 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSNet: Compression of Deep Convolutional Neural Networks by Filter Summary
Feb 13, 2019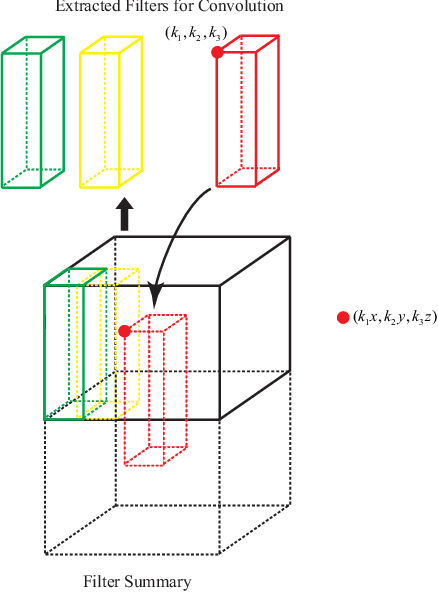
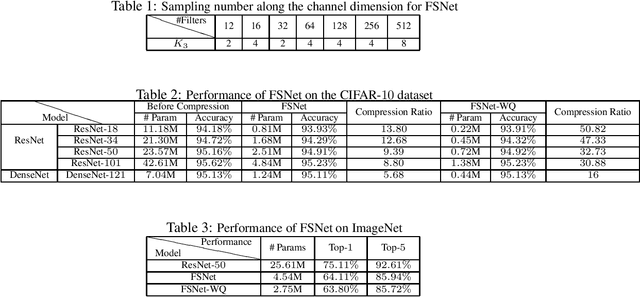
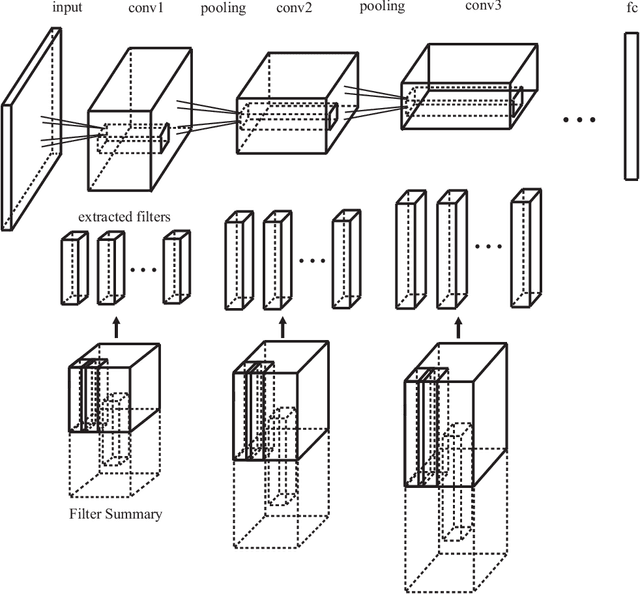
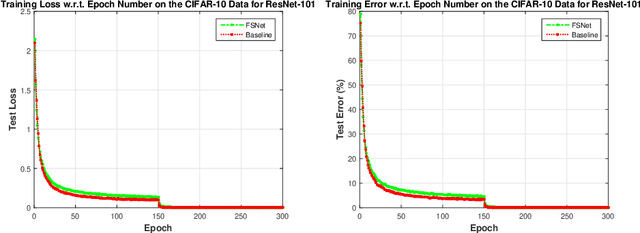
We present a novel method of compression of deep Convolutional Neural Networks (CNNs). Our method reduces the number of parameters of each convolutional layer by learning a 3D tensor termed Filter Summary (FS). The convolutional filters are extracted from FS as overlapping 3D blocks, and nearby filters in FS share weights in their overlapping regions in a natural way. The resultant neural network based on such weight sharing scheme, termed Filter Summary CNNs or FSNet, has a FS in each convolution layer instead of a set of independent filters in the conventional convolution layer. FSNet has the same architecture as that of the baseline CNN to be compressed, and each convolution layer of FSNet generates the same number of filters from FS as that of the basline CNN in the forward process. Without hurting the inference speed, the parameter space of FSNet is much smaller than that of the baseline CNN. In addition, FSNet is compatible with weight quantization, leading to even higher compression ratio when combined with weight quantization. Experiments demonstrate the effectiveness of FSNet in compression of CNNs for computer vision tasks including image classification and object detection. For classification task, FSNet of 0.22M effective parameters has prediction accuracy of 93.91% on the CIFAR-10 dataset with less than 0.3% accuracy drop, using ResNet-18 of 11.18M parameters as baseline. Furthermore, FSNet version of ResNet-50 with 2.75M effective parameters achieves the top-1 and top-5 accuracy of 63.80% and 85.72% respectively on ILSVRC-12 benchmark. For object detection task, FSNet is used to compress the Single Shot MultiBox Detector (SSD300) of 26.32M parameters. FSNet of 0.45M effective parameters achieves mAP of 67.63% on the VOC2007 test data with weight quantization, and FSNet of 0.68M effective parameters achieves mAP of 70.00% with weight quantization on the same test data.
