 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels Can Model, But Can't Bind: Structured Grounding in Text-to-Optimization
May 20, 2026Text-to-optimization requires two separable capabilities: modeling -- choosing the right optimization structure -- and binding -- grounding every coefficient, index, and parameter in the concrete problem data. We study this via Text2Opt-Bench, a scalable benchmark of solver-verified optimization problems spanning 12 categories, from textbook linear programs to stochastic and multi-objective formulations with up to thousands of variables. Across 10+ models, we find that accuracy collapses as instance data grows, even when the formulation itself is simple. We call this the effective binding limit. We address this via a simple inference-time approach, BIND, which externalizes numeric data to structured files so the model binds data programmatically rather than transcribing from the prompt. BIND improves GPT-5-Nano from 59.1% to 82.4% accuracy, matching pass@5 (82.0%) at lower token cost than pass@1, and GPT-5 from 86.2% to 95.8%. Furthermore, we validate our hypothesis by finetuning a model exclusively on binding and show that it outperforms end-to-end SFT and RL across three structurally distinct optimization categories, with a 1.5B binding specialist alone matching a 7B end-to-end baseline.
Hessian-Enhanced Token Attribution (HETA): Interpreting Autoregressive LLMs
Apr 14, 2026Attribution methods seek to explain language model predictions by quantifying the contribution of input tokens to generated outputs. However, most existing techniques are designed for encoder-based architectures and rely on linear approximations that fail to capture the causal and semantic complexities of autoregressive generation in decoder-only models. To address these limitations, we propose Hessian-Enhanced Token Attribution (HETA), a novel attribution framework tailored for decoder-only language models. HETA combines three complementary components: a semantic transition vector that captures token-to-token influence across layers, Hessian-based sensitivity scores that model second-order effects, and KL divergence to measure information loss when tokens are masked. This unified design produces context-aware, causally faithful, and semantically grounded attributions. Additionally, we introduce a curated benchmark dataset for systematically evaluating attribution quality in generative settings. Empirical evaluations across multiple models and datasets demonstrate that HETA consistently outperforms existing methods in attribution faithfulness and alignment with human annotations, establishing a new standard for interpretability in autoregressive language models.
ShieldNet: Network-Level Guardrails against Emerging Supply-Chain Injections in Agentic Systems
Apr 06, 2026Existing research on LLM agent security mainly focuses on prompt injection and unsafe input/output behaviors. However, as agents increasingly rely on third-party tools and MCP servers, a new class of supply-chain threats has emerged, where malicious behaviors are embedded in seemingly benign tools, silently hijacking agent execution, leaking sensitive data, or triggering unauthorized actions. Despite their growing impact, there is currently no comprehensive benchmark for evaluating such threats. To bridge this gap, we introduce SC-Inject-Bench, a large-scale benchmark comprising over 10,000 malicious MCP tools grounded in a taxonomy of 25+ attack types derived from MITRE ATT&CK targeting supply-chain threats. We observe that existing MCP scanners and semantic guardrails perform poorly on this benchmark. Motivated by this finding, we propose ShieldNet, a network-level guardrail framework that detects supply-chain poisoning by observing real network interactions rather than surface-level tool traces. ShieldNet integrates a man-in-the-middle (MITM) proxy and an event extractor to identify critical network behaviors, which are then processed by a lightweight classifier for attack detection. Extensive experiments show that ShieldNet achieves strong detection performance (up to 0.995 F-1 with only 0.8% false positives) while introducing little runtime overhead, substantially outperforming existing MCP scanners and LLM-based guardrails.
