 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWS-IMUBench: Can Weakly Supervised Methods from Audio, Image, and Video Be Adapted for IMU-based Temporal Action Localization?
Feb 02, 2026IMU-based Human Activity Recognition (HAR) has enabled a wide range of ubiquitous computing applications, yet its dominant clip classification paradigm cannot capture the rich temporal structure of real-world behaviors. This motivates a shift toward IMU Temporal Action Localization (IMU-TAL), which predicts both action categories and their start/end times in continuous streams. However, current progress is strongly bottlenecked by the need for dense, frame-level boundary annotations, which are costly and difficult to scale. To address this bottleneck, we introduce WS-IMUBench, a systematic benchmark study of weakly supervised IMU-TAL (WS-IMU-TAL) under only sequence-level labels. Rather than proposing a new localization algorithm, we evaluate how well established weakly supervised localization paradigms from audio, image, and video transfer to IMU-TAL under only sequence-level labels. We benchmark seven representative weakly supervised methods on seven public IMU datasets, resulting in over 3,540 model training runs and 7,080 inference evaluations. Guided by three research questions on transferability, effectiveness, and insights, our findings show that (i) transfer is modality-dependent, with temporal-domain methods generally more stable than image-derived proposal-based approaches; (ii) weak supervision can be competitive on favorable datasets (e.g., with longer actions and higher-dimensional sensing); and (iii) dominant failure modes arise from short actions, temporal ambiguity, and proposal quality. Finally, we outline concrete directions for advancing WS-IMU-TAL (e.g., IMU-specific proposal generation, boundary-aware objectives, and stronger temporal reasoning). Beyond individual results, WS-IMUBench establishes a reproducible benchmarking template, datasets, protocols, and analyses, to accelerate community-wide progress toward scalable WS-IMU-TAL.
V2X-REALM: Vision-Language Model-Based Robust End-to-End Cooperative Autonomous Driving with Adaptive Long-Tail Modeling
Jun 26, 2025Ensuring robust planning and decision-making under rare, diverse, and visually degraded long-tail scenarios remains a fundamental challenge for autonomous driving in urban environments. This issue becomes more critical in cooperative settings, where vehicles and infrastructure jointly perceive and reason across complex environments. To address this challenge, we propose V2X-REALM, a vision-language model (VLM)-based framework with adaptive multimodal learning for robust cooperative autonomous driving under long-tail scenarios. V2X-REALM introduces three core innovations: (i) a prompt-driven long-tail scenario generation and evaluation pipeline that leverages foundation models to synthesize realistic long-tail conditions