 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas is Your Perfect Context: One-Shot Customization for Generalizable Foundational Medical Image Segmentation
Dec 20, 2025



Accurate medical image segmentation is essential for clinical diagnosis and treatment planning. While recent interactive foundation models (e.g., nnInteractive) enhance generalization through large-scale multimodal pretraining, they still depend on precise prompts and often perform below expectations in contexts that are underrepresented in their training data. We present AtlasSegFM, an atlas-guided framework that customizes available foundation models to clinical contexts with a single annotated example. The core innovations are: 1) a pipeline that provides context-aware prompts for foundation models via registration between a context atlas and query images, and 2) a test-time adapter to fuse predictions from both atlas registration and the foundation model. Extensive experiments across public and in-house datasets spanning multiple modalities and organs demonstrate that AtlasSegFM consistently improves segmentation, particularly for small, delicate structures. AtlasSegFM provides a lightweight, deployable solution one-shot customization of foundation models in real-world clinical workflows. The code will be made publicly available.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025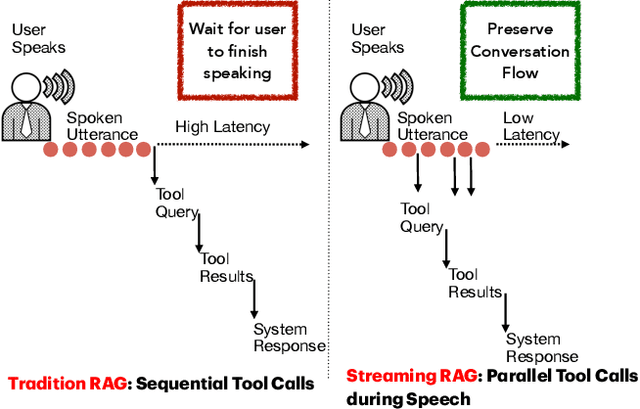
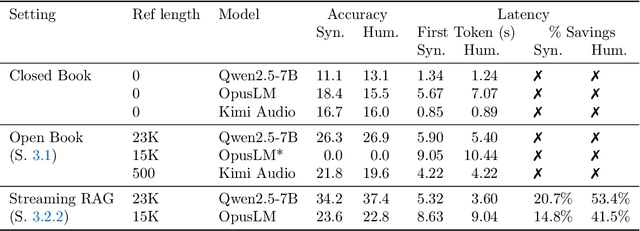
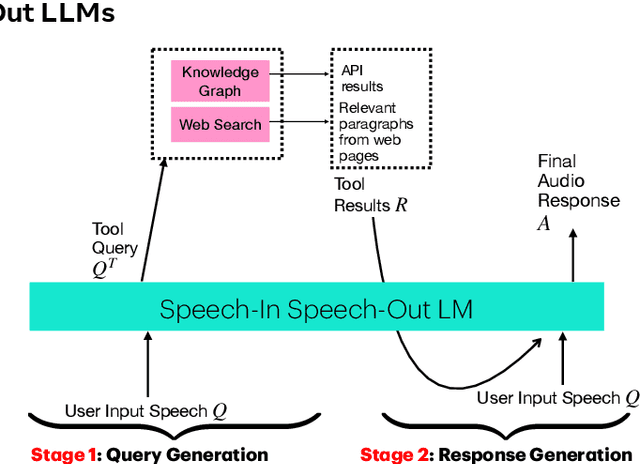
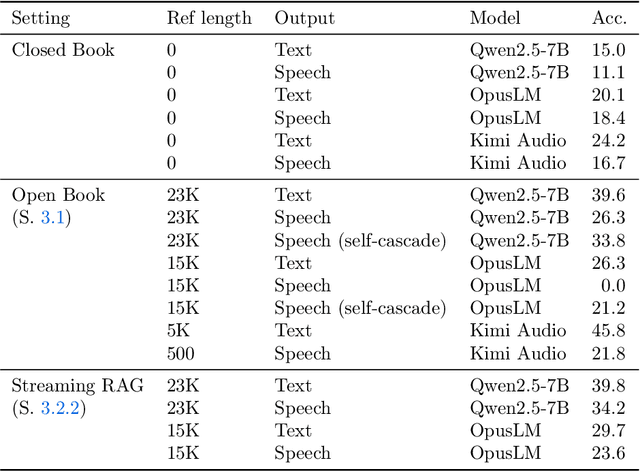
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
CardioBench: Do Echocardiography Foundation Models Generalize Beyond the Lab?
Oct 01, 2025Foundation models (FMs) are reshaping medical imaging, yet their application in echocardiography remains limited. While several echocardiography-specific FMs have recently been introduced, no standardized benchmark exists to evaluate them. Echocardiography poses unique challenges, including noisy acquisitions, high frame redundancy, and limited public datasets. Most existing solutions evaluate on private data, restricting comparability. To address this, we introduce CardioBench, a comprehensive benchmark for echocardiography FMs. CardioBench unifies eight publicly available datasets into a standardized suite spanning four regression and five classification tasks, covering functional, structural, diagnostic, and view recognition endpoints. We evaluate several leading FM, including cardiac-specific, biomedical, and general-purpose encoders, under consistent zero-shot, probing, and alignment protocols. Our results highlight complementary strengths across model families: temporal modeling is critical for functional regression, retrieval provides robustness under distribution shift, and domain-specific text encoders capture physiologically meaningful axes. General-purpose encoders transfer strongly and often close the gap with probing, but struggle with fine-grained distinctions like view classification and subtle pathology recognition. By releasing preprocessing, splits, and public evaluation pipelines, CardioBench establishes a reproducible reference point and offers actionable insights to guide the design of future echocardiography foundation models.
Language and Planning in Robotic Navigation: A Multilingual Evaluation of State-of-the-Art Models
Jan 07, 2025



