 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistantly-Supervised Named Entity Recognition with Adaptive Teacher Learning and Fine-grained Student Ensemble
Dec 13, 2022Distantly-Supervised Named Entity Recognition (DS-NER) effectively alleviates the data scarcity problem in NER by automatically generating training samples. Unfortunately, the distant supervision may induce noisy labels, thus undermining the robustness of the learned models and restricting the practical application. To relieve this problem, recent works adopt self-training teacher-student frameworks to gradually refine the training labels and improve the generalization ability of NER models. However, we argue that the performance of the current self-training frameworks for DS-NER is severely underestimated by their plain designs, including both inadequate student learning and coarse-grained teacher updating. Therefore, in this paper, we make the first attempt to alleviate these issues by proposing: (1) adaptive teacher learning comprised of joint training of two teacher-student networks and considering both consistent and inconsistent predictions between two teachers, thus promoting comprehensive student learning. (2) fine-grained student ensemble that updates each fragment of the teacher model with a temporal moving average of the corresponding fragment of the student, which enhances consistent predictions on each model fragment against noise. To verify the effectiveness of our proposed method, we conduct experiments on four DS-NER datasets. The experimental results demonstrate that our method significantly surpasses previous SOTA methods.
MetaFormer Baselines for Vision
Oct 24, 2022



MetaFormer, the abstracted architecture of Transformer, has been found to play a significant role in achieving competitive performance. In this paper, we further explore the capacity of MetaFormer, again, without focusing on token mixer design: we introduce several baseline models under MetaFormer using the most basic or common mixers, and summarize our observations as follows: (1) MetaFormer ensures solid lower bound of performance. By merely adopting identity mapping as the token mixer, the MetaFormer model, termed IdentityFormer, achieves >80% accuracy on ImageNet-1K. (2) MetaFormer works well with arbitrary token mixers. When specifying the token mixer as even a random matrix to mix tokens, the resulting model RandFormer yields an accuracy of >81%, outperforming IdentityFormer. Rest assured of MetaFormer's results when new token mixers are adopted. (3) MetaFormer effortlessly offers state-of-the-art results. With just conventional token mixers dated back five years ago, the models instantiated from MetaFormer already beat state of the art. (a) ConvFormer outperforms ConvNeXt. Taking the common depthwise separable convolutions as the token mixer, the model termed ConvFormer, which can be regarded as pure CNNs, outperforms the strong CNN model ConvNeXt. (b) CAFormer sets new record on ImageNet-1K. By simply applying depthwise separable convolutions as token mixer in the bottom stages and vanilla self-attention in the top stages, the resulting model CAFormer sets a new record on ImageNet-1K: it achieves an accuracy of 85.5% at 224x224 resolution, under normal supervised training without external data or distillation. In our expedition to probe MetaFormer, we also find that a new activation, StarReLU, reduces 71% FLOPs of activation compared with GELU yet achieves better performance. We expect StarReLU to find great potential in MetaFormer-like models alongside other neural networks.