SCoOP: Semantic Consistent Opinion Pooling for Uncertainty Quantification in Multiple Vision-Language Model Systems
Mar 25, 2026Combining multiple Vision-Language Models (VLMs) can enhance multimodal reasoning and robustness, but aggregating heterogeneous models' outputs amplifies uncertainty and increases the risk of hallucinations. We propose SCoOP (Semantic-Consistent Opinion Pooling), a training-free uncertainty quantification (UQ) framework multi-VLM systems through uncertainty-weighted linear opinion pooling. Unlike prior UQ methods designed for single models, SCoOP explicitly measures collective, system-level uncertainty across multiple VLMs, enabling effective hallucination detection and abstention for highly uncertain samples. On ScienceQA, SCoOP achieves an AUROC of 0.866 for hallucination detection, outperforming baselines (0.732-0.757) by approximately 10-13%. For abstention, it attains an AURAC of 0.907, exceeding baselines (0.818-0.840) by 7-9%. Despite these gains, SCoOP introduces only microsecond-level aggregation overhead relative to the baselines, which is trivial compared to typical VLM inference time (on the order of seconds). These results demonstrate that SCoOP provides an efficient and principled mechanism for uncertainty-aware aggregation, advancing the reliability of multimodal AI systems.
$n$-Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models
Feb 09, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) shows that small, specialized language models (SLMs) can exhibit structured reasoning without relying on large monolithic LLMs. We introduce soft hidden-state collaboration, where multiple heterogeneous frozen SLM experts are integrated through their internal representations via a trainable attention interface. Experiments on Reasoning Gym and GSM8K show that this latent integration is competitive with strong single-model RLVR baselines. Ablations further reveal a dual mechanism of expert utilization: for simpler arithmetic domains, performance gains can largely be explained by static expert preferences, whereas more challenging settings induce increasingly concentrated and structured expert attention over training, indicating emergent specialization in how the router connects to relevant experts. Overall, hidden-state collaboration provides a compact mechanism for leveraging frozen experts, while offering an observational window into expert utilization patterns and their evolution under RLVR.
ACDZero: Graph-Embedding-Based Tree Search for Mastering Automated Cyber Defense
Jan 05, 2026Automated cyber defense (ACD) seeks to protect computer networks with minimal or no human intervention, reacting to intrusions by taking corrective actions such as isolating hosts, resetting services, deploying decoys, or updating access controls. However, existing approaches for ACD, such as deep reinforcement learning (RL), often face difficult exploration in complex networks with large decision/state spaces and thus require an expensive amount of samples. Inspired by the need to learn sample-efficient defense policies, we frame ACD in CAGE Challenge 4 (CAGE-4 / CC4) as a context-based partially observable Markov decision problem and propose a planning-centric defense policy based on Monte Carlo Tree Search (MCTS). It explicitly models the exploration-exploitation tradeoff in ACD and uses statistical sampling to guide exploration and decision making. We make novel use of graph neural networks (GNNs) to embed observations from the network as attributed graphs, to enable permutation-invariant reasoning over hosts and their relationships. To make our solution practical in complex search spaces, we guide MCTS with learned graph embeddings and priors over graph-edit actions, combining model-free generalization and policy distillation with look-ahead planning. We evaluate the resulting agent on CC4 scenarios involving diverse network structures and adversary behaviors, and show that our search-guided, graph-embedding-based planning improves defense reward and robustness relative to state-of-the-art RL baselines.
