 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied AI in Action: Insights from SAE World Congress 2026 on Safety, Trust, Robotics, and Real-World Deployment
May 11, 2026Embodied artificial intelligence is rapidly moving from research into real-world systems such as autonomous vehicles, mobile robots, and industrial machines. As these systems become more capable of perceiving, deciding, and acting in dynamic environments, they also introduce new challenges in safety, trust, governance, and operational reliability. This white paper summarizes key insights from the SAE World Congress 2026 panel session \textit{Embodied AI in Action}, which brought together experts from automotive, robotics, artificial intelligence, and safety engineering. The discussion highlighted the need to treat embodied AI as a systems challenge requiring engineering rigor, lifecycle governance, human-centered design, and evolving standards. The paper provides practical perspectives for executives, policymakers, and technical leaders seeking to adopt embodied AI responsibly. The panel reached broad agreement that long-term success will depend not only on advances in AI capability, but equally on safe and trustworthy deployment.
Mitigating Context Bias in Domain Adaptation for Object Detection using Mask Pooling
May 24, 2025Context bias refers to the association between the foreground objects and background during the object detection training process. Various methods have been proposed to minimize the context bias when applying the trained model to an unseen domain, known as domain adaptation for object detection (DAOD). But a principled approach to understand why the context bias occurs and how to remove it has been missing. In this work, we provide a causal view of the context bias, pointing towards the pooling operation in the convolution network architecture as the possible source of this bias. We present an alternative, Mask Pooling, which uses an additional input of foreground masks, to separate the pooling process in the respective foreground and background regions and show that this process leads the trained model to detect objects in a more robust manner under different domains. We also provide a benchmark designed to create an ultimate test for DAOD, using foregrounds in the presence of absolute random backgrounds, to analyze the robustness of the intended trained models. Through these experiments, we hope to provide a principled approach for minimizing context bias under domain shift.
MatPredict: a dataset and benchmark for learning material properties of diverse indoor objects
May 19, 2025



Determining material properties from camera images can expand the ability to identify complex objects in indoor environments, which is valuable for consumer robotics applications. To support this, we introduce MatPredict, a dataset that combines the high-quality synthetic objects from Replica dataset with MatSynth dataset's material properties classes - to create objects with diverse material properties. We select 3D meshes of specific foreground objects and render them with different material properties. In total, we generate \textbf{18} commonly occurring objects with \textbf{14} different materials. We showcase how we provide variability in terms of lighting and camera placement for these objects. Next, we provide a benchmark for inferring material properties from visual images using these perturbed models in the scene, discussing the specific neural network models involved and their performance based on different image comparison metrics. By accurately simulating light interactions with different materials, we can enhance realism, which is crucial for training models effectively through large-scale simulations. This research aims to revolutionize perception in consumer robotics. The dataset is provided \href{https://huggingface.co/datasets/UMTRI/MatPredict}{here} and the code is provided \href{https://github.com/arpan-kusari/MatPredict}{here}.
Car-STAGE: Automated framework for large-scale high-dimensional simulated time-series data generation based on user-defined criteria
Mar 05, 2025Generating large-scale sensing datasets through photo-realistic simulation is an important aspect of many robotics applications such as autonomous driving. In this paper, we consider the problem of synchronous data collection from the open-source CARLA simulator using multiple sensors attached to vehicle based on user-defined criteria. We propose a novel, one-step framework that we refer to as Car-STAGE, based on CARLA simulator, to generate data using a graphical user interface (GUI) defining configuration parameters to data collection without any user intervention. This framework can utilize the user-defined configuration parameters such as choice of maps, number and configurations of sensors, environmental and lighting conditions etc. to run the simulation in the background, collecting high-dimensional sensor data from diverse sensors such as RGB Camera, LiDAR, Radar, Depth Camera, IMU Sensor, GNSS Sensor, Semantic Segmentation Camera, Instance Segmentation Camera, and Optical Flow Camera along with the ground-truths of the individual actors and storing the sensor data as well as ground-truth labels in a local or cloud-based database. The framework uses multiple threads where a main thread runs the server, a worker thread deals with queue and frame number and the rest of the threads processes the sensor data. The other way we derive speed up over the native implementation is by memory mapping the raw binary data into the disk and then converting the data into known formats at the end of data collection. We show that using these techniques, we gain a significant speed up over frames, under an increasing set of sensors and over the number of spawned objects.