such as snow and fog across vehicle- and infrastructure-side views, enriching training diversity efficiently; (ii) a gated multi-scenario adaptive attention module that modulates the visual stream using scenario priors to recalibrate ambiguous or corrupted features; and (iii) a multi-task scenario-aware contrastive learning objective that improves multimodal alignment and promotes cross-scenario feature separability. Extensive experiments demonstrate that V2X-REALM significantly outperforms existing baselines in robustness, semantic reasoning, safety, and planning accuracy under complex, challenging driving conditions, advancing the scalability of end-to-end cooperative autonomous driving.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025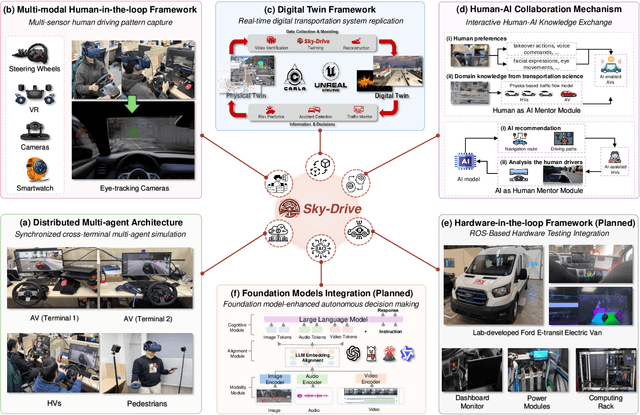
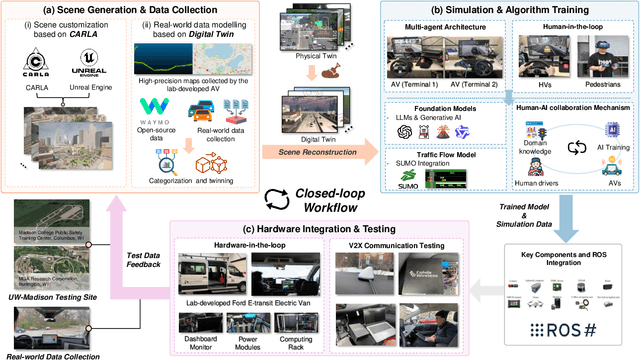
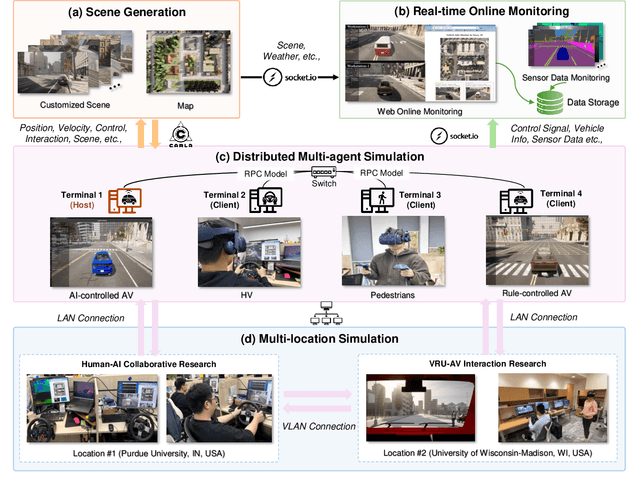
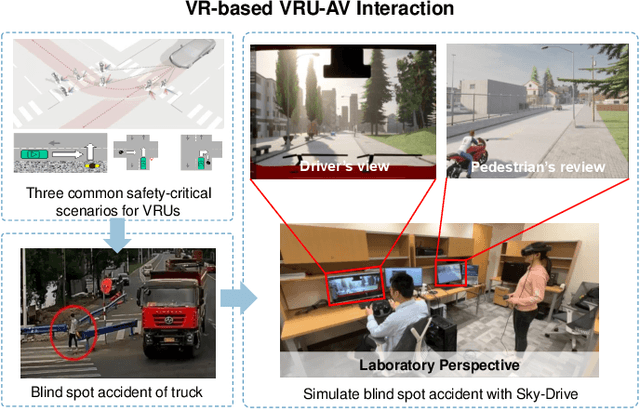
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
Planning Safety Trajectories with Dual-Phase, Physics-Informed, and Transportation Knowledge-Driven Large Language Models
Apr 06, 2025Foundation models have demonstrated strong reasoning and generalization capabilities in driving-related tasks, including scene understanding, planning, and control. However, they still face challenges in hallucinations, uncertainty, and long inference latency. While existing foundation models have general knowledge of avoiding collisions, they often lack transportation-specific safety knowledge. To overcome these limitations, we introduce LetsPi, a physics-informed, dual-phase, knowledge-driven framework for safe, human-like trajectory planning. To prevent hallucinations and minimize uncertainty, this hybrid framework integrates Large Language Model (LLM) reasoning with physics-informed social force dynamics. LetsPi leverages the LLM to analyze driving scenes and historical information, providing appropriate parameters and target destinations (goals) for the social force model, which then generates the future trajectory. Moreover, the dual-phase architecture balances reasoning and computational efficiency through its Memory Collection phase and Fast Inference phase. The Memory Collection phase leverages the physics-informed LLM to process and refine planning results through reasoning, reflection, and memory modules, storing safe, high-quality driving experiences in a memory bank. Surrogate safety measures and physics-informed prompt techniques are introduced to enhance the LLM's knowledge of transportation safety and physical force, respectively. The Fast Inference phase extracts similar driving experiences as few-shot examples for new scenarios, while simplifying input-output requirements to enable rapid trajectory planning without compromising safety. Extensive experiments using the HighD dataset demonstrate that LetsPi outperforms baseline models across five safety metrics.See PDF for project Github link.
