 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProdCodeBench: A Production-Derived Benchmark for Evaluating AI Coding Agents
Apr 02, 2026Benchmarks that reflect production workloads are better for evaluating AI coding agents in industrial settings, yet existing benchmarks differ from real usage in programming language distribution, prompt style and codebase structure. This paper presents a methodology for curating production-derived benchmarks, illustrated through ProdCodeBench - a benchmark built from real sessions with a production AI coding assistant. We detail our data collection and curation practices including LLM-based task classification, test relevance validation, and multi-run stability checks which address challenges in constructing reliable evaluation signals from monorepo environments. Each curated sample consists of a verbatim prompt, a committed code change and fail-to-pass tests spanning seven programming languages. Our systematic analysis of four foundation models yields solve rates from 53.2% to 72.2% revealing that models making greater use of work validation tools, such as executing tests and invoking static analysis, achieve higher solve rates. This suggests that iterative verification helps achieve effective agent behavior and that exposing codebase-specific verification mechanisms may significantly improve the performance of externally trained agents operating in unfamiliar environments. We share our methodology and lessons learned to enable other organizations to construct similar production-derived benchmarks.
Wink: Recovering from Misbehaviors in Coding Agents
Feb 19, 2026Autonomous coding agents, powered by large language models (LLMs), are increasingly being adopted in the software industry to automate complex engineering tasks. However, these agents are prone to a wide range of misbehaviors, such as deviating from the user's instructions, getting stuck in repetitive loops, or failing to use tools correctly. These failures disrupt the development workflow and often require resource-intensive manual intervention. In this paper, we present a system for automatically recovering from agentic misbehaviors at scale. We first introduce a taxonomy of misbehaviors grounded in an analysis of production traffic, identifying three primary categories: Specification Drift, Reasoning Problems, and Tool Call Failures, which we find occur in about 30% of all agent trajectories. To address these issues, we developed a lightweight, asynchronous self-intervention system named Wink. Wink observes agent trajectories and provides targeted course-correction guidance to nudge the agent back to a productive path. We evaluated our system on over 10,000 real world agent trajectories and found that it successfully resolves 90% of the misbehaviors that require a single intervention. Furthermore, a live A/B test in our production environment demonstrated that our system leads to a statistically significant reduction in Tool Call Failures, Tokens per Session and Engineer Interventions per Session. We present our experience designing and deploying this system, offering insights into the challenges of building resilient agentic systems at scale.
Scaling Parameter-Constrained Language Models with Quality Data
Oct 04, 2024



Scaling laws in language modeling traditionally quantify training loss as a function of dataset size and model parameters, providing compute-optimal estimates but often neglecting the impact of data quality on model generalization. In this paper, we extend the conventional understanding of scaling law by offering a microscopic view of data quality within the original formulation -- effective training tokens -- which we posit to be a critical determinant of performance for parameter-constrained language models. Specifically, we formulate the proposed term of effective training tokens to be a combination of two readily-computed indicators of text: (i) text diversity and (ii) syntheticity as measured by a teacher model. We pretrained over $200$ models of 25M to 1.5B parameters on a diverse set of sampled, synthetic data, and estimated the constants that relate text quality, model size, training tokens, and eight reasoning task accuracy scores. We demonstrated the estimated constants yield +0.83 Pearson correlation with true accuracies, and analyzed it in scenarios involving widely-used data techniques such as data sampling and synthesis which aim to improve data quality.
Universal Fuzzing via Large Language Models
Aug 09, 2023



Fuzzing has achieved tremendous success in discovering bugs and vulnerabilities in various software systems. Systems under test (SUTs) that take in programming or formal language as inputs, e.g., compilers, runtime engines, constraint solvers, and software libraries with accessible APIs, are especially important as they are fundamental building blocks of software development. However, existing fuzzers for such systems often target a specific language, and thus cannot be easily applied to other languages or even other versions of the same language. Moreover, the inputs generated by existing fuzzers are often limited to specific features of the input language, and thus can hardly reveal bugs related to other or new features. This paper presents Fuzz4All, the first fuzzer that is universal in the sense that it can target many different input languages and many different features of these languages. The key idea behind Fuzz4All is to leverage large language models (LLMs) as an input generation and mutation engine, which enables the approach to produce diverse and realistic inputs for any practically relevant language. To realize this potential, we present a novel autoprompting technique, which creates LLM prompts that are wellsuited for fuzzing, and a novel LLM-powered fuzzing loop, which iteratively updates the prompt to create new fuzzing inputs. We evaluate Fuzz4All on nine systems under test that take in six different languages (C, C++, Go, SMT2, Java and Python) as inputs. The evaluation shows, across all six languages, that universal fuzzing achieves higher coverage than existing, language-specific fuzzers. Furthermore, Fuzz4All has identified 76 bugs in widely used systems, such as GCC, Clang, Z3, CVC5, OpenJDK, and the Qiskit quantum computing platform, with 47 bugs already confirmed by developers as previously unknown.