Uncertainty-Aware Out-of-Distribution Detection with Gaussian Processes
Dec 30, 2024Deep neural networks (DNNs) are often constructed under the closed-world assumption, which may fail to generalize to the out-of-distribution (OOD) data. This leads to DNNs producing overconfident wrong predictions and can result in disastrous consequences in safety-critical applications. Existing OOD detection methods mainly rely on curating a set of OOD data for model training or hyper-parameter tuning to distinguish OOD data from training data (also known as in-distribution data or InD data). However, OOD samples are not always available during the training phase in real-world applications, hindering the OOD detection accuracy. To overcome this limitation, we propose a Gaussian-process-based OOD detection method to establish a decision boundary based on InD data only. The basic idea is to perform uncertainty quantification of the unconstrained softmax scores of a DNN via a multi-class Gaussian process (GP), and then define a score function to separate InD and potential OOD data based on their fundamental differences in the posterior predictive distribution from the GP. Two case studies on conventional image classification datasets and real-world image datasets are conducted to demonstrate that the proposed method outperforms the state-of-the-art OOD detection methods when OOD samples are not observed in the training phase.
Generating camera failures as a class of physics-based adversarial examples
May 23, 2024While there has been extensive work on generating physics-based adversarial samples recently, an overlooked class of such samples come from physical failures in the camera. Camera failures can occur as a result of an external physical process, i.e. breakdown of a component due to stress, or an internal component failure. In this work, we develop a simulated physical process for generating broken lens as a class of physics-based adversarial samples. We create a stress-based physical simulation by generating particles constrained in a mesh and apply stress at a random point and at a random angle. We perform stress propagation through the mesh and the end result of the mesh is a corresponding image which simulates the broken lens pattern. We also develop a neural emulator which learns the non-linear mapping between the mesh as a graph and the stress propagation using constrained propagation setup. We can then statistically compare the difference between the generated adversarial samples with real, simulated and emulated adversarial examples using the detection failure rate of the different classes and in between the samples using the Frechet Inception distance. Our goal through this work is to provide a robust physics based process for generating adversarial samples.
Demystifying Deep Reinforcement Learning-Based Autonomous Vehicle Decision-Making
Mar 18, 2024



With the advent of universal function approximators in the domain of reinforcement learning, the number of practical applications leveraging deep reinforcement learning (DRL) has exploded. Decision-making in automated driving tasks has emerged as a chief application among them, taking the sensor data or the higher-order kinematic variables as the input and providing a discrete choice or continuous control output. However, the black-box nature of the models presents an overwhelming limitation that restricts the real-world deployment of DRL in autonomous vehicles (AVs). Therefore, in this research work, we focus on the interpretability of an attention-based DRL framework. We use a continuous proximal policy optimization-based DRL algorithm as the baseline model and add a multi-head attention framework in an open-source AV simulation environment. We provide some analytical techniques for discussing the interpretability of the trained models in terms of explainability and causality for spatial and temporal correlations. We show that the weights in the first head encode the positions of the neighboring vehicles while the second head focuses on the leader vehicle exclusively. Also, the ego vehicle's action is causally dependent on the vehicles in the target lane spatially and temporally. Through these findings, we reliably show that these techniques can help practitioners decipher the results of the DRL algorithms.
Object level footprint uncertainty quantification in infrastructure based sensing
Aug 24, 2023



We examine the problem of estimating footprint uncertainty of objects imaged using the infrastructure based camera sensing. A closed form relationship is established between the ground coordinates and the sources of the camera errors. Using the error propagation equation, the covariance of a given ground coordinate can be measured as a function of the camera errors. The uncertainty of the footprint of the bounding box can then be given as the function of all the extreme points of the object footprint. In order to calculate the uncertainty of a ground point, the typical error sizes of the error sources are required. We present a method of estimating the typical error sizes from an experiment using a static, high-precision LiDAR as the ground truth. Finally, we present a simulated case study of uncertainty quantification from infrastructure based camera in CARLA to provide a sense of how the uncertainty changes across a left turn maneuver.
Operational requirements for localization in autonomous vehicles
Aug 23, 2023Autonomous vehicles (AVs) need to determine their position and orientation accurately with respect to global coordinate system or local features under different scene geometries, traffic conditions and environmental conditions. \cite{reid2019localization} provides a comprehensive framework for the localization requirements for AVs. However, the framework is too restrictive whereby - (a) only a very small deviation from the lane is tolerated (one every $10^{8}$ hours), (b) all roadway types are considered same without any attention to restriction provided by the environment onto the localization and (c) the temporal nature of the location and orientation is not considered in the requirements. In this research, we present a more practical view of the localization requirement aimed at keeping the AV safe during an operation. We present the following novel contributions - (a) we propose a deviation penalty as a cumulative distribution function of the Weibull distribution which starts from the adjacent lane boundary, (b) we customize the parameters of the deviation penalty according to the current roadway type, particular lane boundary that the ego vehicle is against and roadway curvature and (c) we update the deviation penalty based on the available gap in the adjacent lane. We postulate that this formulation can provide a more robust and achievable view of the localization requirements than previous research while focusing on safety.