LPT: Long-tailed Prompt Tuning for Image Classification
Oct 03, 2022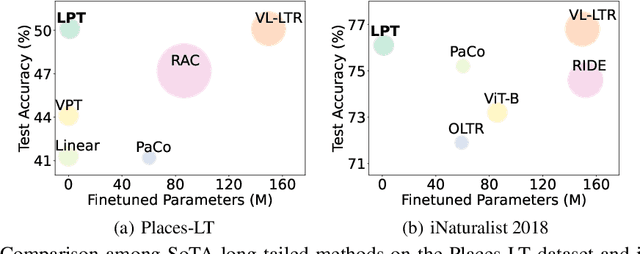
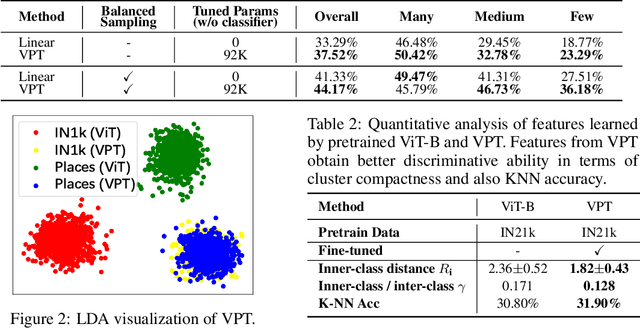
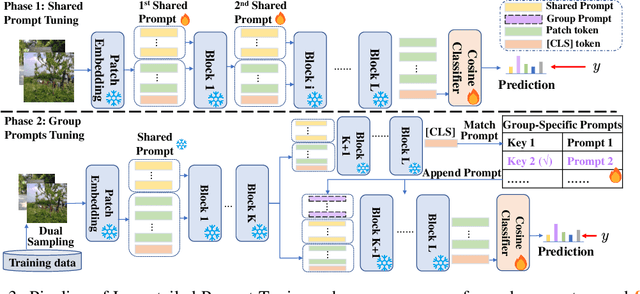
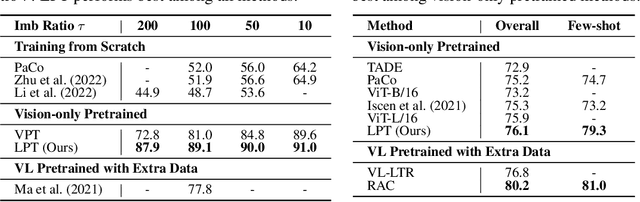
For long-tailed classification, most works often pretrain a big model on a large-scale dataset, and then fine-tune the whole model for adapting to long-tailed data. Though promising, fine-tuning the whole pretrained model tends to suffer from high cost in computation and deployment of different models for different tasks, as well as weakened generalization ability for overfitting to certain features of long-tailed data. To alleviate these issues, we propose an effective Long-tailed Prompt Tuning method for long-tailed classification. LPT introduces several trainable prompts into a frozen pretrained model to adapt it to long-tailed data. For better effectiveness, we divide prompts into two groups: 1) a shared prompt for the whole long-tailed dataset to learn general features and to adapt a pretrained model into target domain; and 2) group-specific prompts to gather group-specific features for the samples which have similar features and also to empower the pretrained model with discrimination ability. Then we design a two-phase training paradigm to learn these prompts. In phase 1, we train the shared prompt via supervised prompt tuning to adapt a pretrained model to the desired long-tailed domain. In phase 2, we use the learnt shared prompt as query to select a small best matched set for a group of similar samples from the group-specific prompt set to dig the common features of these similar samples, then optimize these prompts with dual sampling strategy and asymmetric GCL loss. By only fine-tuning a few prompts while fixing the pretrained model, LPT can reduce training and deployment cost by storing a few prompts, and enjoys a strong generalization ability of the pretrained model. Experiments show that on various long-tailed benchmarks, with only ~1.1% extra parameters, LPT achieves comparable performance than previous whole model fine-tuning methods, and is more robust to domain-shift.