LogHD: Robust Compression of Hyperdimensional Classifiers via Logarithmic Class-Axis Reduction
Nov 06, 2025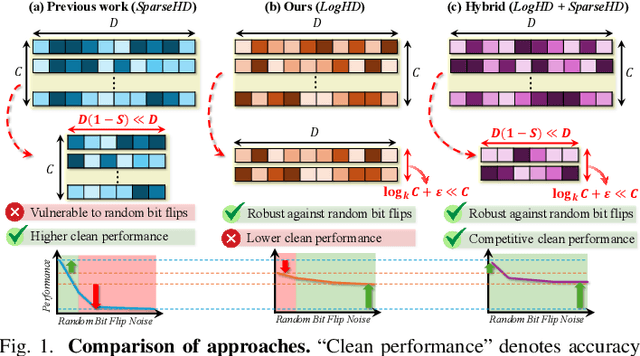
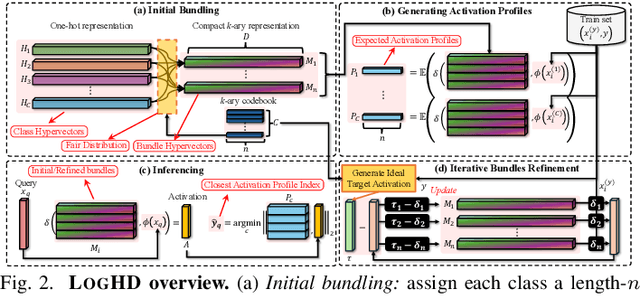
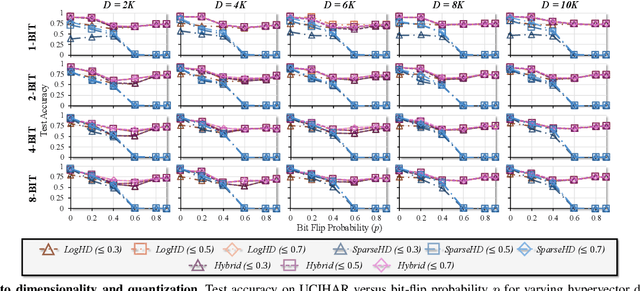
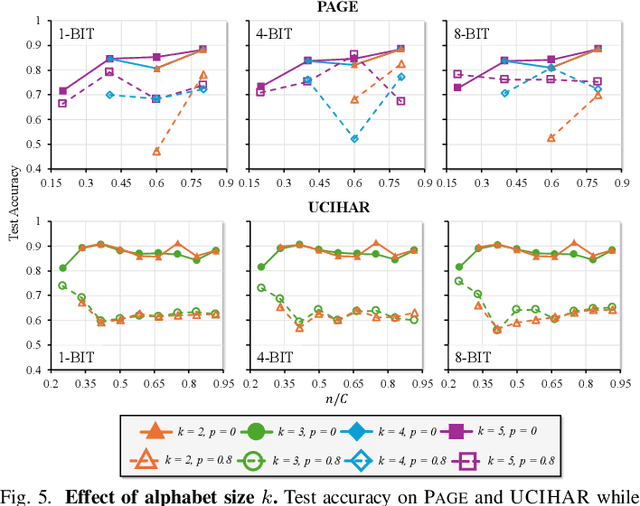
Hyperdimensional computing (HDC) suits memory, energy, and reliability-constrained systems, yet the standard "one prototype per class" design requires $O(CD)$ memory (with $C$ classes and dimensionality $D$). Prior compaction reduces $D$ (feature axis), improving storage/compute but weakening robustness. We introduce LogHD, a logarithmic class-axis reduction that replaces the $C$ per-class prototypes with $n\!\approx\!\lceil\log_k C\rceil$ bundle hypervectors (alphabet size $k$) and decodes in an $n$-dimensional activation space, cutting memory to $O(D\log_k C)$ while preserving $D$. LogHD uses a capacity-aware codebook and profile-based decoding, and composes with feature-axis sparsification. Across datasets and injected bit flips, LogHD attains competitive accuracy with smaller models and higher resilience at matched memory. Under equal memory, it sustains target accuracy at roughly $2.5$-$3.0\times$ higher bit-flip rates than feature-axis compression; an ASIC instantiation delivers $498\times$ energy efficiency and $62.6\times$ speedup over an AMD Ryzen 9 9950X and $24.3\times$/$6.58\times$ over an NVIDIA RTX 4090, and is $4.06\times$ more energy-efficient and $2.19\times$ faster than a feature-axis HDC ASIC baseline.