WSNet: Compact and Efficient Networks Through Weight Sampling
May 22, 2018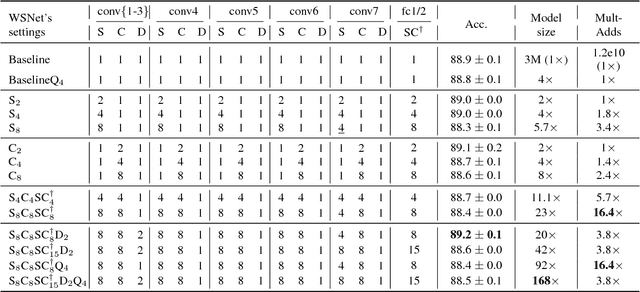
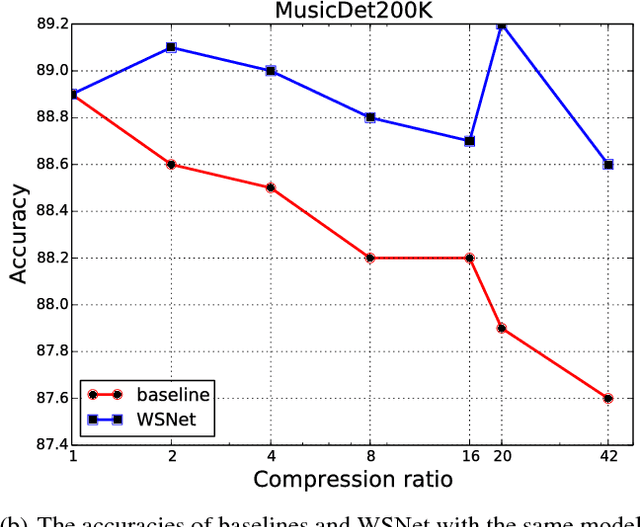

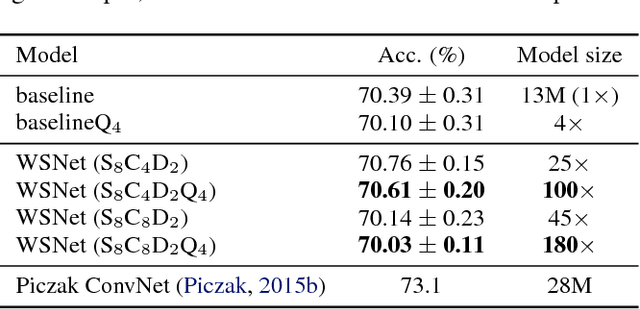
We present a new approach and a novel architecture, termed WSNet, for learning compact and efficient deep neural networks. Existing approaches conventionally learn full model parameters independently and then compress them via ad hoc processing such as model pruning or filter factorization. Alternatively, WSNet proposes learning model parameters by sampling from a compact set of learnable parameters, which naturally enforces {parameter sharing} throughout the learning process. We demonstrate that such a novel weight sampling approach (and induced WSNet) promotes both weights and computation sharing favorably. By employing this method, we can more efficiently learn much smaller networks with competitive performance compared to baseline networks with equal numbers of convolution filters. Specifically, we consider learning compact and efficient 1D convolutional neural networks for audio classification. Extensive experiments on multiple audio classification datasets verify the effectiveness of WSNet. Combined with weight quantization, the resulted models are up to 180 times smaller and theoretically up to 16 times faster than the well-established baselines, without noticeable performance drop.
