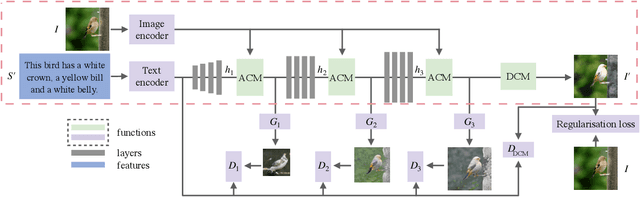
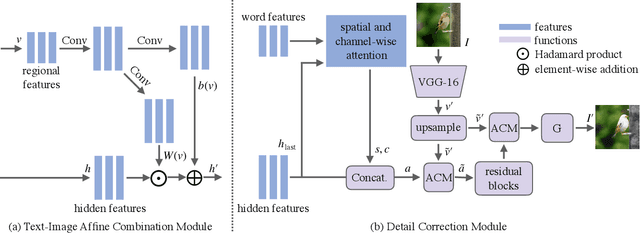
The goal of our paper is to semantically edit parts of an image to match a given text that describes desired attributes (e.g., texture, colour, and background), while preserving other contents that are irrelevant to the text. To achieve this, we propose a novel generative adversarial network (ManiGAN), which contains two key components: text-image affine combination module (ACM) and detail correction module (DCM). The ACM selects image regions relevant to the given text and then correlates the regions with corresponding semantic words for effective manipulation. Meanwhile, it encodes original image features to help reconstruct text-irrelevant contents. The DCM rectifies mismatched attributes and completes missing contents of the synthetic image. Finally, we suggest a new metric for evaluating image manipulation results, in terms of both the generation of new attributes and the reconstruction of text-irrelevant contents. Extensive experiments on the CUB and COCO datasets demonstrate the superior performance of the proposed method.
Transflow Learning: Repurposing Flow Models Without Retraining
Dec 05, 2019
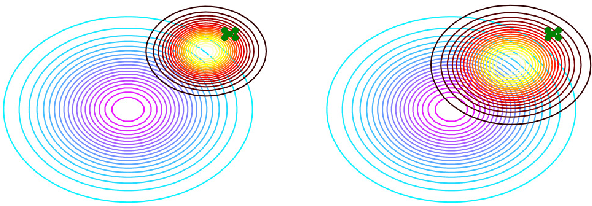

It is well known that deep generative models have a rich latent space, and that it is possible to smoothly manipulate their outputs by traversing this latent space. Recently, architectures have emerged that allow for more complex manipulations, such as making an image look as though it were from a different class, or painted in a certain style. These methods typically require large amounts of training in order to learn a single class of manipulations. We present Transflow Learning, a method for transforming a pre-trained generative model so that its outputs more closely resemble data that we provide afterwards. In contrast to previous methods, Transflow Learning does not require any training at all, and instead warps the probability distribution from which we sample latent vectors using Bayesian inference. Transflow Learning can be used to solve a wide variety of tasks, such as neural style transfer and few-shot classification.