Multi-Modal Cross-Domain Alignment Network for Video Moment Retrieval
Sep 23, 2022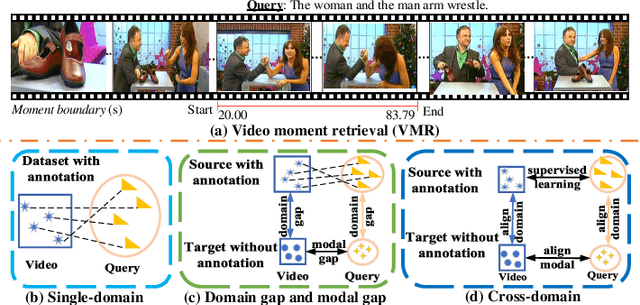
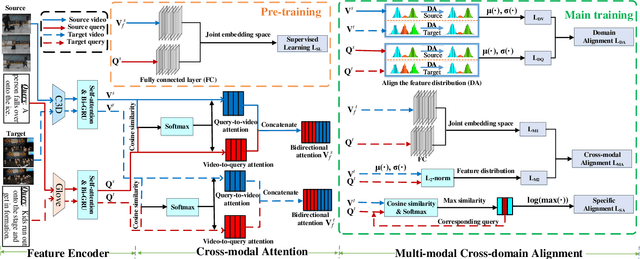
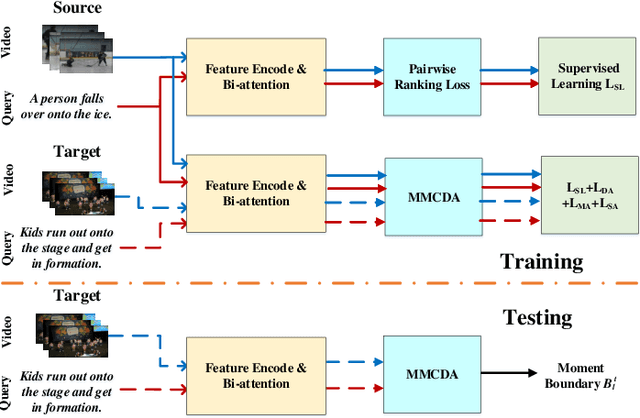
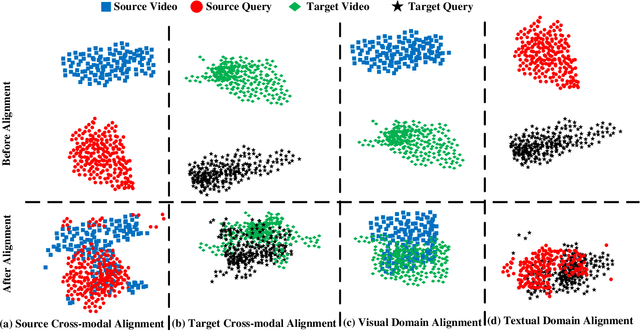
As an increasingly popular task in multimedia information retrieval, video moment retrieval (VMR) aims to localize the target moment from an untrimmed video according to a given language query. Most previous methods depend heavily on numerous manual annotations (i.e., moment boundaries), which are extremely expensive to acquire in practice. In addition, due to the domain gap between different datasets, directly applying these pre-trained models to an unseen domain leads to a significant performance drop. In this paper, we focus on a novel task: cross-domain VMR, where fully-annotated datasets are available in one domain (``source domain''), but the domain of interest (``target domain'') only contains unannotated datasets. As far as we know, we present the first study on cross-domain VMR. To address this new task, we propose a novel Multi-Modal Cross-Domain Alignment (MMCDA) network to transfer the annotation knowledge from the source domain to the target domain. However, due to the domain discrepancy between the source and target domains and the semantic gap between videos and queries, directly applying trained models to the target domain generally leads to a performance drop. To solve this problem, we develop three novel modules: (i) a domain alignment module is designed to align the feature distributions between different domains of each modality; (ii) a cross-modal alignment module aims to map both video and query features into a joint embedding space and to align the feature distributions between different modalities in the target domain; (iii) a specific alignment module tries to obtain the fine-grained similarity between a specific frame and the given query for optimal localization. By jointly training these three modules, our MMCDA can learn domain-invariant and semantic-aligned cross-modal representations.
Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
Sep 01, 2022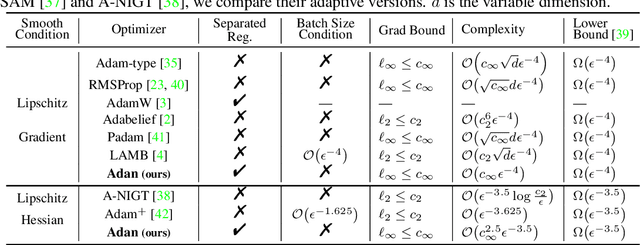
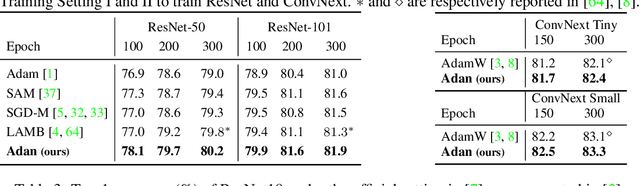
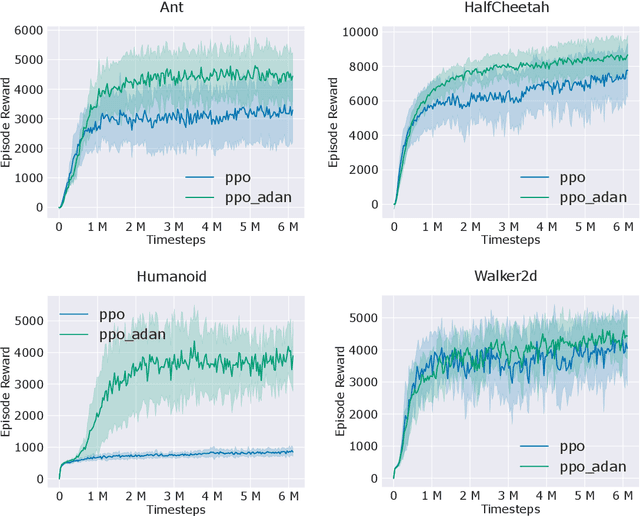
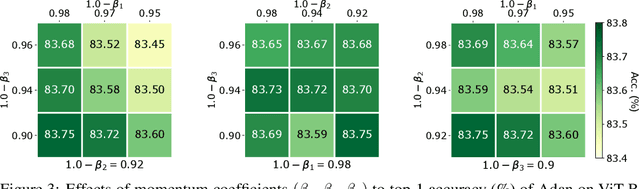
Adaptive gradient algorithms borrow the moving average idea of heavy ball acceleration to estimate accurate first- and second-order moments of gradient for accelerating convergence. However, Nesterov acceleration which converges faster than heavy ball acceleration in theory and also in many empirical cases is much less investigated under the adaptive gradient setting. In this work, we propose the ADAptive Nesterov momentum algorithm, Adan for short, to speed up the training of deep neural networks effectively. Adan first reformulates the vanilla Nesterov acceleration to develop a new Nesterov momentum estimation (NME) method, which avoids the extra computation and memory overhead of computing gradient at the extrapolation point. Then Adan adopts NME to estimate the first- and second-order moments of the gradient in adaptive gradient algorithms for convergence acceleration. Besides, we prove that Adan finds an $\epsilon$-approximate first-order stationary point within $O(\epsilon^{-3.5})$ stochastic gradient complexity on the nonconvex stochastic problems (e.g., deep learning problems), matching the best-known lower bound. Extensive experimental results show that Adan surpasses the corresponding SoTA optimizers on both vision transformers (ViTs) and CNNs, and sets new SoTAs for many popular networks, e.g., ResNet, ConvNext, ViT, Swin, MAE, LSTM, Transformer-XL, and BERT. More surprisingly, Adan can use half of the training cost (epochs) of SoTA optimizers to achieve higher or comparable performance on ViT and ResNet, e.t.c., and also shows great tolerance to a large range of minibatch size, e.g., from 1k to 32k. We hope Adan can contribute to the development of deep learning by reducing training cost and relieving engineering burden of trying different optimizers on various architectures. Code is released at https://github.com/sail-sg/Adan.