Iterative Refinement of the Approximate Posterior for Directed Belief Networks
Feb 20, 2018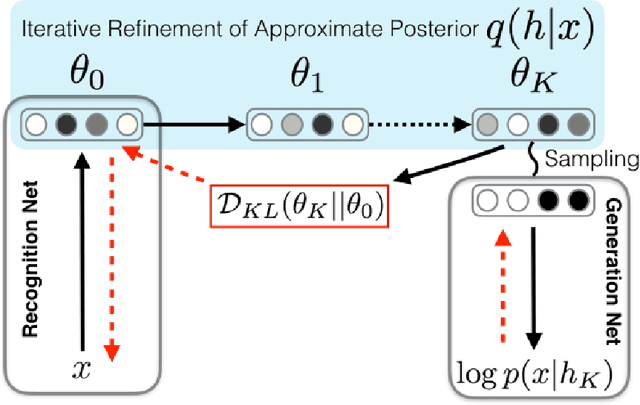
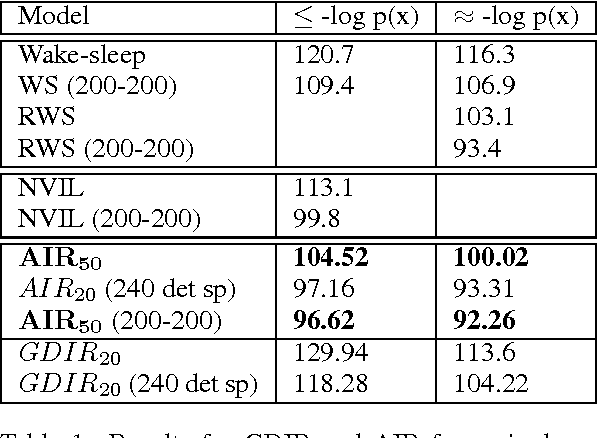

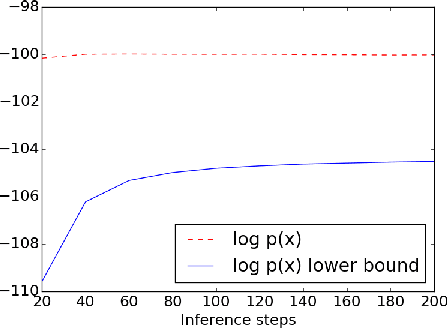
Variational methods that rely on a recognition network to approximate the posterior of directed graphical models offer better inference and learning than previous methods. Recent advances that exploit the capacity and flexibility in this approach have expanded what kinds of models can be trained. However, as a proposal for the posterior, the capacity of the recognition network is limited, which can constrain the representational power of the generative model and increase the variance of Monte Carlo estimates. To address these issues, we introduce an iterative refinement procedure for improving the approximate posterior of the recognition network and show that training with the refined posterior is competitive with state-of-the-art methods. The advantages of refinement are further evident in an increased effective sample size, which implies a lower variance of gradient estimates.
Discovering Order in Unordered Datasets: Generative Markov Networks
Feb 15, 2018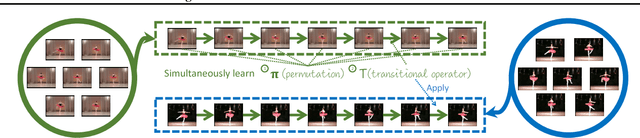
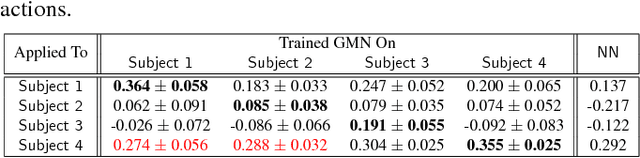

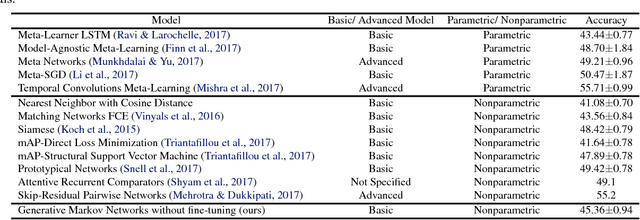
The assumption that data samples are independently identically distributed is the backbone of many learning algorithms. Nevertheless, datasets often exhibit rich structures in practice, and we argue that there exist some unknown orders within the data instances. Aiming to find such orders, we introduce a novel Generative Markov Network (GMN) which we use to extract the order of data instances automatically. Specifically, we assume that the instances are sampled from a Markov chain. Our goal is to learn the transitional operator of the chain as well as the generation order by maximizing the generation probability under all possible data permutations. One of our key ideas is to use neural networks as a soft lookup table for approximating the possibly huge, but discrete transition matrix. This strategy allows us to amortize the space complexity with a single model and make the transitional operator generalizable to unseen instances. To ensure the learned Markov chain is ergodic, we propose a greedy batch-wise permutation scheme that allows fast training. Empirically, we evaluate the learned Markov chain by showing that GMNs are able to discover orders among data instances and also perform comparably well to state-of-the-art methods on the one-shot recognition benchmark task.