V2X-LLM: Enhancing V2X Integration and Understanding in Connected Vehicle Corridors
Mar 04, 2025



The advancement of Connected and Automated Vehicles (CAVs) and Vehicle-to-Everything (V2X) offers significant potential for enhancing transportation safety, mobility, and sustainability. However, the integration and analysis of the diverse and voluminous V2X data, including Basic Safety Messages (BSMs) and Signal Phase and Timing (SPaT) data, present substantial challenges, especially on Connected Vehicle Corridors. These challenges include managing large data volumes, ensuring real-time data integration, and understanding complex traffic scenarios. Although these projects have developed an advanced CAV data pipeline that enables real-time communication between vehicles, infrastructure, and other road users for managing connected vehicle and roadside unit (RSU) data, significant hurdles in data comprehension and real-time scenario analysis and reasoning persist. To address these issues, we introduce the V2X-LLM framework, a novel enhancement to the existing CV data pipeline. V2X-LLM leverages Large Language Models (LLMs) to improve the understanding and real-time analysis of V2X data. The framework includes four key tasks: Scenario Explanation, offering detailed narratives of traffic conditions; V2X Data Description, detailing vehicle and infrastructure statuses; State Prediction, forecasting future traffic states; and Navigation Advisory, providing optimized routing instructions. By integrating LLM-driven reasoning with V2X data within the data pipeline, the V2X-LLM framework offers real-time feedback and decision support for traffic management. This integration enhances the accuracy of traffic analysis, safety, and traffic optimization. Demonstrations in a real-world urban corridor highlight the framework's potential to advance intelligent transportation systems.
XRF V2: A Dataset for Action Summarization with Wi-Fi Signals, and IMUs in Phones, Watches, Earbuds, and Glasses
Jan 31, 2025



Human Action Recognition (HAR) plays a crucial role in applications such as health monitoring, smart home automation, and human-computer interaction. While HAR has been extensively studied, action summarization, which involves identifying and summarizing continuous actions, remains an emerging task. This paper introduces the novel XRF V2 dataset, designed for indoor daily activity Temporal Action Localization (TAL) and action summarization. XRF V2 integrates multimodal data from Wi-Fi signals, IMU sensors (smartphones, smartwatches, headphones, and smart glasses), and synchronized video recordings, offering a diverse collection of indoor activities from 16 volunteers across three distinct environments. To tackle TAL and action summarization, we propose the XRFMamba neural network, which excels at capturing long-term dependencies in untrimmed sensory sequences and outperforms state-of-the-art methods, such as ActionFormer and WiFiTAD. We envision XRF V2 as a valuable resource for advancing research in human action localization, action forecasting, pose estimation, multimodal foundation models pre-training, synthetic data generation, and more.
Real-World Data Inspired Interactive Connected Traffic Scenario Generation
Sep 25, 2024



Simulation is a crucial step in ensuring accurate, efficient, and realistic Connected and Autonomous Vehicles (CAVs) testing and validation. As the adoption of CAV accelerates, the integration of real-world data into simulation environments becomes increasingly critical. Among various technologies utilized by CAVs, Vehicle-to-Everything (V2X) communication plays a crucial role in ensuring a seamless transmission of information between CAVs, infrastructure, and other road users. However, most existing studies have focused on developing and testing communication protocols, resource allocation strategies, and data dissemination techniques in V2X. There is a gap where real-world V2X data is integrated into simulations to generate diverse and high-fidelity traffic scenarios. To fulfill this research gap, we leverage real-world Signal Phase and Timing (SPaT) data from Roadside Units (RSUs) to enhance the fidelity of CAV simulations. Moreover, we developed an algorithm that enables Autonomous Vehicles (AVs) to respond dynamically to real-time traffic signal data, simulating realistic V2X communication scenarios. Such high-fidelity simulation environments can generate multimodal data, including trajectory, semantic camera, depth camera, and bird's eye view data for various traffic scenarios. The generated scenarios and data provide invaluable insights into AVs' interactions with traffic infrastructure and other road users. This work aims to bridge the gap between theoretical research and practical deployment of CAVs, facilitating the development of smarter and safer transportation systems.