Hierarchical Local-Global Transformer for Temporal Sentence Grounding
Aug 31, 2022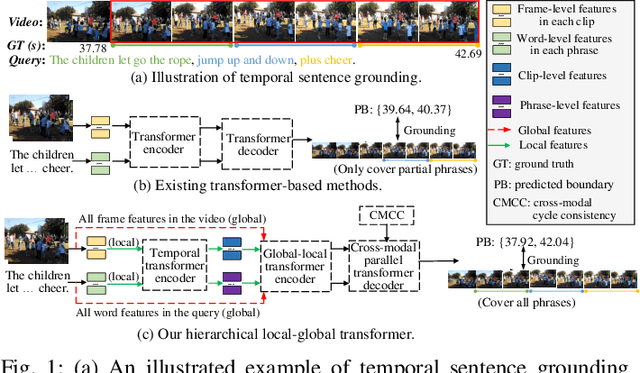
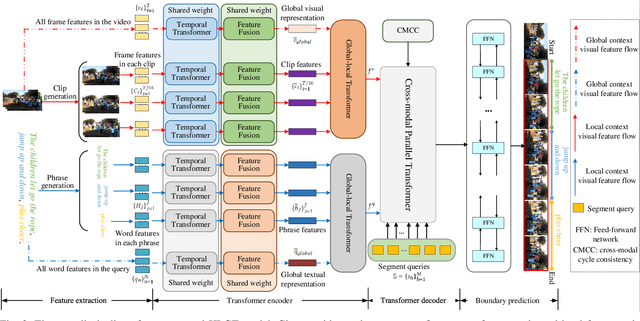
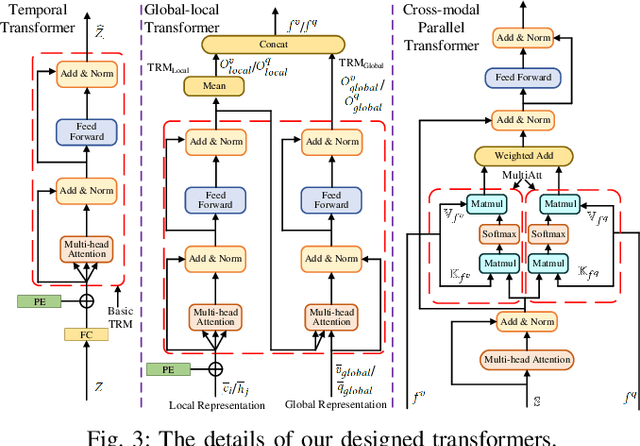
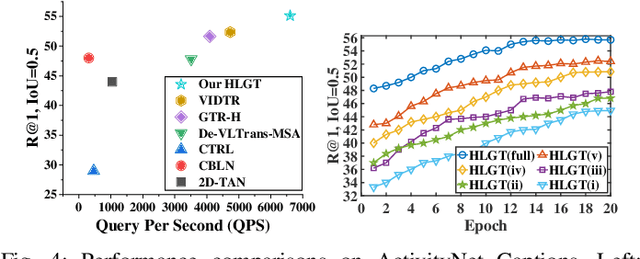
This paper studies the multimedia problem of temporal sentence grounding (TSG), which aims to accurately determine the specific video segment in an untrimmed video according to a given sentence query. Traditional TSG methods mainly follow the top-down or bottom-up framework and are not end-to-end. They severely rely on time-consuming post-processing to refine the grounding results. Recently, some transformer-based approaches are proposed to efficiently and effectively model the fine-grained semantic alignment between video and query. Although these methods achieve significant performance to some extent, they equally take frames of the video and words of the query as transformer input for correlating, failing to capture their different levels of granularity with distinct semantics. To address this issue, in this paper, we propose a novel Hierarchical Local-Global Transformer (HLGT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities for learning more fine-grained multi-modal representations. Specifically, we first split the video and query into individual clips and phrases to learn their local context (adjacent dependency) and global correlation (long-range dependency) via a temporal transformer. Then, a global-local transformer is introduced to learn the interactions between the local-level and global-level semantics for better multi-modal reasoning. Besides, we develop a new cross-modal cycle-consistency loss to enforce interaction between two modalities and encourage the semantic alignment between them. Finally, we design a brand-new cross-modal parallel transformer decoder to integrate the encoded visual and textual features for final grounding. Extensive experiments on three challenging datasets show that our proposed HLGT achieves a new state-of-the-art performance.