Steering Output Style and Topic in Neural Response Generation
Sep 09, 2017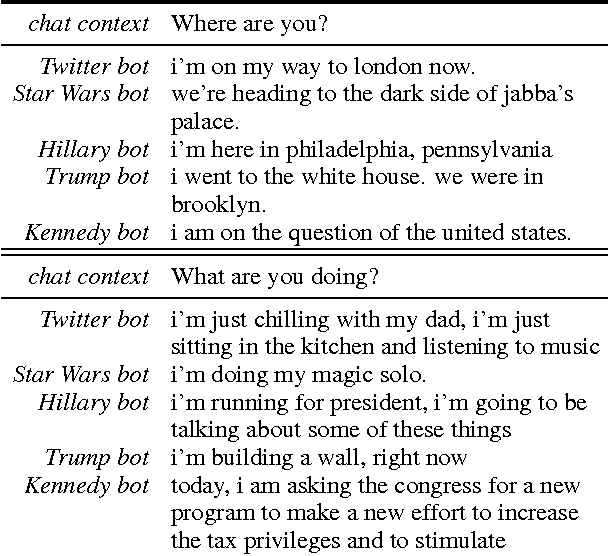
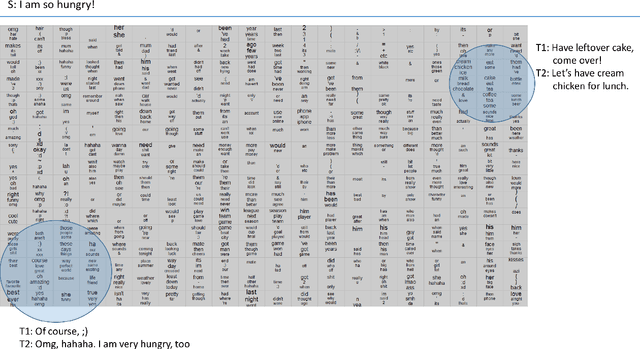
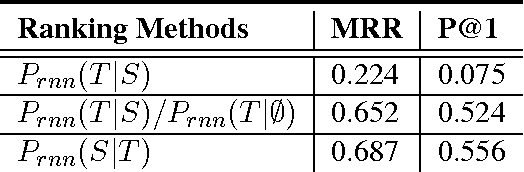
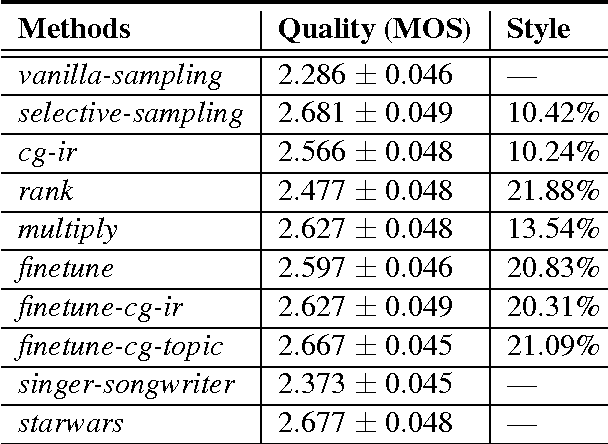
We propose simple and flexible training and decoding methods for influencing output style and topic in neural encoder-decoder based language generation. This capability is desirable in a variety of applications, including conversational systems, where successful agents need to produce language in a specific style and generate responses steered by a human puppeteer or external knowledge. We decompose the neural generation process into empirically easier sub-problems: a faithfulness model and a decoding method based on selective-sampling. We also describe training and sampling algorithms that bias the generation process with a specific language style restriction, or a topic restriction. Human evaluation results show that our proposed methods are able to restrict style and topic without degrading output quality in conversational tasks.