Large Language Models (LLMs) such as GPT-4, trained on huge amount of datasets spanning multiple domains, exhibit significant reasoning, understanding, and planning capabilities across various tasks. This study presents the first-ever work in Arabic language integration within the Vision-and-Language Navigation (VLN) domain in robotics, an area that has been notably underexplored in existing research. We perform a comprehensive evaluation of state-of-the-art multi-lingual Small Language Models (SLMs), including GPT-4o mini, Llama 3 8B, and Phi-3 medium 14B, alongside the Arabic-centric LLM, Jais. Our approach utilizes the NavGPT framework, a pure LLM-based instruction-following navigation agent, to assess the impact of language on navigation reasoning through zero-shot sequential action prediction using the R2R dataset. Through comprehensive experiments, we demonstrate that our framework is capable of high-level planning for navigation tasks when provided with instructions in both English and Arabic. However, certain models struggled with reasoning and planning in the Arabic language due to inherent limitations in their capabilities, sub-optimal performance, and parsing issues. These findings highlight the importance of enhancing planning and reasoning capabilities in language models for effective navigation, emphasizing this as a key area for further development while also unlocking the potential of Arabic-language models for impactful real-world applications.
CoDi: Conversational Distillation for Grounded Question Answering
Aug 20, 2024



Distilling conversational skills into Small Language Models (SLMs) with approximately 1 billion parameters presents significant challenges. Firstly, SLMs have limited capacity in their model parameters to learn extensive knowledge compared to larger models. Secondly, high-quality conversational datasets are often scarce, small, and domain-specific. Addressing these challenges, we introduce a novel data distillation framework named CoDi (short for Conversational Distillation, pronounced "Cody"), allowing us to synthesize large-scale, assistant-style datasets in a steerable and diverse manner. Specifically, while our framework is task agnostic at its core, we explore and evaluate the potential of CoDi on the task of conversational grounded reasoning for question answering. This is a typical on-device scenario for specialist SLMs, allowing for open-domain model responses, without requiring the model to "memorize" world knowledge in its limited weights. Our evaluations show that SLMs trained with CoDi-synthesized data achieve performance comparable to models trained on human-annotated data in standard metrics. Additionally, when using our framework to generate larger datasets from web data, our models surpass larger, instruction-tuned models in zero-shot conversational grounded reasoning tasks.
PRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024



Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
Small But Funny: A Feedback-Driven Approach to Humor Distillation
Feb 28, 2024



The emergence of Large Language Models (LLMs) has brought to light promising language generation capabilities, particularly in performing tasks like complex reasoning and creative writing. Consequently, distillation through imitation of teacher responses has emerged as a popular technique to transfer knowledge from LLMs to more accessible, Small Language Models (SLMs). While this works well for simpler tasks, there is a substantial performance gap on tasks requiring intricate language comprehension and creativity, such as humor generation. We hypothesize that this gap may stem from the fact that creative tasks might be hard to learn by imitation alone and explore whether an approach, involving supplementary guidance from the teacher, could yield higher performance. To address this, we study the effect of assigning a dual role to the LLM - as a "teacher" generating data, as well as a "critic" evaluating the student's performance. Our experiments on humor generation reveal that the incorporation of feedback significantly narrows the performance gap between SLMs and their larger counterparts compared to merely relying on imitation. As a result, our research highlights the potential of using feedback as an additional dimension to data when transferring complex language abilities via distillation.
Retrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022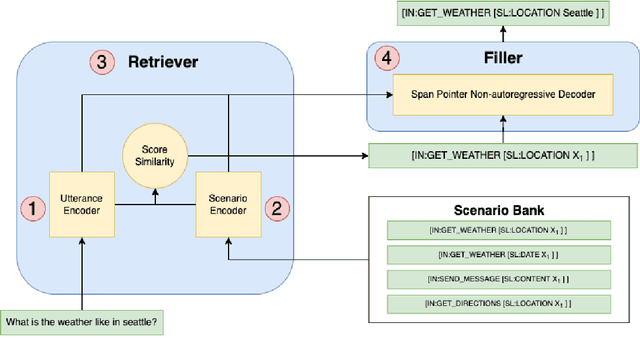
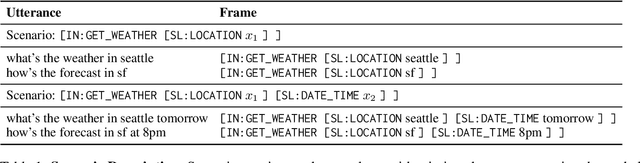
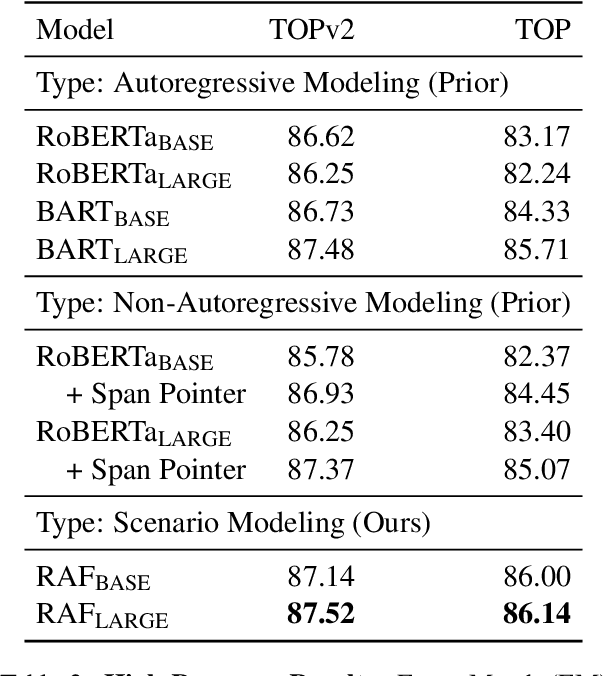

Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.