Video Graph Transformer for Video Question Answering
Jul 18, 2022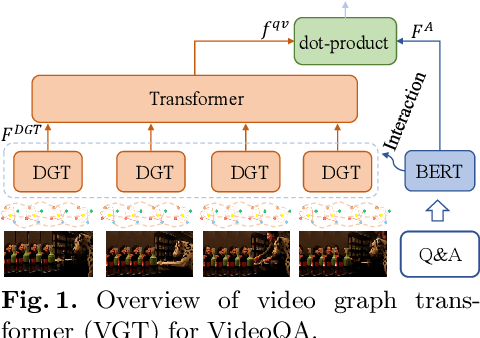
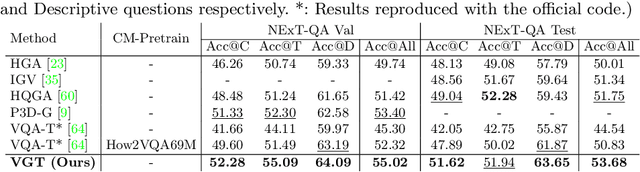
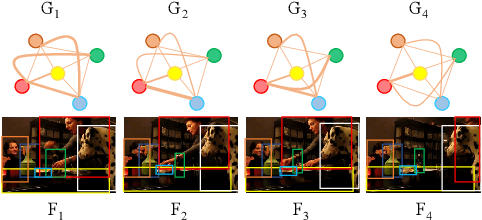
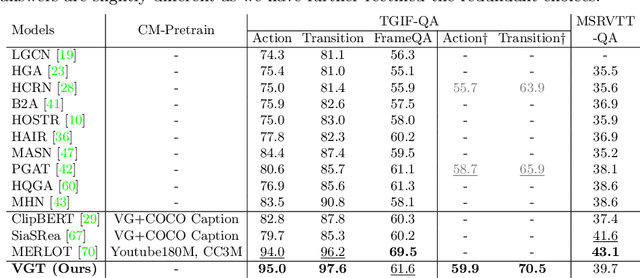
This paper proposes a Video Graph Transformer (VGT) model for Video Quetion Answering (VideoQA). VGT's uniqueness are two-fold: 1) it designs a dynamic graph transformer module which encodes video by explicitly capturing the visual objects, their relations, and dynamics for complex spatio-temporal reasoning; and 2) it exploits disentangled video and text Transformers for relevance comparison between the video and text to perform QA, instead of entangled cross-modal Transformer for answer classification. Vision-text communication is done by additional cross-modal interaction modules. With more reasonable video encoding and QA solution, we show that VGT can achieve much better performances on VideoQA tasks that challenge dynamic relation reasoning than prior arts in the pretraining-free scenario. Its performances even surpass those models that are pretrained with millions of external data. We further show that VGT can also benefit a lot from self-supervised cross-modal pretraining, yet with orders of magnitude smaller data. These results clearly demonstrate the effectiveness and superiority of VGT, and reveal its potential for more data-efficient pretraining. With comprehensive analyses and some heuristic observations, we hope that VGT can promote VQA research beyond coarse recognition/description towards fine-grained relation reasoning in realistic videos. Our code is available at https://github.com/sail-sg/VGT.
Backdoor Attacks on Crowd Counting
Jul 12, 2022
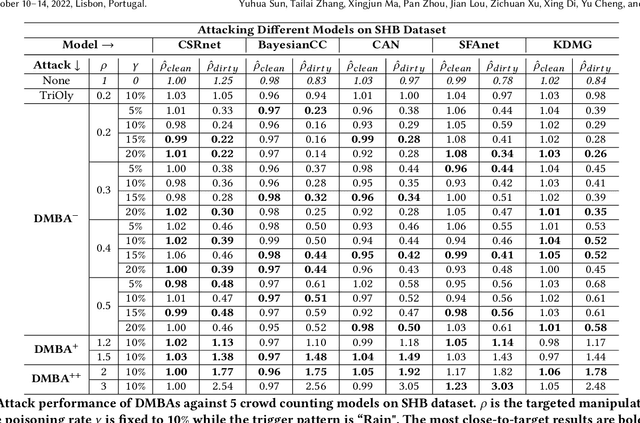
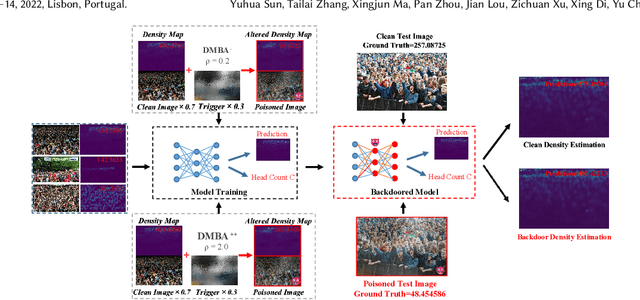
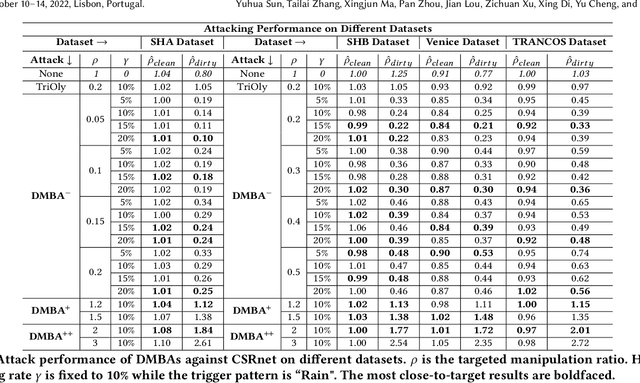
Crowd counting is a regression task that estimates the number of people in a scene image, which plays a vital role in a range of safety-critical applications, such as video surveillance, traffic monitoring and flow control. In this paper, we investigate the vulnerability of deep learning based crowd counting models to backdoor attacks, a major security