Discriminative Similarity for Clustering and Semi-Supervised Learning
Sep 05, 2017Similarity-based clustering and semi-supervised learning methods separate the data into clusters or classes according to the pairwise similarity between the data, and the pairwise similarity is crucial for their performance. In this paper, we propose a novel discriminative similarity learning framework which learns discriminative similarity for either data clustering or semi-supervised learning. The proposed framework learns classifier from each hypothetical labeling, and searches for the optimal labeling by minimizing the generalization error of the learned classifiers associated with the hypothetical labeling. Kernel classifier is employed in our framework. By generalization analysis via Rademacher complexity, the generalization error bound for the kernel classifier learned from hypothetical labeling is expressed as the sum of pairwise similarity between the data from different classes, parameterized by the weights of the kernel classifier. Such pairwise similarity serves as the discriminative similarity for the purpose of clustering and semi-supervised learning, and discriminative similarity with similar form can also be induced by the integrated squared error bound for kernel density classification. Based on the discriminative similarity induced by the kernel classifier, we propose new clustering and semi-supervised learning methods.
On the Suboptimality of Proximal Gradient Descent for $\ell^{0}$ Sparse Approximation
Sep 05, 2017We study the proximal gradient descent (PGD) method for $\ell^{0}$ sparse approximation problem as well as its accelerated optimization with randomized algorithms in this paper. We first offer theoretical analysis of PGD showing the bounded gap between the sub-optimal solution by PGD and the globally optimal solution for the $\ell^{0}$ sparse approximation problem under conditions weaker than Restricted Isometry Property widely used in compressive sensing literature. Moreover, we propose randomized algorithms to accelerate the optimization by PGD using randomized low rank matrix approximation (PGD-RMA) and randomized dimension reduction (PGD-RDR). Our randomized algorithms substantially reduces the computation cost of the original PGD for the $\ell^{0}$ sparse approximation problem, and the resultant sub-optimal solution still enjoys provable suboptimality, namely, the sub-optimal solution to the reduced problem still has bounded gap to the globally optimal solution to the original problem.
Hierarchical learning of grids of microtopics
Jun 08, 2016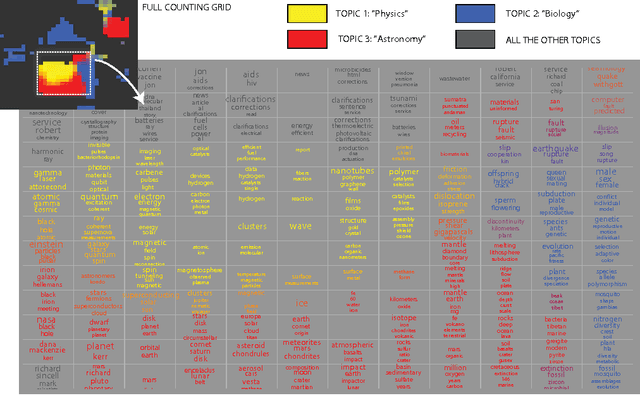

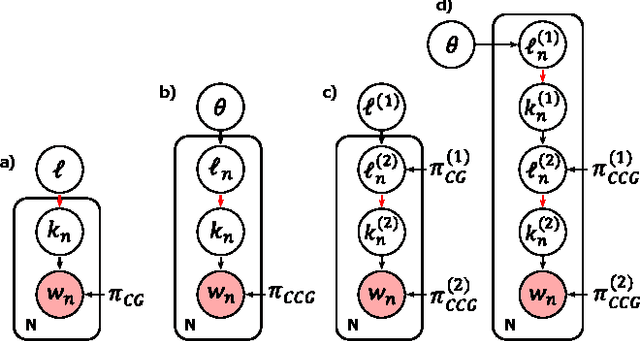
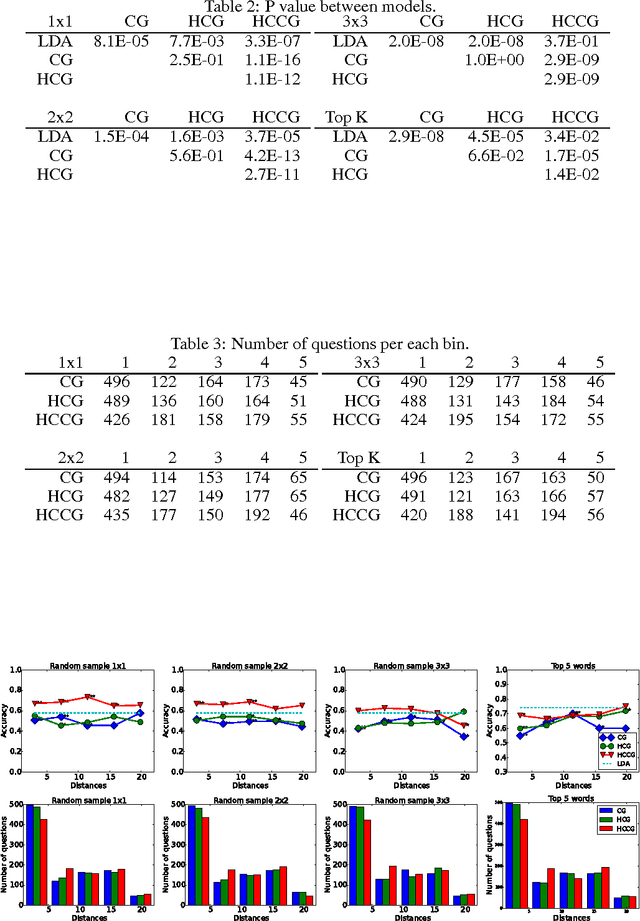
The counting grid is a grid of microtopics, sparse word/feature distributions. The generative model associated with the grid does not use these microtopics individually. Rather, it groups them in overlapping rectangular windows and uses these grouped microtopics as either mixture or admixture components. This paper builds upon the basic counting grid model and it shows that hierarchical reasoning helps avoid bad local minima, produces better classification accuracy and, most interestingly, allows for extraction of large numbers of coherent microtopics even from small datasets. We evaluate this in terms of consistency, diversity and clarity of the indexed content, as well as in a user study on word intrusion tasks. We demonstrate that these models work well as a technique for embedding raw images and discuss interesting parallels between hierarchical CG models and other deep architectures.