Efficient Subgraph Isomorphism using Graph Topology
Sep 15, 2022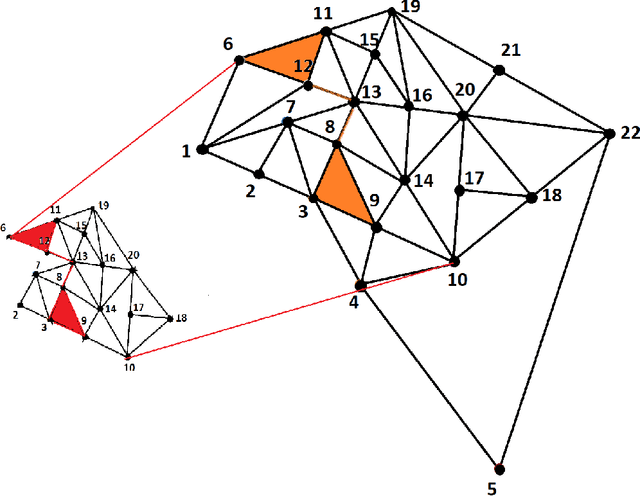
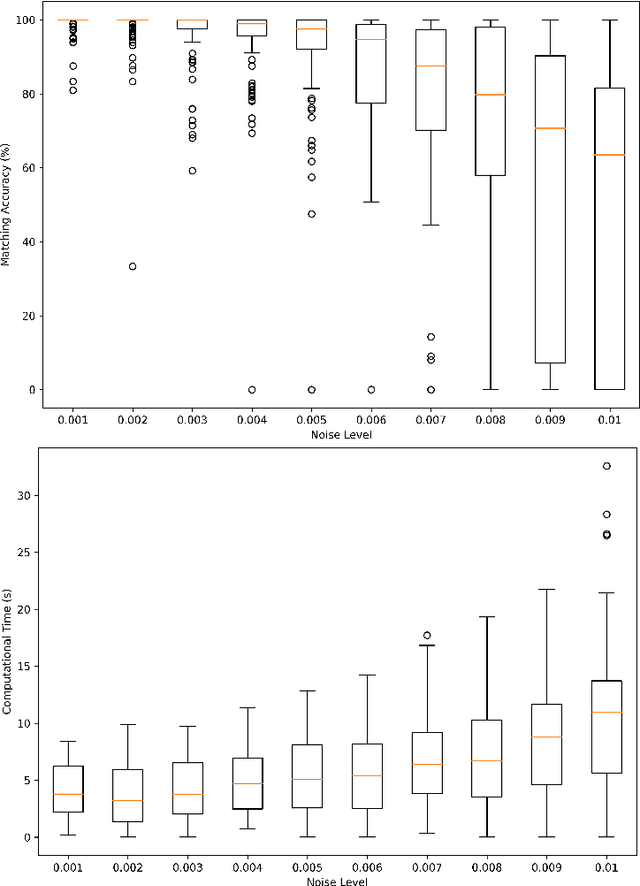

Subgraph isomorphism or subgraph matching is generally considered as an NP-complete problem, made more complex in practical applications where the edge weights take real values and are subject to measurement noise and possible anomalies. To the best of our knowledge, almost all subgraph matching methods utilize node labels to perform node-node matching. In the absence of such labels (in applications such as image matching and map matching among others), these subgraph matching methods do not work. We propose a method for identifying the node correspondence between a subgraph and a full graph in the inexact case without node labels in two steps - (a) extract the minimal unique topology preserving subset from the subgraph and find its feasible matching in the full graph, and (b) implement a consensus-based algorithm to expand the matched node set by pairing unique paths based on boundary commutativity. Going beyond the existing subgraph matching approaches, the proposed method is shown to have realistically sub-linear computational efficiency, robustness to random measurement noise, and good statistical properties. Our method is also readily applicable to the exact matching case without loss of generality. To demonstrate the effectiveness of the proposed method, a simulation and a case study is performed on the Erdos-Renyi random graphs and the image-based affine covariant features dataset respectively.