Amortized Rejection Sampling in Universal Probabilistic Programming
Nov 30, 2019
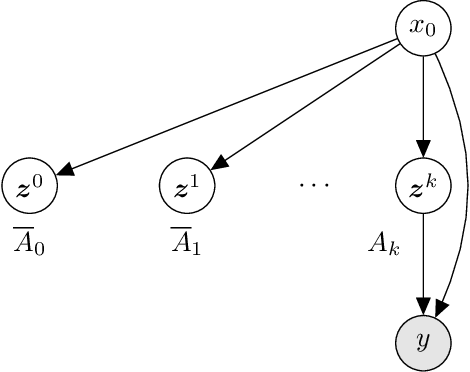
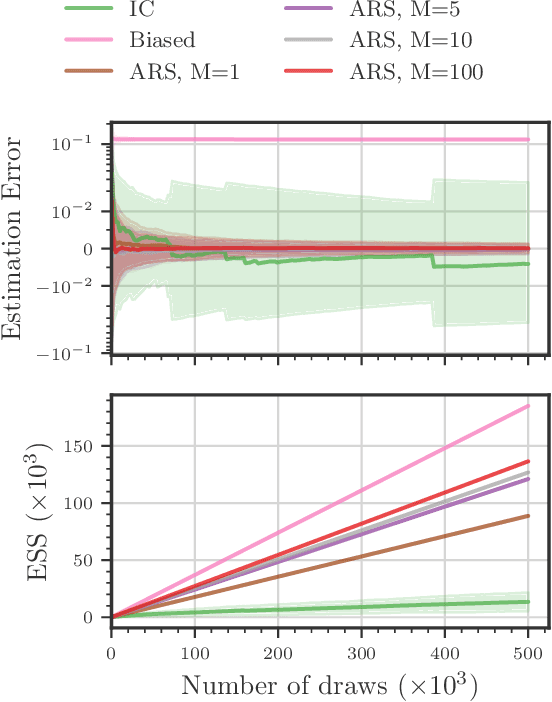
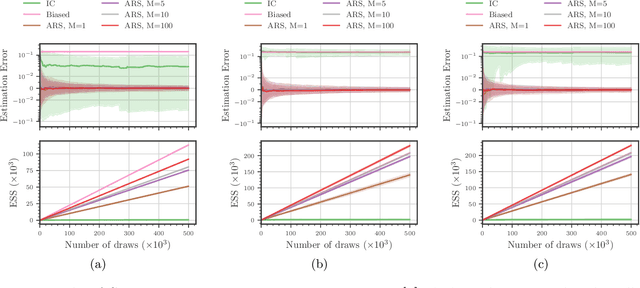
Existing approaches to amortized inference in probabilistic programs with unbounded loops can produce estimators with infinite variance. An instance of this is importance sampling inference in programs that explicitly include rejection sampling as part of the user-programmed generative procedure. In this paper we develop a new and efficient amortized importance sampling estimator. We prove finite variance of our estimator and empirically demonstrate our method's correctness and efficiency compared to existing alternatives on generative programs containing rejection sampling loops and discuss how to implement our method in a generic probabilistic programming framework.
Siam R-CNN: Visual Tracking by Re-Detection
Nov 28, 2019
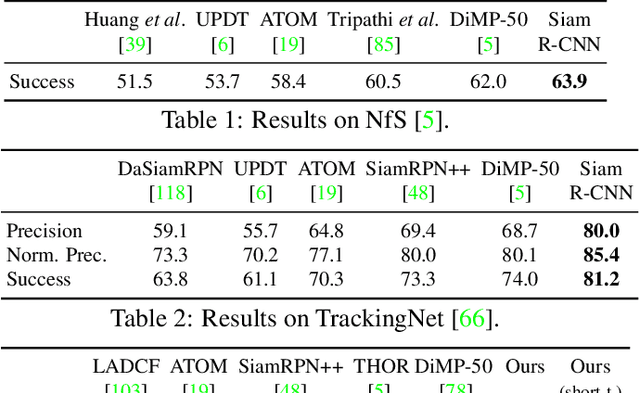
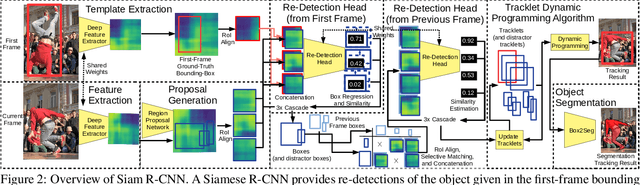
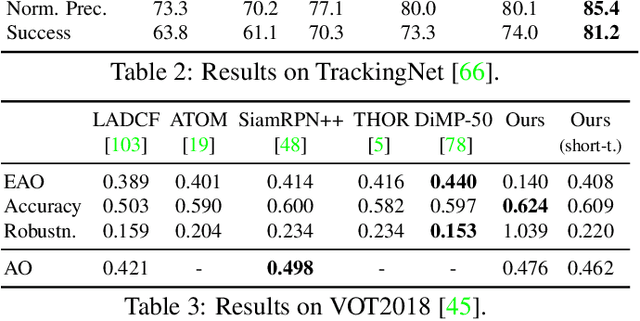
We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam R-CNN's robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep Generative Models
Nov 08, 2019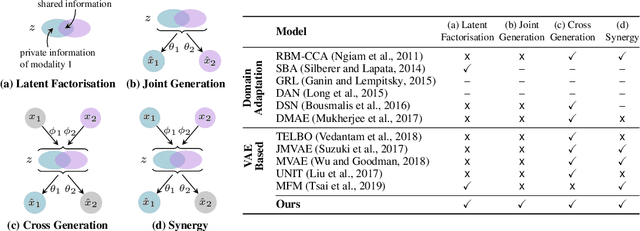


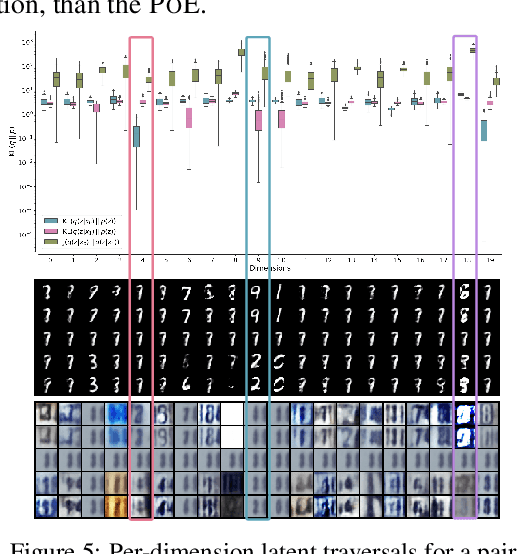
Learning generative models that span multiple data modalities, such as vision and language, is often motivated by the desire to learn more useful, generalisable representations that faithfully capture common underlying factors between the modalities. In this work, we characterise successful learning of such models as the fulfillment of four criteria: i) implicit latent decomposition into shared and private subspaces, ii) coherent joint generation over all modalities, iii) coherent cross-generation across