 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025



The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
VLC Fusion: Vision-Language Conditioned Sensor Fusion for Robust Object Detection
May 19, 2025



Although fusing multiple sensor modalities can enhance object detection performance, existing fusion approaches often overlook subtle variations in environmental conditions and sensor inputs. As a result, they struggle to adaptively weight each modality under such variations. To address this challenge, we introduce Vision-Language Conditioned Fusion (VLC Fusion), a novel fusion framework that leverages a Vision-Language Model (VLM) to condition the fusion process on nuanced environmental cues. By capturing high-level environmental context such as as darkness, rain, and camera blurring, the VLM guides the model to dynamically adjust modality weights based on the current scene. We evaluate VLC Fusion on real-world autonomous driving and military target detection datasets that include image, LIDAR, and mid-wave infrared modalities. Our experiments show that VLC Fusion consistently outperforms conventional fusion baselines, achieving improved detection accuracy in both seen and unseen scenarios.
Scalable Query Answering under Uncertainty to Neuroscientific Ontological Knowledge: The NeuroLang Approach
Feb 23, 2022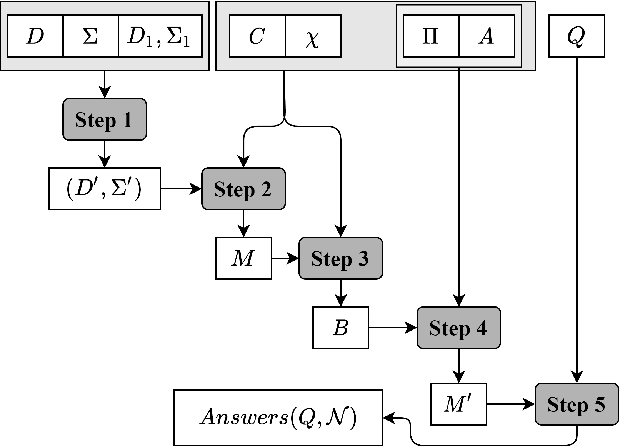
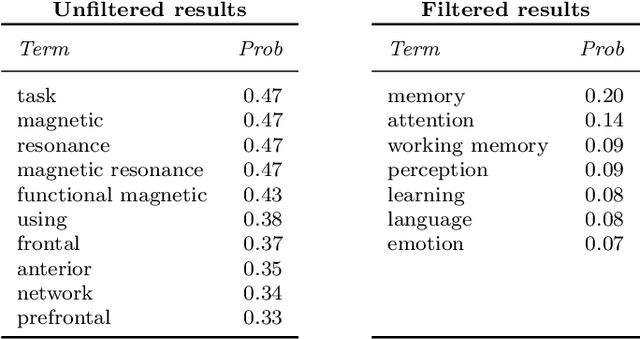
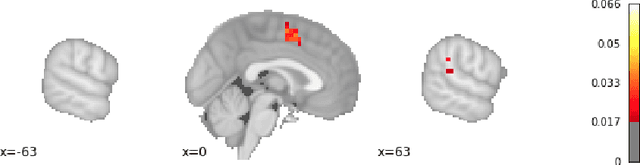
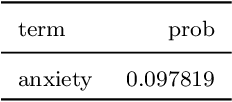
Researchers in neuroscience have a growing number of datasets available to study the brain, which is made possible by recent technological advances. Given the extent to which the brain has been studied, there is also available ontological knowledge encoding the current state of the art regarding its different areas, activation patterns, key words associated with studies, etc. Furthermore, there is an inherent uncertainty associated with brain scans arising from the mapping between voxels -- 3D pixels -- and actual points in different individual brains. Unfortunately, there is currently no unifying framework for accessing such collections of rich heterogeneous data under uncertainty, making it necessary for researchers to rely on ad hoc tools. In particular, one major weakness of current tools that attempt to address this kind of task is that only very limited propositional query languages have been developed. In this paper, we present NeuroLang, an ontology language with existential rules, probabilistic uncertainty, and built-in mechanisms to guarantee tractable query answering over very large datasets. After presenting the language and its general query answering architecture, we discuss real-world use cases showing how NeuroLang can be applied to practical scenarios for which current tools are inadequate.