threat to deep learning. A backdoor attack implants a backdoor trigger into a target model via data poisoning so as to control the model's predictions at test time. Different from image classification models on which most of existing backdoor attacks have been developed and tested, crowd counting models are regression models that output multi-dimensional density maps, thus requiring different techniques to manipulate. In this paper, we propose two novel Density Manipulation Backdoor Attacks (DMBA$^{-}$ and DMBA$^{+}$) to attack the model to produce arbitrarily large or small density estimations. Experimental results demonstrate the effectiveness of our DMBA attacks on five classic crowd counting models and four types of datasets. We also provide an in-depth analysis of the unique challenges of backdooring crowd counting models and reveal two key elements of effective attacks: 1) full and dense triggers and 2) manipulation of the ground truth counts or density maps. Our work could help evaluate the vulnerability of crowd counting models to potential backdoor attacks.
Gaussian Kernel-based Cross Modal Network for Spatio-Temporal Video Grounding
Jul 02, 2022
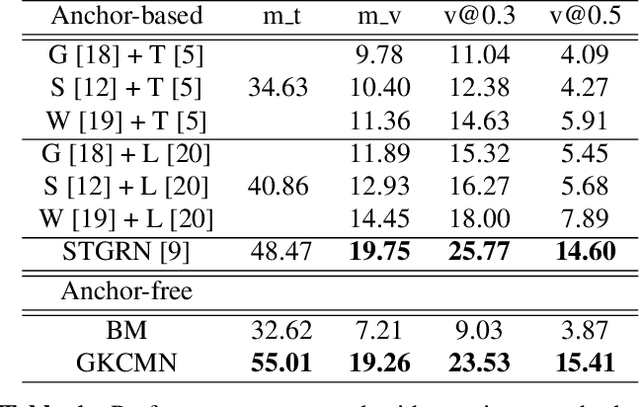
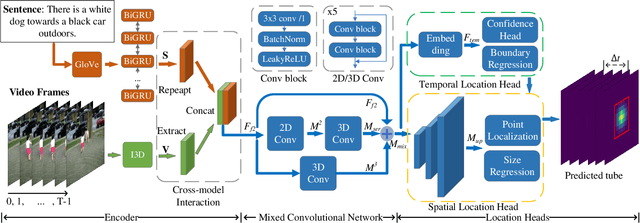
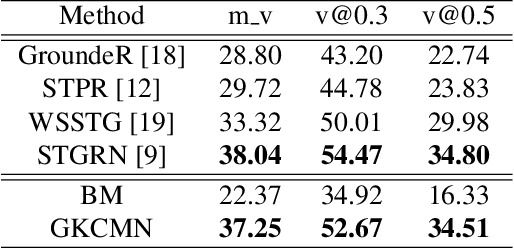
Spatial-Temporal Video Grounding (STVG) is a challenging task which aims to localize the spatio-temporal tube of the interested object semantically according to a natural language query. Most previous works not only severely rely on the anchor boxes extracted by Faster R-CNN, but also simply regard the video as a series of individual frames, thus lacking their temporal modeling. Instead, in this paper, we are the first to propose an anchor-free framework for STVG, called Gaussian Kernel-based Cross Modal Network (GKCMN). Specifically, we utilize the learned Gaussian Kernel-based heatmaps of each video frame to locate the query-related object. A mixed serial and parallel connection network is further developed to leverage both spatial and temporal relations among frames for better grounding. Experimental results on VidSTG dataset demonstrate the effectiveness of our proposed GKCMN.
