 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorR: Towards Brain-Inspired Task-Oriented Reasoning via Cache-Oriented Algorithm-Architecture Co-design
Mar 24, 2026Task-oriented object detection (TOOD) atop CLIP offers open-vocabulary, prompt-driven semantics, yet dense per-window computation and heavy memory traffic hinder real-time, power-limited edge deployment. We present \emph{TorR}, a brain-inspired \textbf{algorithm--architecture co-design} that \textbf{replaces CLIP-style dense alignment with a hyperdimensional (HDC) associative reasoner} and turns temporal coherence into reuse. On the \emph{algorithm} side, TorR reformulates alignment as HDC similarity and graph composition, introducing \emph{partial-similarity reuse} via (i) query caching with per-class score accumulation, (ii) exact $δ$-updates when only a small set of hypervector bits change, and (iii) similarity/load-gated bypass under high system load. On the \emph{architecture} side, TorR instantiates a lane-scalable, bit-sliced item memory with bank/precision gating and a lightweight controller that schedules bypass/$δ$/full paths to meet RT-30/RT-60 targets as object counts vary. Synthesized in a TSMC 28\,nm process and exercised with a cycle-accurate simulator, TorR sustains real-time throughput with millijoule-scale energy per window ($\approx$50\,mJ at 60\,FPS; $\approx$113\,mJ at 30\,FPS) and low latency jitter, while delivering competitive AP@0.5 across five task prompts (mean 44.27\%) within a bounded margin to strong VLM baselines, but at orders-of-magnitude lower energy. The design exposes deployment-time configurability (effective dimension $D'$, thresholds, precision) to trade accuracy, latency, and energy for edge budgets.
ADAPT: Attention Driven Adaptive Prompt Scheduling and InTerpolating Orthogonal Complements for Rare Concepts Generation
Mar 19, 2026Generating rare compositional concepts in text-to-image synthesis remains a challenge for diffusion models, particularly for attributes that are uncommon in the training data. While recent approaches, such as R2F, address this challenge by utilizing LLM for prompt scheduling, they suffer from inherent variance due to the randomness of language models and suboptimal guidance from iterative text embedding switching. To address these problems, we propose the ADAPT framework, a training-free framework that deterministically plans and semantically aligns prompt schedules, providing consistent guidance to enhance the composition of rare concepts. By leveraging attention scores and orthogonal components, ADAPT significantly enhances compositional generation of rare concepts in the RareBench benchmark without additional training or fine-tuning. Through comprehensive experiments, we demonstrate that ADAPT achieves superior performance in RareBench and accurately reflects the semantic information of rare attributes, providing deterministic and precise control over the generation of rare compositions without compromising visual integrity.
Adaptive Auxiliary Prompt Blending for Target-Faithful Diffusion Generation
Mar 19, 2026Diffusion-based text-to-image (T2I) models have made remarkable progress in generating photorealistic and semantically rich images. However, when the target concepts lie in low-density regions of the training distribution, these models often produce semantically misaligned or structurally inconsistent results. This limitation arises from the long-tailed nature of text-image datasets, where rare concepts or editing instructions are underrepresented. To address this, we introduce Adaptive Auxiliary Prompt Blending (AAPB) - a unified framework that stabilizes the diffusion process in low-density regions. AAPB leverages auxiliary anchor prompts to provide semantic support in rare concept generation and structural support in image editing, ensuring faithful guidance toward the target prompt. Unlike prior heuristic prompt alternation methods, AAPB derives a closed-form adaptive coefficient that optimally balances the influence between the auxiliary anchor and the target prompt at each diffusion step. Grounded in Tweedie's identity, our formulation provides a principled and training-free framework for adaptive prompt blending, ensuring stable and target-faithful generation. We demonstrate the effectiveness of adaptive interpolation over fixed interpolation through controlled experiments and empirically show consistent improvements on the RareBench and FlowEdit datasets, achieving superior semantic accuracy and structural fidelity compared to prior training-free baselines.
Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning
Mar 12, 2026Existing retrieval-augmented approaches for Dense Video Captioning (DVC) often fail to achieve accurate temporal segmentation aligned with true event boundaries, as they rely on heuristic strategies that overlook ground truth event boundaries. The proposed framework, \textbf{STaRC}, overcomes this limitation by supervising frame-level saliency through a highlight detection module. Note that the highlight detection module is trained on binary labels derived directly from DVC ground truth annotations without the need for additional annotation. We also propose to utilize the saliency scores as a unified temporal signal that drives retrieval via saliency-guided segmentation and informs caption generation through explicit Saliency Prompts injected into the decoder. By enforcing saliency-constrained segmentation, our method produces temporally coherent segments that align closely with actual event transitions, leading to more accurate retrieval and contextually grounded caption generation. We conduct comprehensive evaluations on the YouCook2 and ViTT benchmarks, where STaRC achieves state-of-the-art performance across most of the metrics. Our code is available at https://github.com/ermitaju1/STaRC
Conditional neural control variates for variance reduction in Bayesian inverse problems
Feb 24, 2026Bayesian inference for inverse problems involves computing expectations under posterior distributions -- e.g., posterior means, variances, or predictive quantities -- typically via Monte Carlo (MC) estimation. When the quantity of interest varies significantly under the posterior, accurate estimates demand many samples -- a cost often prohibitive for partial differential equation-constrained problems. To address this challenge, we introduce conditional neural control variates, a modular method that learns amortized control variates from joint model-data samples to reduce the variance of MC estimators. To scale to high-dimensional problems, we leverage Stein's identity to design an architecture based on an ensemble of hierarchical coupling layers with tractable Jacobian trace computation. Training requires: (i) samples from the joint distribution of unknown parameters and observed data; and (ii) the posterior score function, which can be computed from physics-based likelihood evaluations, neural operator surrogates, or learned generative models such as conditional normalizing flows. Once trained, the control variates generalize across observations without retraining. We validate our approach on stylized and partial differential equation-constrained Darcy flow inverse problems, demonstrating substantial variance reduction, even when the analytical score is replaced by a learned surrogate.
$n$-Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models
Feb 09, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) shows that small, specialized language models (SLMs) can exhibit structured reasoning without relying on large monolithic LLMs. We introduce soft hidden-state collaboration, where multiple heterogeneous frozen SLM experts are integrated through their internal representations via a trainable attention interface. Experiments on Reasoning Gym and GSM8K show that this latent integration is competitive with strong single-model RLVR baselines. Ablations further reveal a dual mechanism of expert utilization: for simpler arithmetic domains, performance gains can largely be explained by static expert preferences, whereas more challenging settings induce increasingly concentrated and structured expert attention over training, indicating emergent specialization in how the router connects to relevant experts. Overall, hidden-state collaboration provides a compact mechanism for leveraging frozen experts, while offering an observational window into expert utilization patterns and their evolution under RLVR.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025



Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
T-SAR: A Full-Stack Co-design for CPU-Only Ternary LLM Inference via In-Place SIMD ALU Reorganization
Nov 17, 2025



Recent advances in LLMs have outpaced the computational and memory capacities of edge platforms that primarily employ CPUs, thereby challenging efficient and scalable deployment. While ternary quantization enables significant resource savings, existing CPU solutions rely heavily on memory-based lookup tables (LUTs) which limit scalability, and FPGA or GPU accelerators remain impractical for edge use. This paper presents T-SAR, the first framework to achieve scalable ternary LLM inference on CPUs by repurposing the SIMD register file for dynamic, in-register LUT generation with minimal hardware modifications. T-SAR eliminates memory bottlenecks and maximizes data-level parallelism, delivering 5.6-24.5x and 1.1-86.2x improvements in GEMM latency and GEMV throughput, respectively, with only 3.2% power and 1.4% area overheads in SIMD units. T-SAR achieves up to 2.5-4.9x the energy efficiency of an NVIDIA Jetson AGX Orin, establishing a practical approach for efficient LLM inference on edge platforms.
ASTER: Attention-based Spiking Transformer Engine for Event-driven Reasoning
Nov 10, 2025The integration of spiking neural networks (SNNs) with transformer-based architectures has opened new opportunities for bio-inspired low-power, event-driven visual reasoning on edge devices. However, the high temporal resolution and binary nature of spike-driven computation introduce architectural mismatches with conventional digital hardware (CPU/GPU). Prior neuromorphic and Processing-in-Memory (PIM) accelerators struggle with high sparsity and complex operations prevalent in such models. To address these challenges, we propose a memory-centric hardware accelerator tailored for spiking transformers, optimized for deployment in real-time event-driven frameworks such as classification with both static and event-based input frames. Our design leverages a hybrid analog-digital PIM architecture with input sparsity optimizations, and a custom-designed dataflow to minimize memory access overhead and maximize data reuse under spatiotemporal sparsity, for compute and memory-efficient end-to-end execution of spiking transformers. We subsequently propose inference-time software optimizations for layer skipping, and timestep reduction, leveraging Bayesian Optimization with surrogate modeling to perform robust, efficient co-exploration of the joint algorithmic-microarchitectural design spaces under tight computational budgets. Evaluated on both image(ImageNet) and event-based (CIFAR-10 DVS, DVSGesture) classification, the accelerator achieves up to ~467x and ~1.86x energy reduction compared to edge GPU (Jetson Orin Nano) and previous PIM accelerators for spiking transformers, while maintaining competitive task accuracy on ImageNet dataset. This work enables a new class of intelligent ubiquitous edge AI, built using spiking transformer acceleration for low-power, real-time visual processing at the extreme edge.