individual modalities, and iv) improved model learning for individual modalities through multi-modal integration. Here, we propose a mixture-of-experts multimodal variational autoencoder (MMVAE) to learn generative models on different sets of modalities, including a challenging image-language dataset, and demonstrate its ability to satisfy all four criteria, both qualitatively and quantitatively.
Anchor Diffusion for Unsupervised Video Object Segmentation
Oct 24, 2019
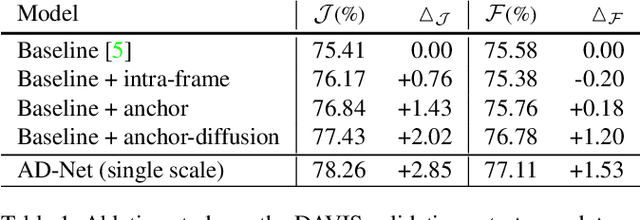
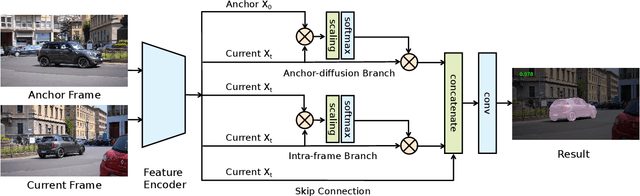
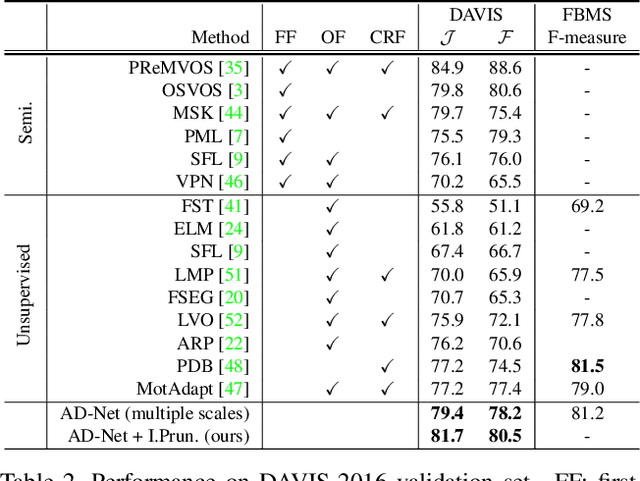
Unsupervised video object segmentation has often been tackled by methods based on recurrent neural networks and optical flow. Despite their complexity, these kinds of approaches tend to favour short-term temporal dependencies and are thus prone to accumulating inaccuracies, which cause drift over time. Moreover, simple (static) image segmentation models, alone, can perform competitively against these methods, which further suggests that the way temporal dependencies are modelled should be reconsidered. Motivated by these observations, in this paper we explore simple yet effective strategies to model long-term temporal dependencies. Inspired by the non-local operators of [70], we introduce a technique to establish dense correspondences between pixel embeddings of a reference "anchor" frame and the current one. This allows the learning of pairwise dependencies at arbitrarily long distances without conditioning on intermediate frames. Without online supervision, our approach can suppress the background and precisely segment the foreground object even in challenging scenarios, while maintaining consistent performance over time. With a mean IoU of $81.7\%$, our method ranks first on the DAVIS-2016 leaderboard of unsupervised methods, while still being competitive against state-of-the-art online semi-supervised approaches. We further evaluate our method on the FBMS dataset and the ViSal video saliency dataset, showing results competitive with the state of the art.