ORCA: Agentic Reasoning For Hallucination and Adversarial Robustness in Vision-Language Models
Sep 18, 2025



Large Vision-Language Models (LVLMs) exhibit strong multimodal capabilities but remain vulnerable to hallucinations from intrinsic errors and adversarial attacks from external exploitations, limiting their reliability in real-world applications. We present ORCA, an agentic reasoning framework that improves the factual accuracy and adversarial robustness of pretrained LVLMs through test-time structured inference reasoning with a suite of small vision models (less than 3B parameters). ORCA operates via an Observe--Reason--Critique--Act loop, querying multiple visual tools with evidential questions, validating cross-model inconsistencies, and refining predictions iteratively without access to model internals or retraining. ORCA also stores intermediate reasoning traces, which supports auditable decision-making. Though designed primarily to mitigate object-level hallucinations, ORCA also exhibits emergent adversarial robustness without requiring adversarial training or defense mechanisms. We evaluate ORCA across three settings: (1) clean images on hallucination benchmarks, (2) adversarially perturbed images without defense, and (3) adversarially perturbed images with defense applied. On the POPE hallucination benchmark, ORCA improves standalone LVLM performance by +3.64\% to +40.67\% across different subsets. Under adversarial perturbations on POPE, ORCA achieves an average accuracy gain of +20.11\% across LVLMs. When combined with defense techniques on adversarially perturbed AMBER images, ORCA further improves standalone LVLM performance, with gains ranging from +1.20\% to +48.00\% across evaluation metrics. These results demonstrate that ORCA offers a promising path toward building more reliable and robust multimodal systems.
TOGA: Temporally Grounded Open-Ended Video QA with Weak Supervision
Jun 11, 2025



We address the problem of video question answering (video QA) with temporal grounding in a weakly supervised setup, without any temporal annotations. Given a video and a question, we generate an open-ended answer grounded with the start and end time. For this task, we propose TOGA: a vision-language model for Temporally Grounded Open-Ended Video QA with Weak Supervision. We instruct-tune TOGA to jointly generate the answer and the temporal grounding. We operate in a weakly supervised setup where the temporal grounding annotations are not available. We generate pseudo labels for temporal grounding and ensure the validity of these labels by imposing a consistency constraint between the question of a grounding response and the response generated by a question referring to the same temporal segment. We notice that jointly generating the answers with the grounding improves performance on question answering as well as grounding. We evaluate TOGA on grounded QA and open-ended QA tasks. For grounded QA, we consider the NExT-GQA benchmark which is designed to evaluate weakly supervised grounded question answering. For open-ended QA, we consider the MSVD-QA and ActivityNet-QA benchmarks. We achieve state-of-the-art performance for both tasks on these benchmarks.
Neurosymbolic Artificial Intelligence for Robust Network Intrusion Detection: From Scratch to Transfer Learning
Jun 04, 2025Network Intrusion Detection Systems (NIDS) play a vital role in protecting digital infrastructures against increasingly sophisticated cyber threats. In this paper, we extend ODXU, a Neurosymbolic AI (NSAI) framework that integrates deep embedded clustering for feature extraction, symbolic reasoning using XGBoost, and comprehensive uncertainty quantification (UQ) to enhance robustness, interpretability, and generalization in NIDS. The extended ODXU incorporates score-based methods (e.g., Confidence Scoring, Shannon Entropy) and metamodel-based techniques, including SHAP values and Information Gain, to assess the reliability of predictions. Experimental results on the CIC-IDS-2017 dataset show that ODXU outperforms traditional neural models across six evaluation metrics, including classification accuracy and false omission rate. While transfer learning has seen widespread adoption in fields such as computer vision and natural language processing, its potential in cybersecurity has not been thoroughly explored. To bridge this gap, we develop a transfer learning strategy that enables the reuse of a pre-trained ODXU model on a different dataset. Our ablation study on ACI-IoT-2023 demonstrates that the optimal transfer configuration involves reusing the pre-trained autoencoder, retraining the clustering module, and fine-tuning the XGBoost classifier, and outperforms traditional neural models when trained with as few as 16,000 samples (approximately 50% of the training data). Additionally, results show that metamodel-based UQ methods consistently outperform score-based approaches on both datasets.