Towards Understanding Why Mask-Reconstruction Pretraining Helps in Downstream Tasks
Jun 14, 2022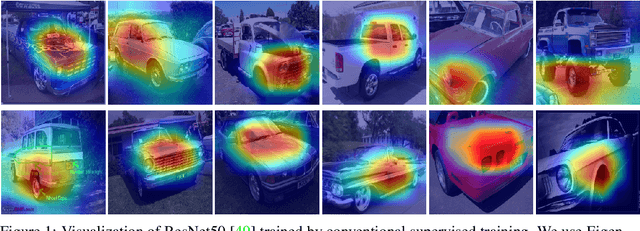

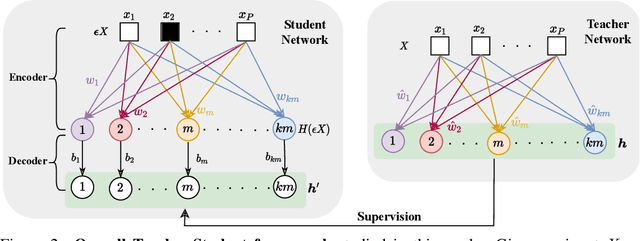
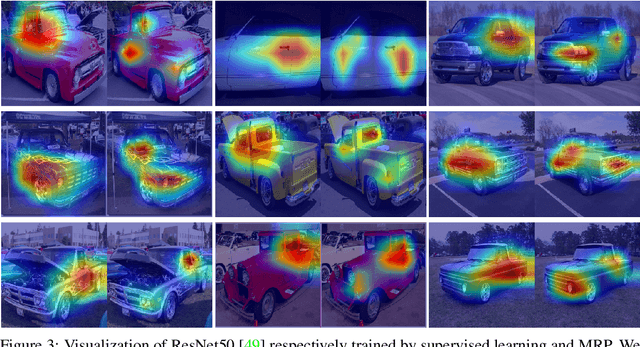
For unsupervised pretraining, mask-reconstruction pretraining (MRP) approaches randomly mask input patches and then reconstruct pixels or semantic features of these masked patches via an auto-encoder. Then for a downstream task, supervised fine-tuning the pretrained encoder remarkably surpasses the conventional supervised learning (SL) trained from scratch. However, it is still unclear 1) how MRP performs semantic learning in the pretraining phase and 2) why it helps in downstream tasks. To solve these problems, we theoretically show that on an auto-encoder of a two/one-layered convolution encoder/decoder, MRP can capture all discriminative semantics in the pretraining dataset, and accordingly show its provable improvement over SL on the classification downstream task. Specifically, we assume that pretraining dataset contains multi-view samples of ratio $1-\mu$ and single-view samples of ratio $\mu$, where multi/single-view samples has multiple/single discriminative semantics. Then for pretraining, we prove that 1) the convolution kernels of the MRP encoder captures all discriminative semantics in the pretraining data; and 2) a convolution kernel captures at most one semantic. Accordingly, in the downstream supervised fine-tuning, most semantics would be captured and different semantics would not be fused together. This helps the downstream fine-tuned network to easily establish the relation between kernels and semantic class labels. In this way, the fine-tuned encoder in MRP provably achieves zero test error with high probability for both multi-view and single-view test data. In contrast, as proved by~[3], conventional SL can only obtain a test accuracy between around $0.5\mu$ for single-view test data. These results together explain the benefits of MRP in downstream tasks. Experimental results testify to multi-view data assumptions and our theoretical implications.