Capturing spatial interdependence in image features: the counting grid, an epitomic representation for bags of features
Oct 23, 2014



In recent scene recognition research images or large image regions are often represented as disorganized "bags" of features which can then be analyzed using models originally developed to capture co-variation of word counts in text. However, image feature counts are likely to be constrained in different ways than word counts in text. For example, as a camera pans upwards from a building entrance over its first few floors and then further up into the sky Fig. 1, some feature counts in the image drop while others rise -- only to drop again giving way to features found more often at higher elevations. The space of all possible feature count combinations is constrained both by the properties of the larger scene and the size and the location of the window into it. To capture such variation, in this paper we propose the use of the counting grid model. This generative model is based on a grid of feature counts, considerably larger than any of the modeled images, and considerably smaller than the real estate needed to tile the images next to each other tightly. Each modeled image is assumed to have a representative window in the grid in which the feature counts mimic the feature distribution in the image. We provide a learning procedure that jointly maps all images in the training set to the counting grid and estimates the appropriate local counts in it. Experimentally, we demonstrate that the resulting representation captures the space of feature count combinations more accurately than the traditional models, not only when the input images come from a panning camera, but even when modeling images of different scenes from the same category.
In the sight of my wearable camera: Classifying my visual experience
Apr 26, 2013

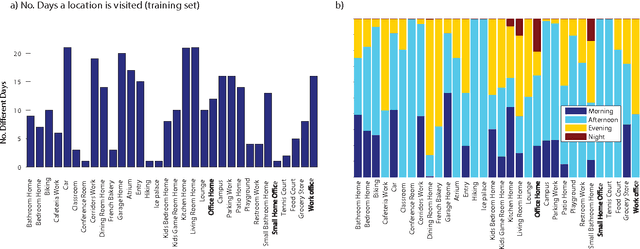

We introduce and we analyze a new dataset which resembles the input to biological vision systems much more than most previously published ones. Our analysis leaded to several important conclusions. First, it is possible to disambiguate over dozens of visual scenes (locations) encountered over the course of several weeks of a human life with accuracy of over 80%, and this opens up possibility for numerous novel vision applications, from early detection of dementia to everyday use of wearable camera streams for automatic reminders, and visual stream exchange. Second, our experimental results indicate that, generative models such as Latent Dirichlet Allocation or Counting Grids, are more suitable to such types of data, as they are more robust to overtraining and comfortable with images at low resolution, blurred and characterized by relatively random clutter and a mix of objects.