LogHD: Robust Compression of Hyperdimensional Classifiers via Logarithmic Class-Axis Reduction
Nov 06, 2025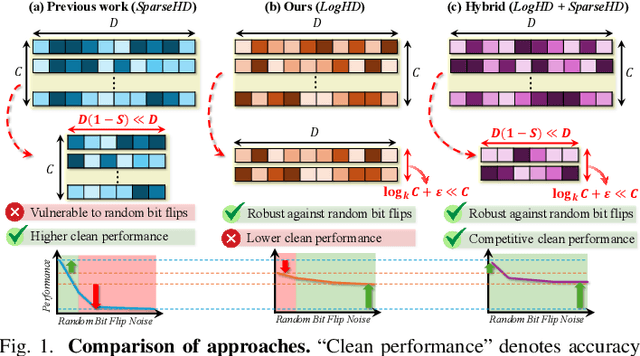
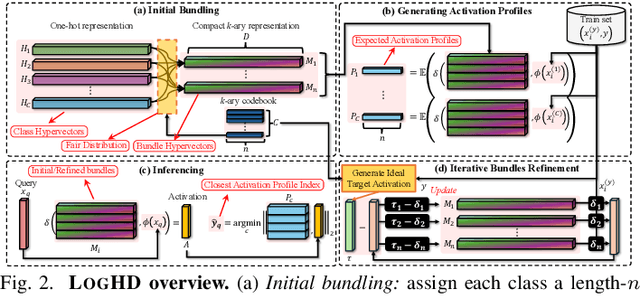
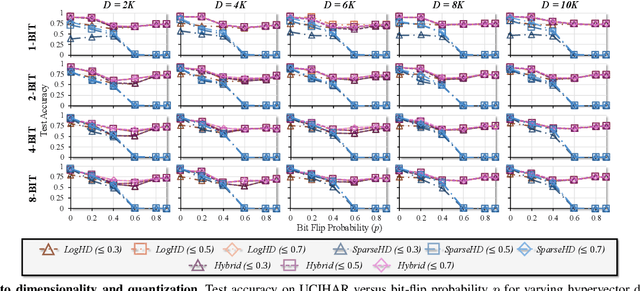
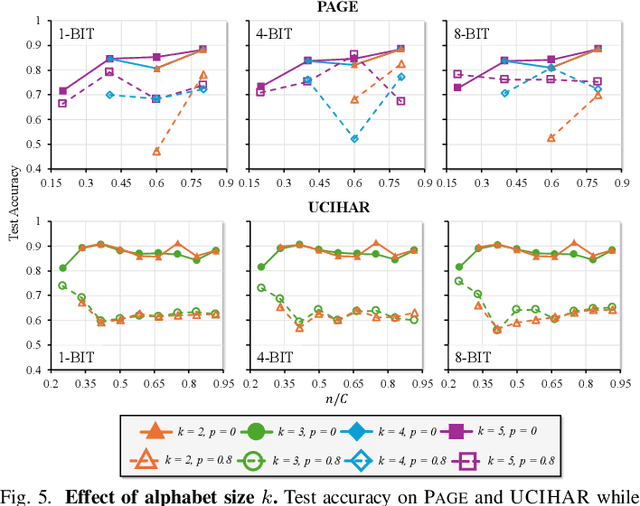
Hyperdimensional computing (HDC) suits memory, energy, and reliability-constrained systems, yet the standard "one prototype per class" design requires $O(CD)$ memory (with $C$ classes and dimensionality $D$). Prior compaction reduces $D$ (feature axis), improving storage/compute but weakening robustness. We introduce LogHD, a logarithmic class-axis reduction that replaces the $C$ per-class prototypes with $n\!\approx\!\lceil\log_k C\rceil$ bundle hypervectors (alphabet size $k$) and decodes in an $n$-dimensional activation space, cutting memory to $O(D\log_k C)$ while preserving $D$. LogHD uses a capacity-aware codebook and profile-based decoding, and composes with feature-axis sparsification. Across datasets and injected bit flips, LogHD attains competitive accuracy with smaller models and higher resilience at matched memory. Under equal memory, it sustains target accuracy at roughly $2.5$-$3.0\times$ higher bit-flip rates than feature-axis compression; an ASIC instantiation delivers $498\times$ energy efficiency and $62.6\times$ speedup over an AMD Ryzen 9 9950X and $24.3\times$/$6.58\times$ over an NVIDIA RTX 4090, and is $4.06\times$ more energy-efficient and $2.19\times$ faster than a feature-axis HDC ASIC baseline.