Extracting Meaningful Attention on Source Code: An Empirical Study of Developer and Neural Model Code Exploration
Oct 11, 2022
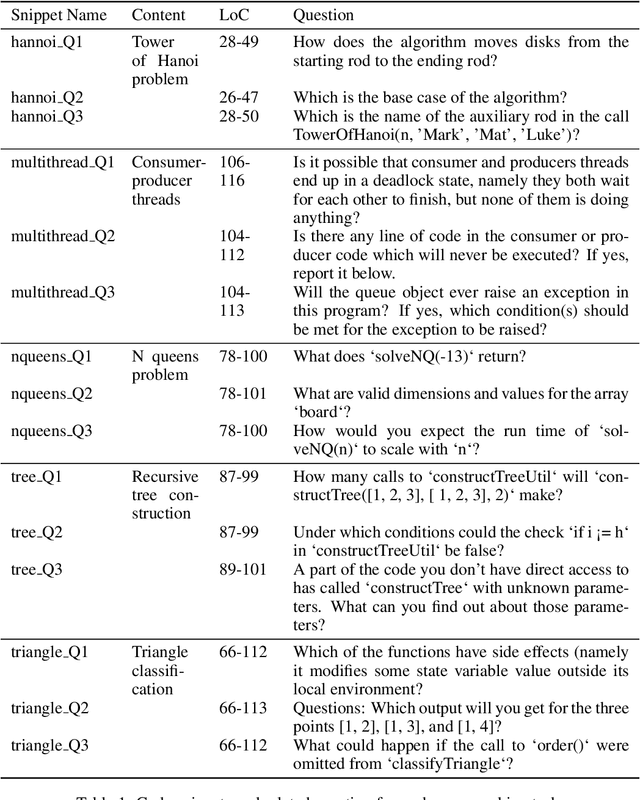
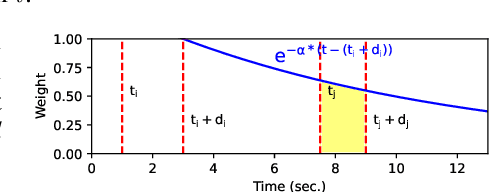
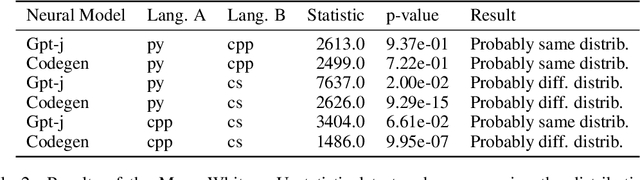
The high effectiveness of neural models of code, such as OpenAI Codex and AlphaCode, suggests coding capabilities of models that are at least comparable to those of humans. However, previous work has only used these models for their raw completion, ignoring how the model reasoning, in the form of attention weights, can be used for other downstream tasks. Disregarding the attention weights means discarding a considerable portion of what those models compute when queried. To profit more from the knowledge embedded in these large pre-trained models, this work compares multiple approaches to post-process these valuable attention weights for supporting code exploration. Specifically, we compare to which extent the transformed attention signal of CodeGen, a large and publicly available pretrained neural model, agrees with how developers look at and explore code when each answering the same sense-making questions about code. At the core of our experimental evaluation, we collect, manually annotate, and open-source a novel eye-tracking dataset comprising 25 developers answering sense-making questions on code over 92 sessions. We empirically evaluate five attention-agnostic heuristics and ten attention-based post processing approaches of the attention signal against our ground truth of developers exploring code, including the novel concept of follow-up attention which exhibits the highest agreement. Beyond the dataset contribution and the empirical study, we also introduce a novel practical application of the attention signal of pre-trained models with completely analytical solutions, going beyond how neural models' attention mechanisms have traditionally been used.