Using physics-based simulation towards eliminating empiricism in extraterrestrial terramechanics applications
May 17, 2024



Recently, there has been a surge of international interest in extraterrestrial exploration targeting the Moon, Mars, the moons of Mars, and various asteroids. This contribution discusses how current state-of-the-art Earth-based testing for designing rovers and landers for these missions currently leads to overly optimistic conclusions about the behavior of these devices upon deployment on the targeted celestial bodies. The key misconception is that gravitational offset is necessary during the \textit{terramechanics} testing of rover and lander prototypes on Earth. The body of evidence supporting our argument is tied to a small number of studies conducted during parabolic flights and insights derived from newly revised scaling laws. We argue that what has prevented the community from fully diagnosing the problem at hand is the absence of effective physics-based models capable of simulating terramechanics under low gravity conditions. We developed such a physics-based simulator and utilized it to gauge the mobility of early prototypes of the Volatiles Investigating Polar Exploration Rover (VIPER), which is slated to depart for the Moon in November 2024. This contribution discusses the results generated by this simulator, how they correlate with physical test results from the NASA-Glenn SLOPE lab, and the fallacy of the gravitational offset in rover and lander testing. The simulator developed is open sourced and made publicly available for unfettered use; it can support principled studies that extend beyond trafficability analysis to provide insights into in-situ resource utilization activities, e.g., digging, bulldozing, and berming in low gravity.
Three-layer deep learning network random trees for fault diagnosis in chemical production process
May 01, 2024With the development of technology, the chemical production process is becoming increasingly complex and large-scale, making fault diagnosis particularly important. However, current diagnostic methods struggle to address the complexities of large-scale production processes. In this paper, we integrate the strengths of deep learning and machine learning technologies, combining the advantages of bidirectional long and short-term memory neural networks, fully connected neural networks, and the extra trees algorithm to propose a novel fault diagnostic model named three-layer deep learning network random trees (TDLN-trees). First, the deep learning component extracts temporal features from industrial data, combining and transforming them into a higher-level data representation. Second, the machine learning component processes and classifies the features extracted in the first step. An experimental analysis based on the Tennessee Eastman process verifies the superiority of the proposed method.
Demystifying Deep Reinforcement Learning-Based Autonomous Vehicle Decision-Making
Mar 18, 2024With the advent of universal function approximators in the domain of reinforcement learning, the number of practical applications leveraging deep reinforcement learning (DRL) has exploded. Decision-making in automated driving tasks has emerged as a chief application among them, taking the sensor data or the higher-order kinematic variables as the input and providing a discrete choice or continuous control output. However, the black-box nature of the models presents an overwhelming limitation that restricts the real-world deployment of DRL in autonomous vehicles (AVs). Therefore, in this research work, we focus on the interpretability of an attention-based DRL framework. We use a continuous proximal policy optimization-based DRL algorithm as the baseline model and add a multi-head attention framework in an open-source AV simulation environment. We provide some analytical techniques for discussing the interpretability of the trained models in terms of explainability and causality for spatial and temporal correlations. We show that the weights in the first head encode the positions of the neighboring vehicles while the second head focuses on the leader vehicle exclusively. Also, the ego vehicle's action is causally dependent on the vehicles in the target lane spatially and temporally. Through these findings, we reliably show that these techniques can help practitioners decipher the results of the DRL algorithms.