Mirror Descent View for Neural Network Quantization
Oct 18, 2019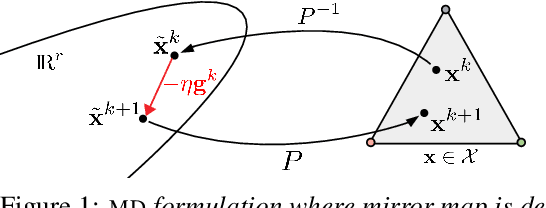
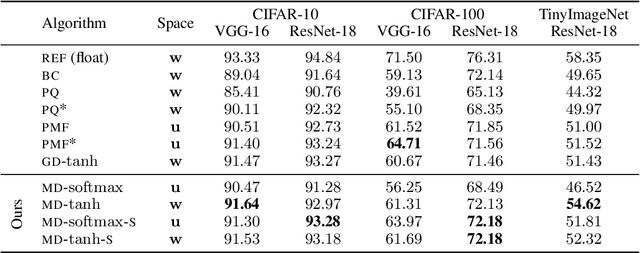
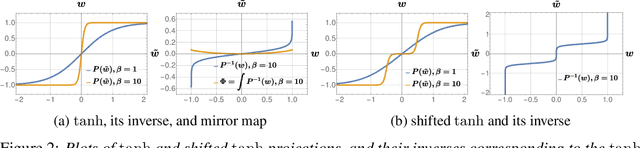
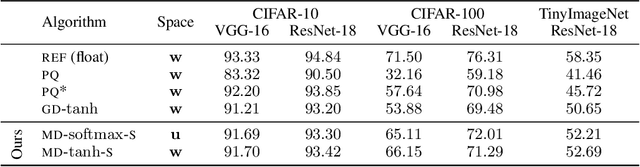
Quantizing large Neural Networks (NN) while maintaining the performance is highly desirable for resource-limited devices due to reduced memory and time complexity. NN quantization is usually formulated as a constrained optimization problem and optimized via a modified version of gradient descent. In this work, by interpreting the continuous parameters (unconstrained) as the dual of the quantized ones, we introduce a Mirror Descent (MD) framework (Bubeck (2015)) for NN quantization. Specifically, we provide conditions on the projections (i.e., mapping from continuous to quantized ones) which would enable us to derive valid mirror maps and in turn the respective MD updates. Furthermore, we discuss a numerically stable implementation of MD by storing an additional set of auxiliary dual variables (continuous). This update is strikingly analogous to the popular Straight Through Estimator (STE) based method which is typically viewed as a "trick" to avoid vanishing gradients issue but here we show that it is an implementation method for MD for certain projections. Our experiments on standard classification datasets (CIFAR-10/100, TinyImageNet) with convolutional and residual architectures show that our MD variants obtain fully-quantized networks with accuracies very close to the floating-point networks.